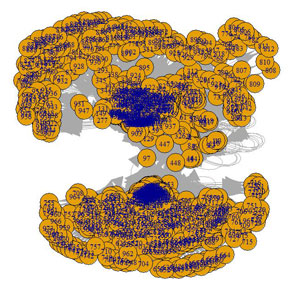
Cette méthode précédente avec Gephi, si elle permet de travailler finement sur un site, est toutefois chronophage. En effet vous devez à chaque fois utiliser un spider puis ensuite exporter et retraiter vos données avec Excel pour les rendre exploitables par Gephi.
L’idée est ici d’automatiser le processus, on fournit l’adresse d’un site au logiciel et il nous crée un graphe ! It’s magic !
Comme nous l’indiquions précédemment nous aurons besoin d’un crawler de pages Web ainsi qu’un outil de visualisation de graphes de réseaux. Cela tombe bien, dans R nous avons repéré la bibliothèque Rcrawler qui propose un crawler de site et la bibliothèque igraph qui permet de gérer des graphes de réseaux. Toutefois le programme Rcrawler ne correspond pas tout à fait à ce que nous recherchions et nous avons du le réécrire en partie afin de s’approcher au plus près de ce que nous avions précédemment avec Screaming Frog SEO Spider. Au total nous avons du modifier 3 fonctions de Rcrawler :
RobotParser : la fonction de lecture du fichier Robots.txt
LinkNormalization : la fonction de création de liens normalisés (sous la forme http|https://wwwdomaine.com/…)
Rcrawler : la fonction crawler elle même qui ne correspondait pas à nos besoins. Notamment elle ne renvoyait pas les code de redirections (301,302) que nous souhaitions. Par ailleurs on ne pouvait pas limiter le nombre de pages à parser.
Pour ne pas les confondre avec les fonctions originales nous leur avons adjoint un préfixe : « Network ». Dans notre cas elles se nommeront donc NetworkRobotParser, NetworkLinkNormalization et NetWorkRcrawler.
Code Source
Vous pouvez copier/coller les morceaux de codes source dans un script R pour les tester.
Environnement nécessaire à l’application à charger dans votre programme
#'
#'
#Packages à installer une fois.
#install.packages("Rcrawler")
#install.packages("igraph")
#install.packages("foreach")
#install.packages("doParallel")
#install.packages("data.table")
#install.packages("gdata")
#install.packages("xml2")
#install.packages("httr")
#Bibliothèques à charger.
library(Rcrawler) #Notamment pour Linkparamsfilter...
library(doParallel) #Notamment pour parallel::makeCluster
library(data.table) #Notamment pour %like% %in% ...
library(igraph) #Notamment graph.data.frame() ...
library(xml2) #Notamment pour read_html
library(httr) #pour GET, content ...
NetworkRobotParser
NetworkRobotParser modifie le programme RobotParser de base de Rcrawler qui générait des erreurs. NetworkRobotParser est appelé par NetworkRcrawler.
#' NetworkRobotParser modifie RobotParser qui générait une erreur d'encoding on rajoute MyEncod.
#' RobotParser fetch and parse robots.txt
#'
#' This function fetch and parse robots.txt file of the website which is specified in the first argument and return the list of correspending rules .
#' @param website character, url of the website which rules have to be extracted .
#' @param useragent character, the useragent of the crawler
#' @return
#' return a list of three elements, the first is a character vector of Disallowed directories, the third is a Boolean value which is TRUE if the user agent of the crawler is blocked.
#' @import httr
#' @export
#'
#' @examples
#'
#' RobotParser("http://www.glofile.com","AgentX")
#' #Return robot.txt rules and check whether AgentX is blocked or not.
#'
#'
NetworkRobotParser
NetworkLinkNormalization
NetworkLinkNormalization modifie le programme original LinkNormalization. Notamment le programme ne dédoublonne pas les liens. En effet nous avons considéré que ce dédoublonnement était un choix qui devait être fait au niveau du traitement du graphe et non pas au niveau de la collecte des liens. Par ailleurs, nous avons corrigé quelque bugs. NetworkLinkNormalization est appelé par NetworkRcrawler.
