


Partager la publication "Machine Learning sur des données Yooda avec Dataiku DSS 6.0 (partie 1)"
Dans cet article, nous allons voir comment utiliser différents algorithmes de Machine Learning avec Dataiku DSS 6.0.
Afin d’avoir un élément de comparaison nous allons utiliser les mêmes données que dans notre article Recherche de facteurs SEO avec le Machine Learning (partie 1) ou nous avions fait nos calcul avec R.
Les données sont dans la thématique des cosmétiques bio.
Dans cet article précédent nous avions notamment récupéré des données Pages/Mots-clés/Position au moyen de l’API de Yooda Insight (qui semble arrêtée depuis ??) .
Nous avions ensuite enrichi ces données par des variables qui nous ont servies de variables explicatives à savoir :
- kwindomain : compte l’occurrence du mot clé dans le domaine.
- kwinurl : compte l’occurrence du mot clé dans le reste de l’url.
- ishttps : est-ce une url en https ?
- isSSLEV : le SSL est-il de type Extended Value ?
- urlnchar : nombre de caractères dans l’url.
- urlslashcount : nombre de / dans l’url (pseudo « level »)
Récupération du jeu de données
Le jeu de données est récupérable sur notre GitHub dans le « repository » que nous avions fait à l’époque pour présenter notre code source R. Téléchargez AllDataKeyords.zip et dézippez le dans un répertoire.
Dataiku Data Science Studio
Pour installer Dataiku DSS 6.0 reportez-vous à notre article précédent sur son installation et sa prise en main.
Rappel :
Pour démarrer Dataiku dans Linux : DATA_DIR/bin/dss start
Pour se rendre sur Dataiku avec son Navigateur (Chrome ou Firefox) allez à l’adresse : http://:11000. Souvent (et pour moi) http://127.0.0.1:11000.
Démarrons le test
En premier lieu nous allons créer un nouveau projet :
Choisissez un projet à vide « blank project » et indiquez un nom.
Importation des données depuis la page du projet :
Commencez par importer le fichier AllDataKeywords.csv -> Choisissez le connecteur « Files » -> « Upload your files »
Une fois vérifié que tout est ok au niveau de la prévisualisation, cliquez sur « Create ». Normalement l’importation doit correctement se passer. C’est assez rapide malgré les 154979 enregistrements.
Allez ensuite sur le « flow » : cliquez sur l’image en forme de « > » et choisissez « Flow » :
Nous allons maintenant « nettoyer » notre jeu de données pour ne conserver que les données intéressante pour notre Machine Learning. Pour cela nous allons utiliser une recette « prepare » (image de balai)
Préparation des données
Le système nous demande un nom de sortie pour le Dataset :
Puis l’outil de préparation s’affiche :
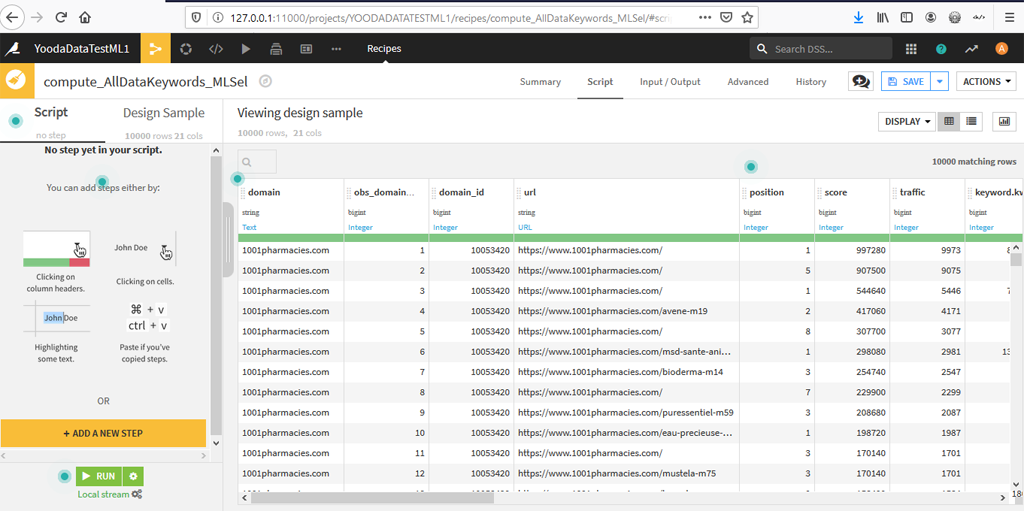
A gauche vous avez le script de « nettoyage » qui s’affichera au fur et à mesure des étapes, à droite les données. Dans notre cas, c’est assez simple, car il suffit de supprimer les données qui ne nous intéressent pas.
