


Partager la publication "Comparaison de similarités syntaxiques avec Jaccard, Dice, TF-IDF et BM25 en Python"
Dans cet article nous verrons comment effectuer des tests de similarités syntaxiques de documents en utilisant différentes méthodes : test de Jaccard, test de Dice, TF-IDF et BM25. Puis nous comparerons certains résultats « à la main ».
Rappelons que la similarité syntaxique se base sur la comparaison de chaines de caractères dans des documents.
Par exemple les phrases « je mange » et je mangerai » peuvent être considérées comme similaires. La mesure de similarité est obtenue par un calcul (algorithme).
La similarité sémantique de documents ou de termes se base sur la ressemblance de leurs significations. Par exemple « je dîne » et « je soupe » sont sémantiquement proches.
Pour l’expliquer simplement, la similarité sémantique fait appel à des modèles contenant des termes ou des documents ressemblants. Ainsi dans l’exemple précédent ou pourra faire appel à un modèle qui nous indique que les verbes « manger », « dîner » et « souper » sont proches.
Nous aborderons dans d’autres articles des méthodes de similarités sémantiques.
Algorithmes sélectionnés :
Comme indiqué précédemment, nous allons utiliser 4 algorithmes courants pour résoudre notre problème :
Indice de Jaccard
l’indice de Jaccard ou coefficient de Jaccard est le rapport entre la taille des termes communs de 2 documents sur la taille de l’union des 2 documents :


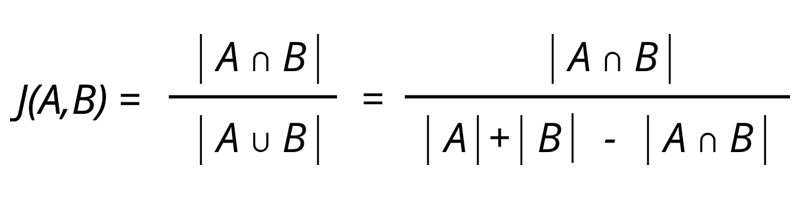
Indice de Dice
L’indice de Dice ou de Sørensen-Dice est proche de l’indice de Jaccard. Dans cette formule, l’intersection est privilégiée par rapport à l’union (on rajoute une intersection au numérateur et au dénominateur) :


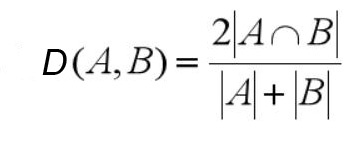
Similarité Cosinus et TF-IDF



La similarité cosinus est souvent utilisée pour mesurer la similarité de documents.
Pour cela on va dans un premier temps vectoriser les documents sous forme de vecteurs de mots.
Puis ensuite on va remplacer ces mots par des valeurs numériques (car sinon on ne pourrait pas effectuer de calcul).
Cette valeur numérique est souvent du type TF-IDF (term frequency–inverse document frequency) car cela permet de calculer l’importance d’un mot dans le document vs l’ensemble des documents.


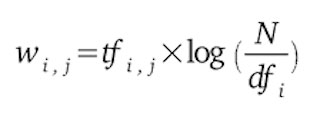
Rem : Nous avons déjà utilisé TF-IDF pour d’autres usages notamment pour notre outil de suggestion de mots clés.
Ensuite pour chaque couple de vecteurs (de documents) on effectue le calcul A · B / ||A|| ||B|| . C’est à dire le produit scalaire des deux vecteurs divisé par le produits des normes des 2 vecteurs.
Comme le TF-IDF crée des vecteurs dont les normes sont égales à 1, le cosinus sera donc égal uniquement au produit scalaire des 2 vecteurs.
Dans les faits les calculs sont effectués en une ligne dans le programme en effectuant le produit matriciel de la matrice de tous les documents (vectorisés en TF-IDF) avec sa transposée :
TFIDF_Scores=np.dot(tfidf_vectors,tfidf_vectors.T).toarray()Score BM25
BM25 ou Okapi BM25 est une autre méthode de pondération un peu plus sophistiquée que TF-IDF. Pour calculer le score d’un document D par rapport à un ensemble de termes Q (q1, …., qn) la formule est la suivante :


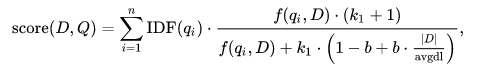
- f(qi, D) est la fréquence du terme qi dans le document D,
- |D| est la longueur du document D en nombre de mots,
- avgdl est la longueur moyenne des documents dans la collection (ou corpus),
- k1 et un paramètre d’optimisation généralement situé entre 1,2 et 2. Dans notre cas nous avons pris la moyenne i.e : 1.6,
- b est un autre paramètre généralement fixé à 0,75,
- IDF(qi) est la fréquence inverse de document déterminée par le calcul suivant :


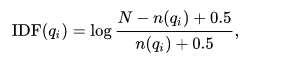
- N est le nombre de documents dans la collection ou corpus,
- n(qi) est le nombre de documents contenant le terme qi.
De quoi aurons nous besoin ?
Python anaconda
Comme d’habitude, nous conseillons l’utilisation de Python Anaconda pour nos scripts.
En effet, cette version de Python contient de nombreuses bibliothèques préinstallées que nous utilisons pour les sciences de données comme Scikit-Learn, Pandas, Numpy, NLTK (Natural Language Toolkit)…


Vous pouvez télécharger la dernière version d’Anaconda à l’adresse : https://www.anaconda.com/products/individual
Anaconda propose différents outils dont un environnement de développement intégré (Spyder) que nous utilisons pour tester les programmes.