#'
#'
#' NetworkLinkNormalization :modification de LinkNormalization :
#' on ne renvoie pas des liens uniques mais multiples : le dédoublonnement des liens doit se faire lors de
#' l'étude du réseau avec igraph.
#' correction aussi pour les liens avec # et mailto:, callto: et tel: qui étaient renvoyés.
#'
#' A function that take a URL _charachter_ as input, and transforms it into a canonical form.
#' @param links character, the URL to Normalize.
#' @param current character, The URL of the current page source of the link.
#' @return
#' return the simhash as a nmeric value
#' @author salim khalilc corrigé par Pierre Rouarch
#' @details
#' This funcion call an external java class
#' @export
#'
#' @examples
#'
#' # Normalize a set of links
#'
#' links 0)<2) { #Si un seul http
# remove spaces
if(grepl("^\\s|\\s+$",links[t])) {
links[t]
NetworkRcrawler
NetworkRcrawler modifie substantiellement le programme Rcrawler. Notamment pour la lecture des Urls nous avons utilisé directement la fonction GET() du package httr et non pas la fonction spécifique LinkExtractor utilisée par la version de base. GET() permet de récupérer plus d’infos sur les headers. Les extractions de contenus ont été supprimés car il ne nous semblait pas que ce soit à ce stade que l’on devait traiter ce sujet. Le contenu des pages est passé via la data.frame NetwNodes dans la variable HTMLContent. Le programme passe les informations de liens et de noeuds au travers des data.frames NetwEdges et NetwNodes.
#' NetworkRcrawler (modification de Rcrawler par Pierre Rouarch pour limiter le nombre de page crawlées et éviter
#' une attente trop longue) :
#' NetworkRcrawler a pour objectif de créer un réseau de pages de site exploitable par iGraph
#'
#' Version 1.0
#'
#' #' Modification vs Rcrawler :
#' Ajout du paramètre MaxPagesParsed pour limiter les pages "parsées" et y passer la nuit
#' Ajout du Paramètres IndexErrPages pour récupérér des pages avec status autre que 200
#' On utilise GET() plutôt que LinkExtractor car LinkExtractor ne nous renvoyait pas les infos voulues
#' notamment les redirections.
#' Récupération du contenu de la page dans pkg.env$GraphNodes plutôt que passer par des fichiers externes
#' La valeur de pkg.env$GraphEdges$Weight est à 1 et non pas à la valeur du level de la page comme précédemment.
#'
#'
#' Simplification vs Rcrawler :
#' Suppression de l'enregistrement des fichiers *.html pour gagner en performance
#' Nous avons aussi supprimer les paramètres d'extraction qui ne nous semblent pas pertinents à ce
#' stade : Comme le contenu est passé à travers de NetwNodes$Content les extractions de contenus
#' peuvent(doivent?) se faire en dehors de la construction du Réseau de pages à proprement parlé.
#'
#' Paramètres conservés vs Rcrawler
#' @param Website character, the root URL of the website to crawl and scrape.
#' @param no_cores integer, specify the number of clusters (logical cpu) for parallel crawling, by default it's the numbers of available cores.
#' @param no_conn integer, it's the number of concurrent connections per one core, by default it takes the same value of no_cores.
#' @param MaxDepth integer, repsents the max deph level for the crawler, this is not the file depth in a directory structure, but 1+ number of links between this document and root document, default to 10.
#' @param RequestsDelay integer, The time interval between each round of parallel http requests, in seconds used to avoid overload the website server. default to 0.
#' @param Obeyrobots boolean, if TRUE, the crawler will parse the website\'s robots.txt file and obey its rules allowed and disallowed directories.
#' @param Useragent character, the User-Agent HTTP header that is supplied with any HTTP requests made by this function.it is important to simulate different browser's user-agent to continue crawling without getting banned.
#' @param Encod character, set the website caharacter encoding, by default the crawler will automatically detect the website defined character encoding.
#' @param Timeout integer, the maximum request time, the number of seconds to wait for a response until giving up, in order to prevent wasting time waiting for responses from slow servers or huge pages, default to 5 sec.