On conservera comme données à expliquer istop3pos (dans le top 3) et les caractéristiques que l’on a vues précédemment : kwindomain, kwinurl, ishttps, isSSLEV, urlnchar, urlslashcount :
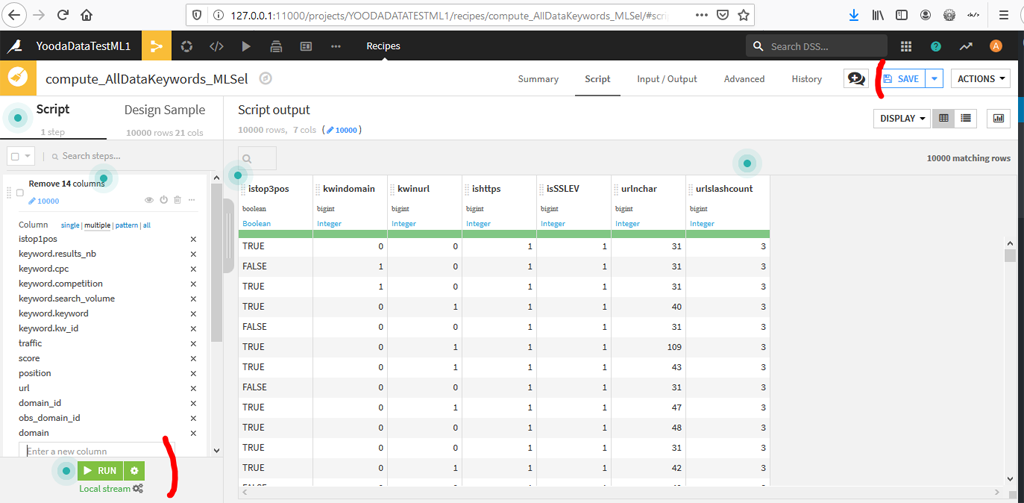
Cliquez sur « Run » pour démarrer la transformation. Validez le warning. Cela prend un certain temps. Vérifiez que vous avez un message « Job succeeded ».
Si tout est ok, retournez au « flow » et cliquez sur le nouveau Dataset pour avoir le menu sur la droite.
Dans le menu de Droite cliquez sur l’icône « Lab »
Laboratoire
Le laboratoire de Dataiku DSS est l’outil pour analyser plus avant vos données, il propose 2 méthodes :
- L’analyse visuelle à partir d’outils prédéfinis
- L’analyse sous forme de Notebooks ou vous pourrez notamment modifier et ajouter du Code Source
On s’intéressera pour l »instant à l’analyse visuelle et particulièrement à l’option « Quick Model ».
Quick Model propose ensuite « Prediction » ou « Clustering » :
Nous sommes bien dans un problème d’apprentissage supervisé ou nous voulons prédire la position d’une page Web sur un mot-clé en fonction de caractéristiques connues.
Choisissez « Prediction »
Variable à expliquer
Après le choix de la variable cible ou variable à expliquer (pour nous istop3pos) le système nous propose soit des modèles prédéfinis soit le mode expert.
On prendra le mode expert :
Ensuite vous avez encore le choix entre différentes options :
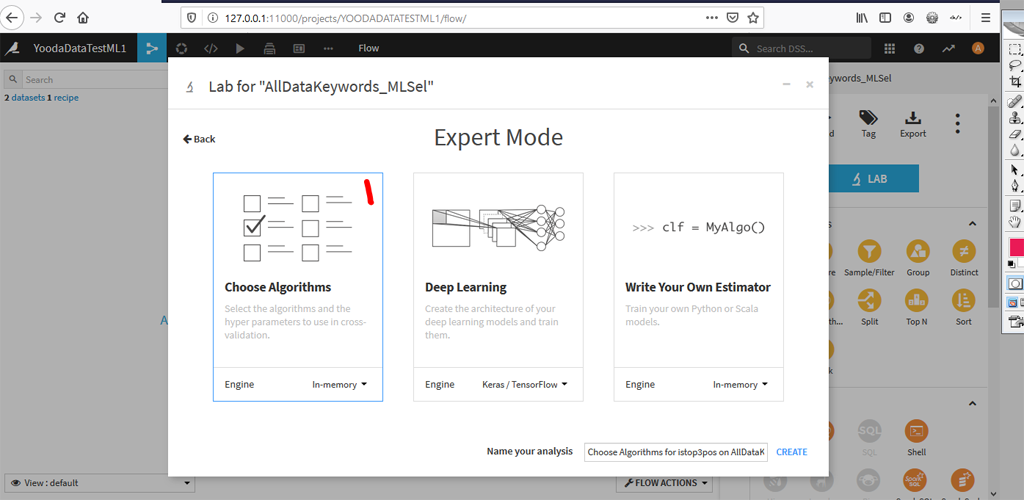
Choisissez « Choose Algorithms » -> « in-memory » -> « in-memory » puis « Create ». Vous arrivez sur la page par défaut de Design des algorithmes.