S’il vous manque des bibliothèques, utilisez la console « Anaconda Prompt » pour en installer. Attention ! pour installer des bibliothèques avec Anaconda l’outil s’appelle « conda » et non pas « pip » ou « pip3 » dans d’autres versions de Python.
Dans notre cas, nous aurons besoin de télécharger la bibliothèque spaCy qui est une alternative à NLTK pour le traitement du langage naturel.
Nous aurons aussi besoin ainsi d’un modèle pour le traitement du Français pour effectuer la lemmatisation (nous reviendrons sur ce sujet) de nos textes.
conda install -c conda-forge spacy
python -m spacy download fr_core_news_mdFichier de documents
Pour illustrer notre propos nous sommes parti d’un fichier d’entreprises « CompaniesFrenchDesc.xlsx ».



Ce fichier contient 2 colonnes qui nous intéressent : « Name » et « Description ». Le champ Description contient en fait le contenu de la balise description sur la page d’accueil du site Web de l’entreprise.
Nous avons utilisé HubSpot pour récupérer ce champ, mais vous pourriez tout aussi bien utiliser un outil de scraping comme ScreamingFrog pour récupérer ces données.
L’ensemble des descriptions des entreprises correspond à notre corpus de documents. Notre propos est ici de trouver les entreprises avec les descriptions les plus similaires selon les différents algorithmes et d’examiner nos résultats de visu.
Vous pouvez récupérer ce fichier de données ainsi que le code source du programme en entier dans notre boutique à l’adresse : https://www.anakeyn.com/boutique/produit/script-python-jaccard-dice-tfidf-bm25/
Vous pouvez bien sûr créer votre propre fichier qui devra contenir au moins les champs « Name » et « Description ».
Notez ici que notre corpus est en français et non pas en anglais comme souvent dans les articles de mes confrères. Ceci nécessite parfois quelques traitements particuliers.
Code Source
Vous pourrez soit récupérer les codes sources par morceaux dans les extraits suivants, soit comme indiqué précédemment dans notre boutique en cliquant sur le lien suivant : https://www.anakeyn.com/boutique/produit/script-python-jaccard-dice-tfidf-bm25/
Chargement des bibliothèques usuelles
On retrouve ces bibliothèques dans de nombreux projets de sciences de données et de Traitement Automatique du Langage (TAL) ou en anglais Natural Language Processing (NLP).
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 3 10:32:15 2021
@author: Pierre
"""
#import needed librarie
import pandas as pd #for dataframes
import numpy as np #for arrays
#import nltk stopwords
from nltk.corpus import stopwords #nltk (Natural Language ToolKit) normaly comes With Anaconda
#import stopwords in french
stopWords = set(stopwords.words('french'))
import re #for regular expressions
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer #for vectorization
Lemmatisation
La lemmatisation consiste à donner à un mot sa forme neutre canonique que l’on trouve dans un dictionnaire : par exemple, l’infinitif pour les verbes ou le singulier pour les noms.
Exemple : chevaux => cheval et chevauche => chevaucher
A ne pas confondre avec la racinisation ou désuffixation (en anglais stemming) qui consiste à supprimer des « affixes » (suffixes, préfixes, infixes, circonfixes) des mots. Les résultats ne sont pas forcément des mots existants.
Exemple : chevaux, chevauche => cheva
La bibliothèque NLTK ne fournissant pas de lemmatisation en français (à ma connaissance) nous allons utiliser la bibliothèque spaCy.
#needed for lemmatization
#Install it before in Anaconda console :
#conda install -c conda-forge spacy
#python -m spacy download fr_core_news_md
import spacy #nltk alternative. Lemmatization in French is not available with nltk
nlp = spacy.load('fr_core_news_md') #Spacy pre-train model in French
def SpacyLemmatizer(doc):
myDoc = nlp(doc)
myLemmatizeDoc = " ".join([token.lemma_ for token in myDoc])
print(myLemmatizeDoc)
return myLemmatizeDoc
Chargement et nettoyage des données
Dans notre cas, nous allons charger un fichier de stopwords (mots interdits qui apportent peu d’information comme le, la, les, à …) pour le français. Nous allons aussi conserver les accents. Enfin, nous allons procéder à la lemmatisation des données.
Le but est aussi de diminuer la taille des documents en nombre de mots.
#################################################
# Loading and Cleaning Data
#################################################