#' @param URLlenlimit integer, the maximum URL length limit to crawl, to avoid spider traps; default to 255.
#' @param urlExtfilter character's vector, by default the crawler avoid irrelevant files for data scraping such us xml,js,css,pdf,zip ...etc, it's not recommanded to change the default value until you can provide all the list of filetypes to be escaped.
#' @param ignoreUrlParams character's vector, the list of Url paremeter to be ignored during crawling .
#' @param NetwExtLinks boolean, If TRUE external hyperlinks (outlinks) also will be counted on Network edges and nodes.
#' Paramètre ajouté
#' @param MaxPagesParsed integer, Maximum de pages à Parser (Ajout PR)
#'
#'
#'
#' @return
#'
#' The crawling and scraping process may take a long time to finish, therefore, to avoid data loss
#' in the case that a function crashes or stopped in the middle of action, some important data are
#' exported at every iteration to R global environment:
#'
#' - NetwNodes : Dataframe with alls hyperlinks and parameters of pages founded.
#' - NetwEdges : data.frame representing edges of the network, with these column : From, To, Weight (1) and Type (1 for internal hyperlinks 2 for external hyperlinks).
#'
#' @details
#'
#' To start NetworkRcrawler (or Rcrawler) task you need the provide the root URL of the website you want to scrape, it can
#' be a domain, a subdomain or a website section (eg. http://www.domain.com, http://sub.domain.com or
#' http://www.domain.com/section/). The crawler then will go through all its internal links.
#' The process of a crawling is performed by several concurrent processes or nodes in parallel,
#' So, It is recommended to use R 64-bit version.
#'
#' For more tutorials about RCrawler check https://github.com/salimk/Rcrawler/
#'
#' For scraping complexe character content such as arabic execute Sys.setlocale("LC_CTYPE","Arabic_Saudi Arabia.1256") then set the encoding of the web page in Rcrawler function.
#'
#' If you want to learn more about web scraper/crawler architecture, functional properties and implementation using R language, Follow this link and download the published paper for free .
#'
#' Link: http://www.sciencedirect.com/science/article/pii/S2352711017300110
#'
#' Dont forget to cite Rcrawler paper:
#' Khalil, S., & Fakir, M. (2017). RCrawler: An R package for parallel web crawling and scraping. SoftwareX, 6, 98-106.
#'
#' @examples
#'
#' \dontrun{
#' NetworkRcrawler(Website ="http://www.example.com/", no_cores = 4, no_conn = 4)
#' #Crawl, index, and store web pages using 4 cores and 4 parallel requests
#' NetworkRcrawler(Website = "http://www.example.com/", no_cores=8, no_conn=8, Obeyrobots = TRUE,
#' Useragent="Mozilla 3.11")
#' # Crawl and index the website using 8 cores and 8 parallel requests with respect to
#' # robot.txt rules.
#'
#' NetworkRcrawler(Website = "http://www.example.com/" , no_cores = 4, no_conn = 4, MaxPagesParsed=50)
#' # Crawl the website using 4 cores and 4 parallel requests until the number of parsed pages reach 50
#'
#' # Using Igraph for exmaple you can plot the network by the following commands
#' library(igraph)
#' network Contenu html de la page
#PR ajout pkg.env$GraphNodes (contient les pages parsées, crawlées et non crawlées, internes et externes)
pkg.env$GraphNodes=LevelOut && TotalPagesParsed <= MaxPagesParsed && pkg.env$GraphNodes[t+s-1, "PageType"]==1) { #Récupérer des liens
pkg.env$GraphNodes[t+s-1, "MyStatusPage"] =LevelOut && TotalPagesParsed <= MaxPagesParsed && pkg.env$GraphNodes[t+s-1, "PageType"]==1)
} #/if (is.null(allGetResponse[[s]]$status_code))
} #/if (!is.null(allGetResponse[[s]]))
} #/for (s in 1:length(allGetResponse))
cat("Crawl with GET :",format(round((t/nrow(pkg.env$GraphNodes)*100), 2),nsmall = 2),"% : ",t,"to",l,"crawled from ",nrow(pkg.env$GraphNodes)," Parsed:", TotalPagesParsed-1, "\n")
t
Appel de NetworkRcrawler
Voilà nous pouvons maintenant faire appel à la fonction NetworkRcrawler. Profitons en pour tester notre site https://www.anakeyn.com. Nous limitons le nombre de pages à parser à 500 et nous ne nous intéressons qu’aux liens internes. La fonction renvoie 2 data.frames : NetwEdges pour les liens entre les pages et NetwNodes pour les noeuds ou pages.