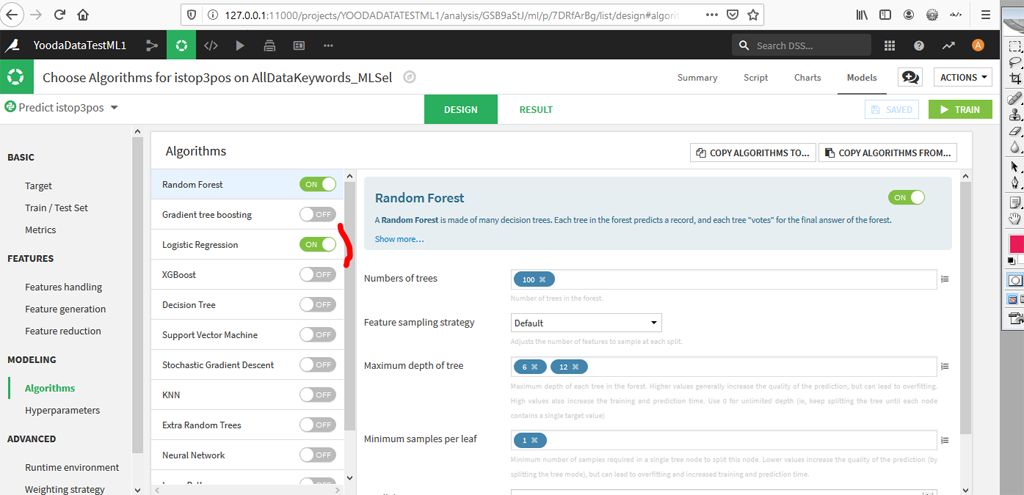
Décochez « Random Forest » et gardez uniquement « Logistic Regression ».
Paramètres pour les sets d’entrainement et de test
Allez dans la rubrique « Train / Test Set » pour définir comment utiliser le dataset :
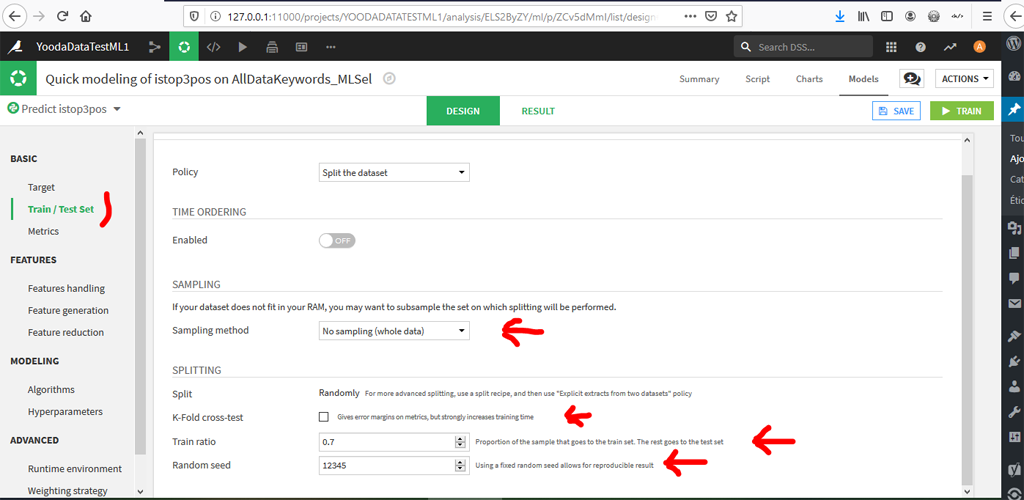
Changer les paramètres pour avoir les mêmes que nous avions utilisés précédemment avec R à savoir :
- Pas d’échantillonnage : on travaille sur toutes les données
- Pas de K-Fold : nous ne l’avions pas utilisé avec R.
- Train Ratio à 0,7 au lieu de 0,8 proposé par défaut.
- Random Seed « 12345 » au lieu de « 1337 »
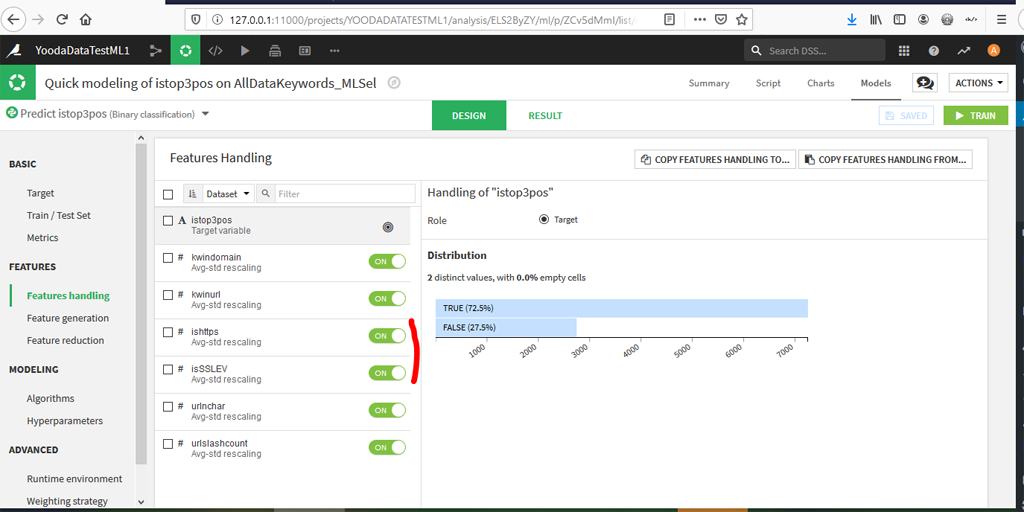
Vérifions les caractéristiques dans « Features Handling » :
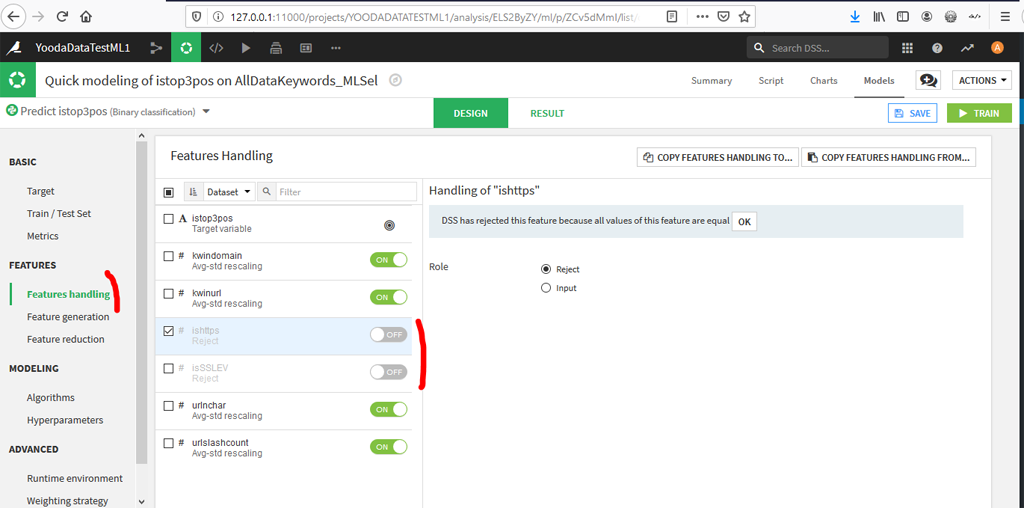
2 variables ishttps et isSSLEV sont rejetées par défaut car leurs contenus sont les mêmes pour tous les enregistrements, ce qui n’apporte pas à priori d’information.
Toutefois, nous allons les garder car nous ne les avions pas retirées lors de notre test avec R.
Régression Logistique
Rappel, on prend ici un seul algorithme, à savoir « Logistic Regression ». Retournez dans la rubrique « algorithms » :
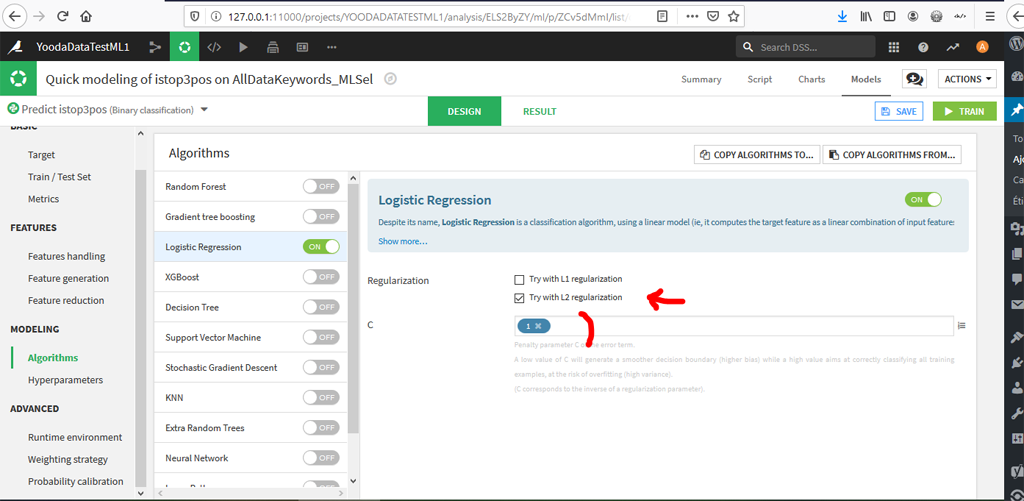
Le système nous oblige à choisir une régularisation, on choisira L2 (par défaut).
Lors de notre test avec R nous avions utilisé la fonction glm du package stats de R sans régularisation. De ce fait, il est possible que l’on ait des résultats différents.
Pour faire simple la régularisation L2 est utilisée pour éviter le sur apprentissage et va pénaliser les poids des valeurs « aberrantes » (ou outliers)
Le paramètre C ne sera testé que sur la valeur 1 car nous ne l’avons pas utilisé non plus avec R. Le paramètre C est l’inverse de la régularisation, avec une valeur à 1 son action est ici neutre.