IntermediateHttpStat peut contenir des codes de redirections 301,302…
création du Réseau pour igraph
Le réseau est construit à partir du data.frame de liens NetwEdges
#'
#'
#Création du Réseau pour igraph
network
Graphe au hasard
Cette vue est sans spatialisation
#'
#'
#Vue générale au hasard.
plot.igraph(x = network, layout=layout.random)
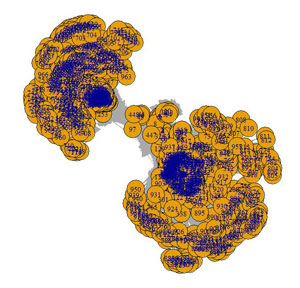
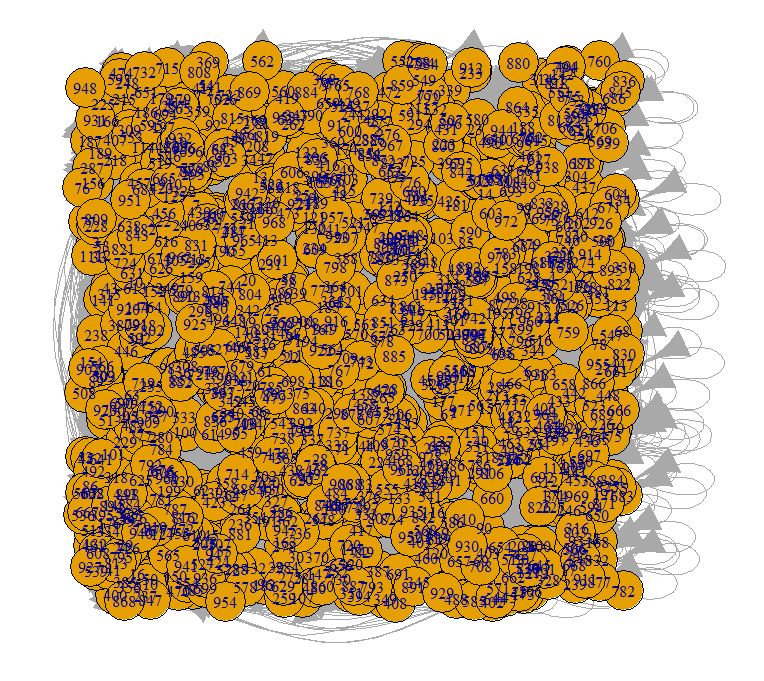
Comme on l’a vu précédemment dans la création de graphe avec Gephi, la vue générale sans spatialisation se présente sous la forme d’un gros carré. Nous avons ici 973 pages.
#'
#'
#Nouvelles vues générales sans boucles au hasard et spatialisation de base.