Entrainement du modèle Régression Logistique
Les résultats globaux sont les suivants :
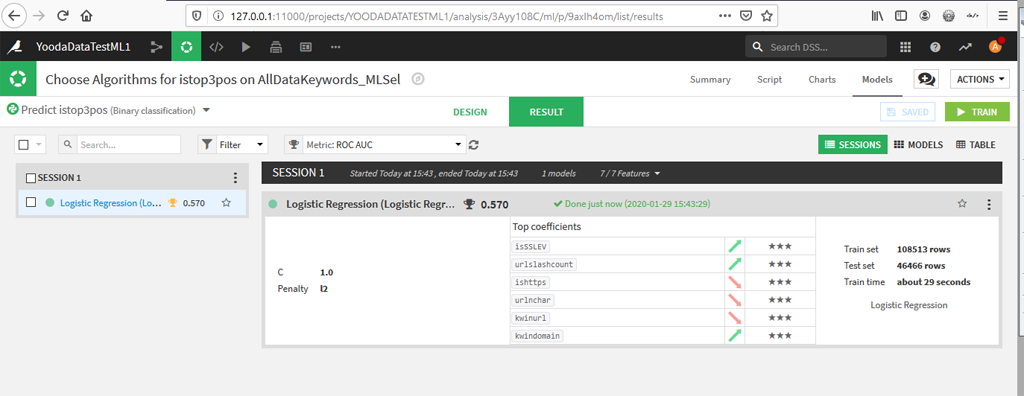
Le calcul de l’AUC à 0,57 est proche de ce que nous avions eu avec R 0,57248 (mais ce n’est pas terrible).
Le calcul de l’importance des variables est dans le même ordre que ce que nous avions eu avec R :
isSSLEV 31.505129
urlslashcount 30.126572
ishttps 22.949776
urlnchar 18.391328
kwinurl 11.435329
kwindomain 4.370518
Pour info l’Accuracy (exactitude) sur les valeurs de test est d’à peine 0,5172, ce qui indique que le modèle est mauvais.
Rapport Complet pour la Régression Logistique
En cliquant à droite sur le lien dans la session (ici Logistic Regression) vous accéder au rapport complet :
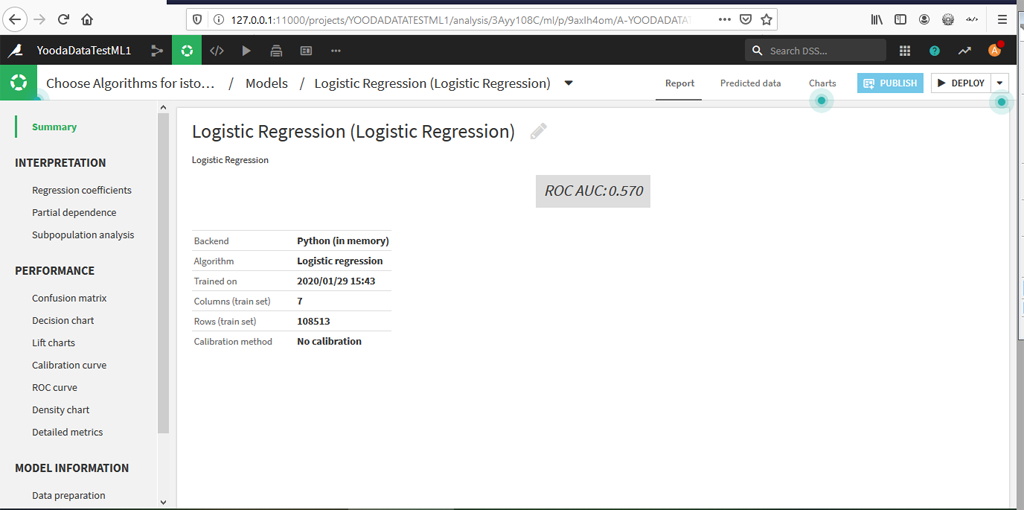
Ce rapport propose différents outils et 2 autres onglets Predicted Data et Charts. N’hésitez pas à tester les différents outils.
Par exemple la courbe ROC
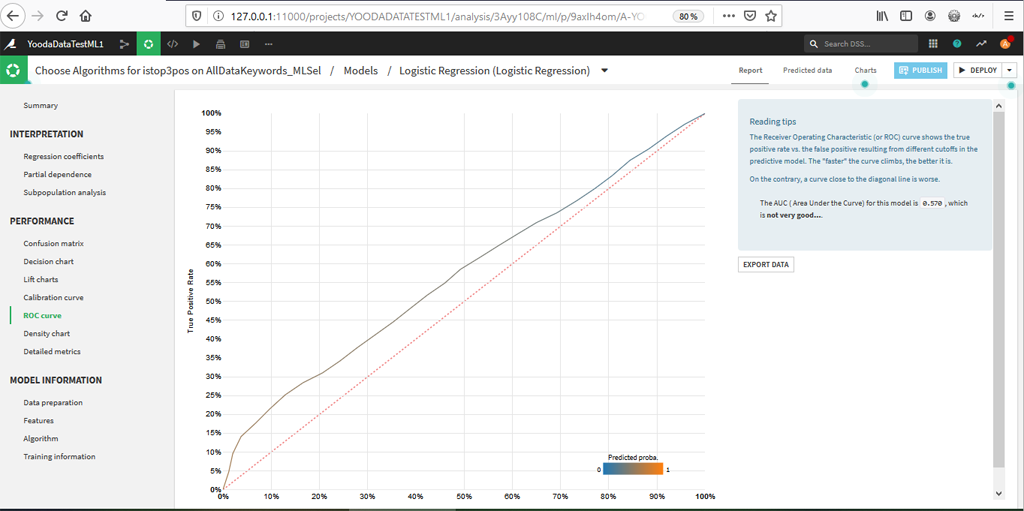
Le système nous confirme que la valeur d’AUC à 0,57 n’est pas terrible.
Onglet Predicted Data POUR REGRESSION LOGISTIQUE
Dans cet onglet on a toutes les statistiques de prédiction pour chaque observation du set de test.
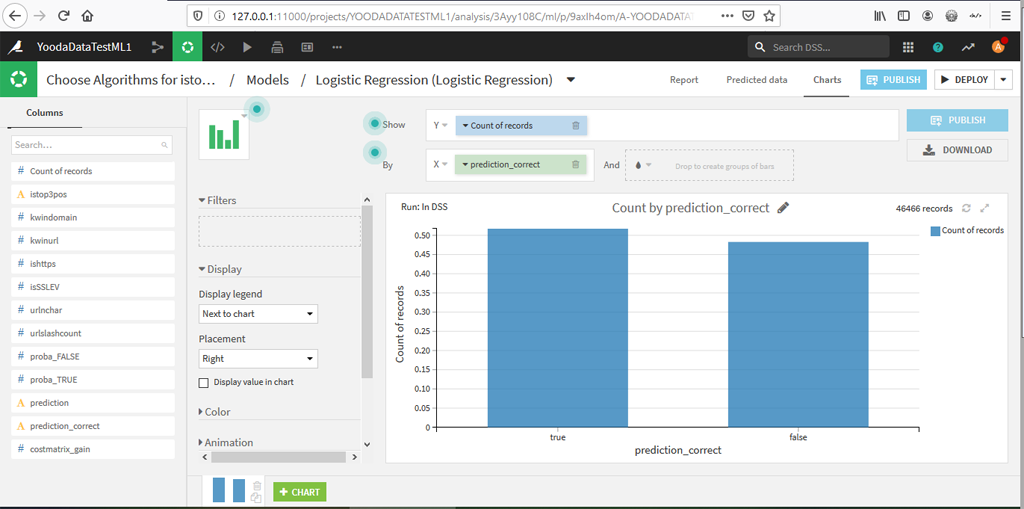
Onglet Charts POUR REGRESSION LOGISTIQUE
On retrouve l’onglet Charts sur les données du set de test avec les prédictions
Par exemple ici on a calculé le pourcentage de prédictions correctes (pas terrible)
Dans notre article Recherche de facteurs SEO avec le Machine Learning (partie 1) nous avions utilisé le modèle Naïve Bayes. Celui-ci n’étant pas disponible par défaut dans la version gratuite, nous allons poursuivre par Random Forest
Forêts Aléatoires : Random Forest Classifier
Vérifions les valeurs par défaut que nous avons avec la fonction randomForest de R : nous avions pour le nombre d’arbres 500, pour la taille du nœud terminal (ou feuille) = 1, pour la profondeur de l’arbre ce paramètre n’est pas défini donc on prendra 0, pour la stratégie d’échantillonnage des caractéristiques on reste du la méthode par défaut qui correspond à la racine carrée du nombre de caractéristiques.
Reportons ces données sur les paramètres de l’algorithme Random Forest :
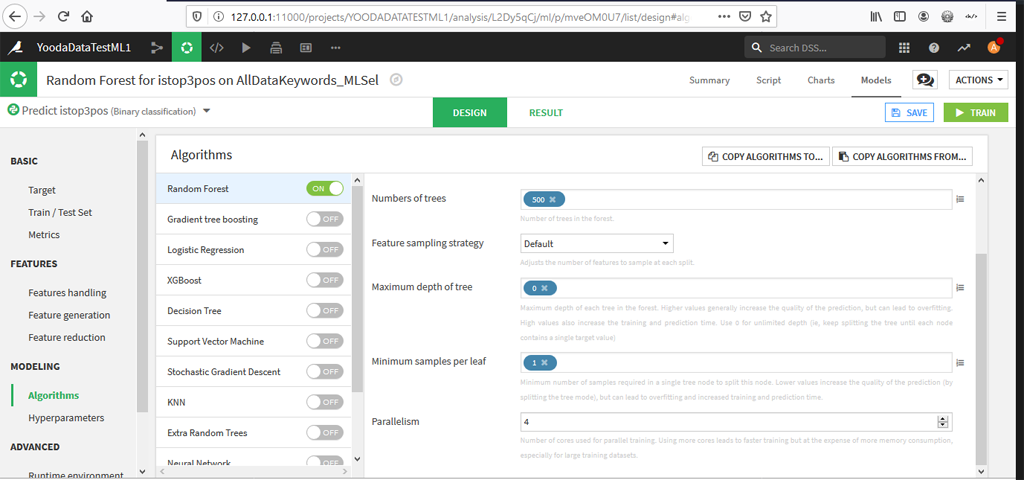
Vérifiez dans « Train / Test Set » on a bien les paramètres précédents : à savoir l’utilisation de toutes les données (pas d’échantillonnage) un train ration à 0,7 et un seed « 12345 ».