plot.igraph(x = network, layout=layout.random)
plot.igraph(x = network)
Au hasard :
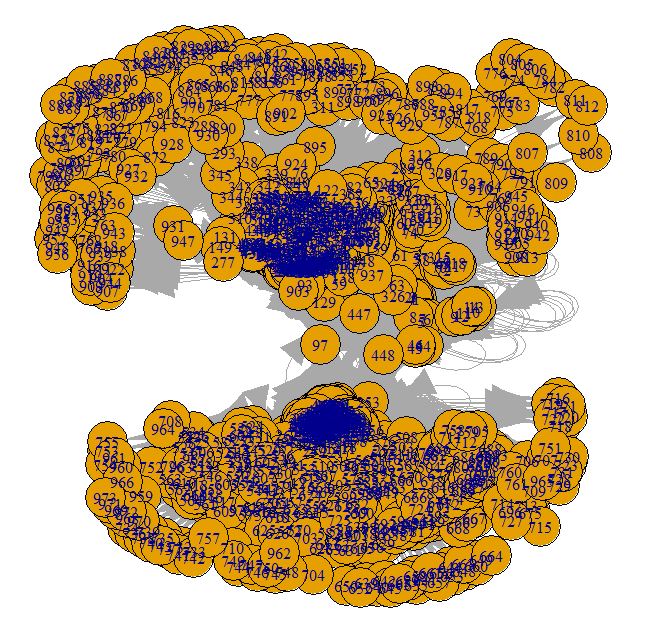
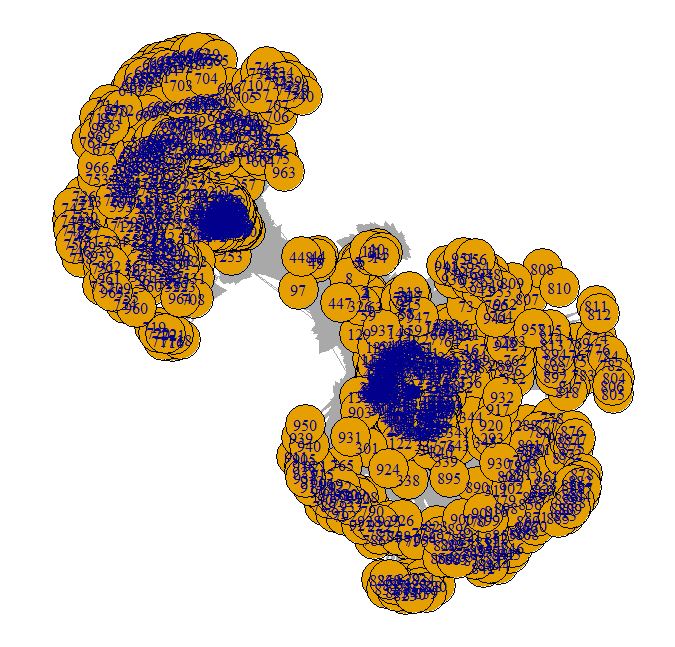
Spatialisation de base :
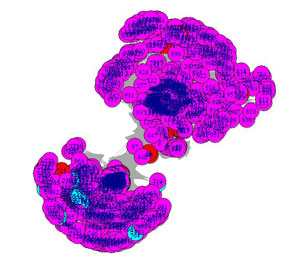
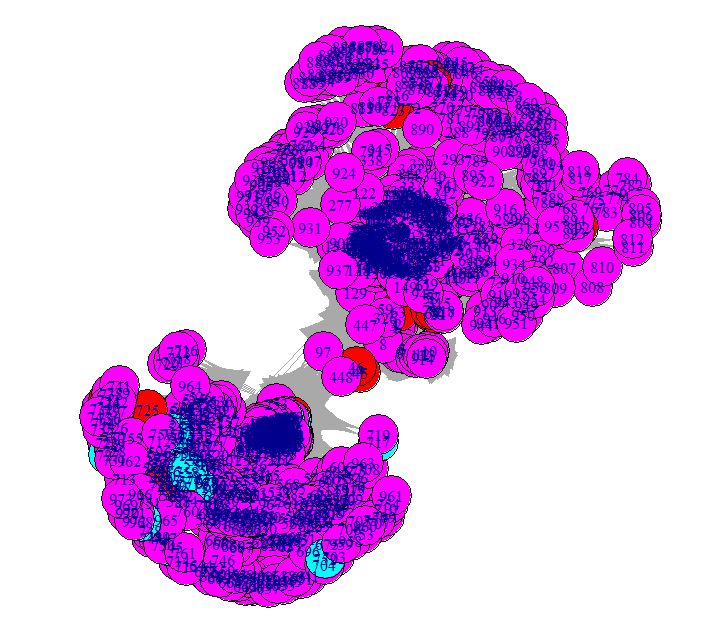
Graphes colorisation en fonction du statut http
on n’utilisera le statut IntermediateHttpStat de NetwNodes qui permet d’indentifier les redirections. On a créé une petite fonction pour mapper les couleurs en fonctions des status.
#'
#'
######################################################
# Fonction de mapping couleurs des status
######################################################
mapColorByHTTPStatus
Au hasard :
Spatialisation de base :
De nombreuses pages posent problèmes avec des status 30x et 40x
Identification des pages != 200
#'
#'
#Mise en évidence des pages qui posent problème.
NetwNodes[!(NetwNodes$IntermediateHttpStat==200),c(2, 8)]
Comme dans Gephi la bibliothèque igraph de R permet de calculer un Page Rank des pages dans le réseau. Ici le réseau est dirigé. Ce Page Rank sera ensuite utilisé pour mettre en évidence les pages qui reçoivent le plus de « jus » de liens.
#'
#'
#Calcul du page Rank
pr
Construction de labels
Afin de ne pas surcharger les graphes on peut essayer de construire des « fichiers » de labels qui n’afficheront que certaines pages.
#'
#'
#Construction de labels à partir des meilleurs pagerank
NewIndex 1) NewIndexLevel01[i, 1]
Fonction de mapping pour la taille des noeuds
Cette fonction est utile pour afficher des tailles de noeuds en fonctions de groupes de valeurs.
#'
#'
###############################################################
#Map function for nodes sizes
map range[2]) x max(range)]
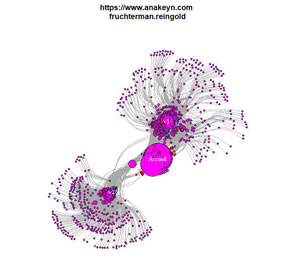
Graphe avec spatialisation Fruchterman Reingold
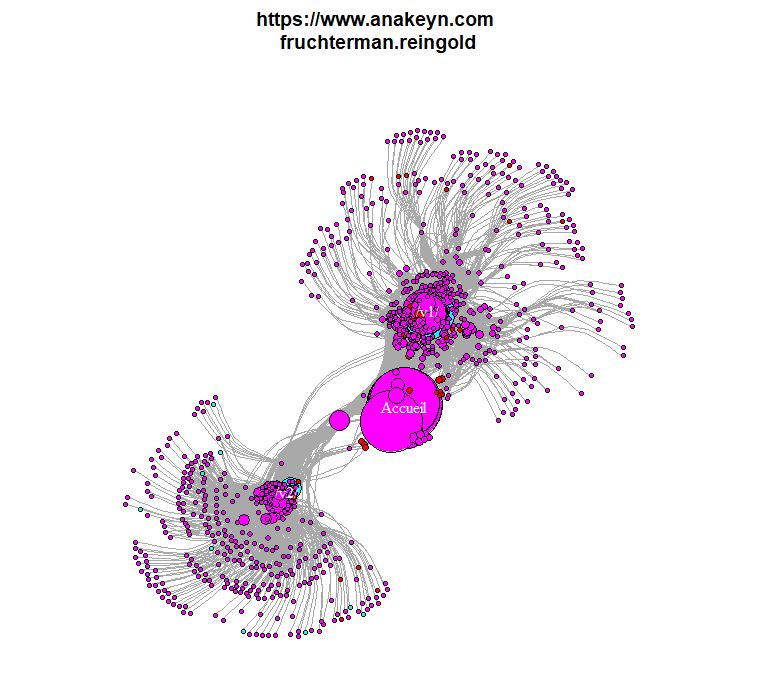
Comme avec Gephi nous allons appliquer une spatialisation Fruchterman Reingold à notre réseau.
#'
#'
#############################################################
# Graphe avec spatialisation Fruchterman Reingold
#Préparation du layout Fruchterman Reingold
lwithfr
Merci de votre attention,
Pierre.
Si vous avez des remarques et ou des suggestions d’amélioration du code source à faire, n’hésitez pas à utiliser les commentaires.
Partager la publication "Créer un graphe de site Web avec R"