Vérifiez aussi que toutes les caractéristiques sont utilisées ( » Features Handling ») comme précédemment et dans notre test avec R.
Résultats avec Random Forest
Lancez le train : les résultats globaux sont les suivants :
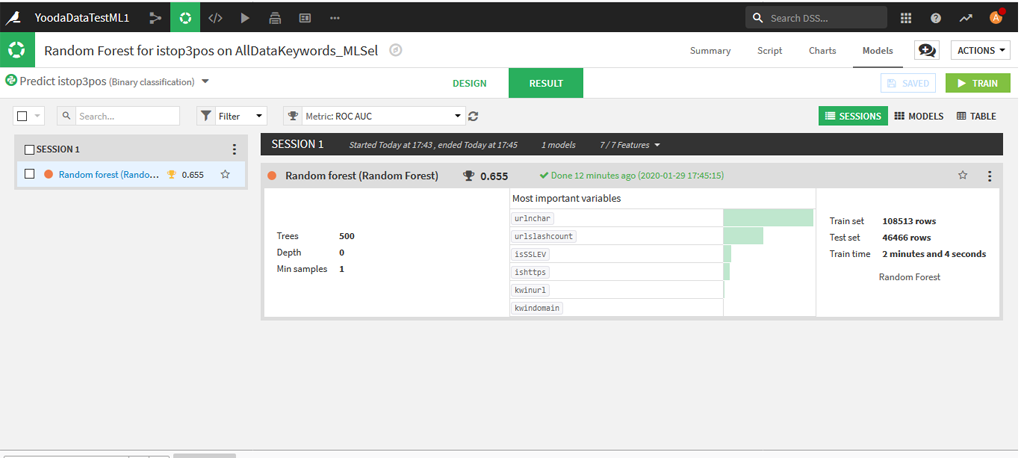
La valeur de l’AUC est bien meilleure que ce que l’on avait eu avec R, ici 0,655 contre 0,584.
Par ailleurs l’ordre d’importance des variables ne semble pas le même ici : la variable avec le plus d’importance est urlnchar alors qu’avec R nous avions urlslashcount.
Allons voir la Courbe Roc :
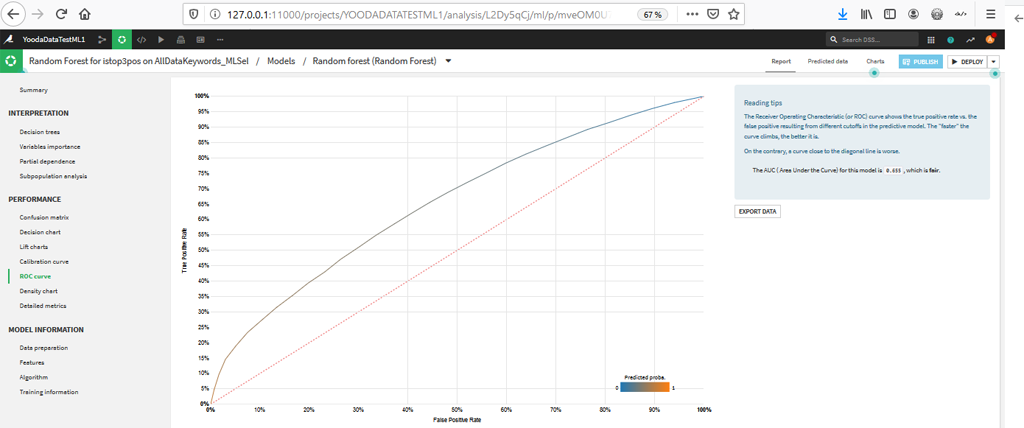
La courbe Roc est plus sympathique que précédemment, par ailleurs le système considère que l’AUC à 0,655 est un résultat correct.
L’exactitude de la prédiction (Accuracy) reste toutefois faible 0,557.
XGBoost
On prendra, si possible les mêmes paramètres que ceux que l’on avait précédemment avec R :
- nfold = 5
- eta (learning rate)= 0,3
- max depth = 6
- Early Stopping Round = 10
Et pour les autres paramètres les paramètres par défaut de XGBoost.
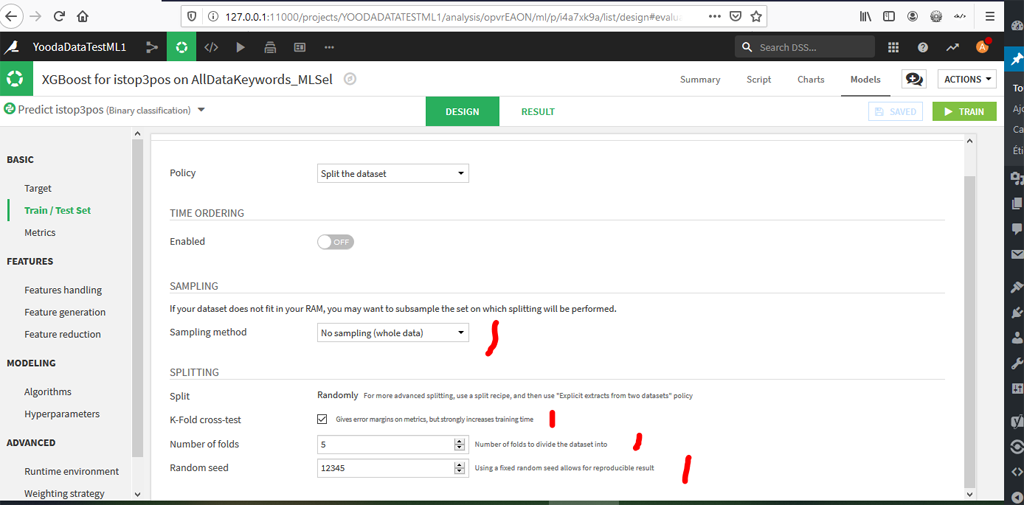
Paramétrage du Train / Test Set pour XGBoost
Ici on va paramétrer les K-fold=5, on choisit l’ensemble des données et on remet le random seed à 12345.
Paramétrage Features Handling POUR XGBoost
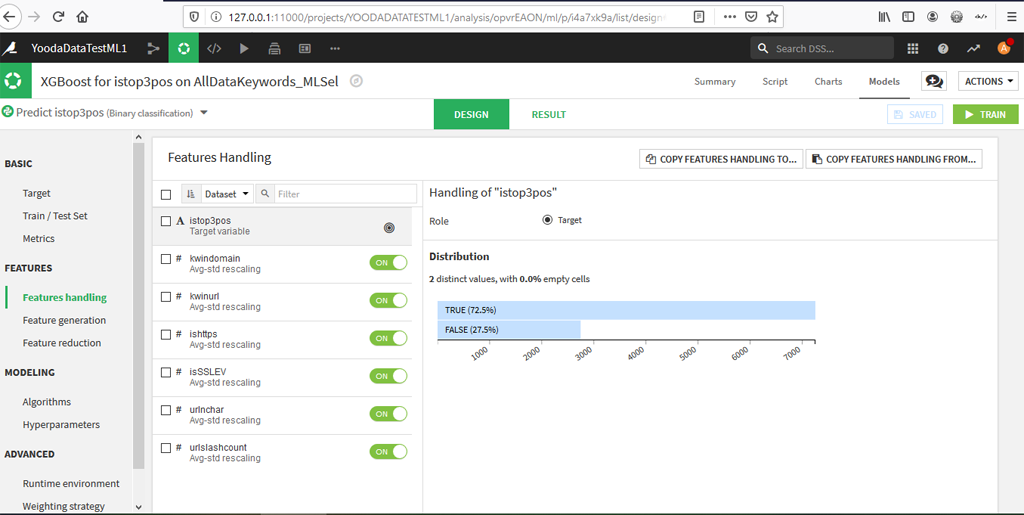
On vérifie ensuite que l’on utilise toutes les caractéristiques -> Features Handling.
Paramétrage Algorithme XGBOOST
Paramètres de l’algorithme (comme indiqué précédemment) pour se rapprocher de ce que nous avions défini avec R :
Résultats Globaux XGBoost
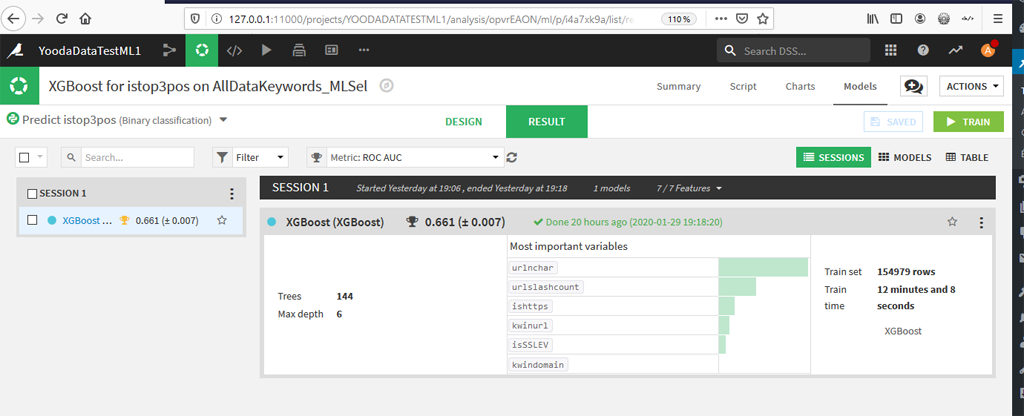
Le calcul de l’AUC donne 0,661, soit équivalent à ce que l’on avait trouvé avec R.
L’ordre de l’importance des variables est aussi le même, à savoir : urlnchar, urlslashcount, ishttps, kwinurl, isSSLEV, kwindomain.
Bien que meilleure que précédemment avec Random Forest, l’accuracy (l’exactitude) sur les données de test est faible : 0,5725.
La conclusion avec Dataiku sur ces données est la même que celle que l’on avait faite avec R : le modèle manque de variables et nous devons l’enrichir.
L’avantage toutefois avec Dataiku, est que cette étude s’est faite très rapidement par rapport à une étude programmée avec R.
A Bientôt,
Pierre