#Read my company file (french version)
dfCompaniesFrenchDesc = pd.read_excel("CompaniesFrenchDesc.xlsx")
dfCompaniesFrenchDesc.dtypes
dfCompanies=pd.DataFrame(dfCompaniesFrenchDesc,columns=['Name', 'Description'])
#dfCompanies.rename(columns={"Description": "Description"}, inplace=True)
# removing special characters and stop words from the text
stop_words_l=stopwords.words('french')
#Keep numbers and accents but remove stop words
dfCompanies['Description_Cleaned']=dfCompanies.Description.apply(lambda x: " ".join(re.sub(r'[^a-zA-Z0-9À-ÖØ-öø-ÿœ]',' ',w).lower() for w in x.split() if re.sub(r'[^a-zA-Z0-9À-ÖØ-öø-ÿœ]',' ',w).lower() not in stopWords) )
#lemmatize
dfCompanies['Description_Cleaned'] = dfCompanies.Description_Cleaned.apply(lambda x: SpacyLemmatizer(x) )
#Check
#dfCompanies.Description_Cleaned.shape
Outils de vectorisation
On transforme les données (l’ensemble des textes nettoyés) en vecteurs numériques selon les besoins et les algorithmes choisis.
Pour Jackard et Dice nous utilisons CountVectorizer de Scikit Learn. Les vecteurs contiennent des 0 ou des 1 selon que le mot est dans le document ou non.
Pour TF-IDF nous utilisons TfidfVectorizer, toujours par Scikit Learn. Les vecteurs contiennent les valeurs de TF-IDF pour les mots contenus dans le document.
Pour BM25 nous avons trouvé une classe sur GitHub : https://gist.github.com/koreyou/f3a8a0470d32aa56b32f198f49a9f2b8
################## instantiate the Count vectorizer object (for jaccard and Dice)
countvectoriser = CountVectorizer()
count_vectors = countvectoriser.fit_transform(dfCompanies.Description_Cleaned)
#transform sparse matrix in array
count_vectors_array = count_vectors.toarray()
#Checks :
#count_vectors_array.shape #number of documents / number of words
#np.unique(count_vectors_array[0], return_counts=True) #What we get in the first document : x words found, y not found
############ instantiate the TF-IDF vectorizer object
tfidfvectoriser=TfidfVectorizer()
tfidfvectoriser.fit(dfCompanies.Description_Cleaned) #Fit tfidfvectoriser
#Calculate TF-IDF sparse matrix
tfidf_vectors=tfidfvectoriser.transform(dfCompanies.Description_Cleaned)
#Checks (Norm calculation)
#tfidf_vectors_array = tfidf_vectors.toarray()
#np.linalg.norm(tfidf_vectors_array[0]) # = 1
############ instantiate the BM25 vectorizer object
########################## BM25 implementation by Koreyou
#see here https://gist.github.com/koreyou/f3a8a0470d32aa56b32f198f49a9f2b8
""" Implementation of OKapi BM25 with sklearn's TfidfVectorizer
Distributed as CC-0 (https://creativecommons.org/publicdomain/zero/1.0/)
"""
#import numpy as np #already done
#from sklearn.feature_extraction.text import TfidfVectorizer #already done
from scipy import sparse
class BM25(object):
def __init__(self, b=0.75, k1=1.6):
self.vectorizer = TfidfVectorizer(norm=None, smooth_idf=False)
self.b = b
self.k1 = k1
def fit(self, X):
""" Fit IDF to documents X """
self.vectorizer.fit(X)
y = super(TfidfVectorizer, self.vectorizer).transform(X)
self.avdl = y.sum(1).mean()
def transform(self, q, X):
""" Calculate BM25 between query q and documents X """
b, k1, avdl = self.b, self.k1, self.avdl
# apply CountVectorizer
X = super(TfidfVectorizer, self.vectorizer).transform(X)
len_X = X.sum(1).A1
q, = super(TfidfVectorizer, self.vectorizer).transform([q])
assert sparse.isspmatrix_csr(q)
# convert to csc for better column slicing
X = X.tocsc()[:, q.indices]
denom = X + (k1 * (1 - b + b * len_X / avdl))[:, None]
# idf(t) = log [ n / df(t) ] + 1 in sklearn, so it need to be coneverted
# to idf(t) = log [ n / df(t) ] with minus 1
idf = self.vectorizer._tfidf.idf_[None, q.indices] - 1.
numer = X.multiply(np.broadcast_to(idf, X.shape)) * (k1 + 1)
return (numer / denom).sum(1).A1
bm25vectoriser=BM25()
bm25vectoriser.fit(dfCompanies.Description_Cleaned) #Fit bm25vectoriser
#no need of a matrix to calculate BM25 Scores (scores provided in the class)
Calculs des scores Jaccard, Dice, TF-IDF, BM25
Nous allons aussi créer les outils de calcul de scores.
Pour Jaccard et Dice nous avons créé à la main des fonctions pour calculer les scores
Comme on l’a vu précédemment, pour TF-IDF, nous calculons les scores en une fois en effectuant le produit matriciel de la matrice des vecteurs des documents avec sa transposée.
Le calcul pour BM25 s’effectue directement dans la classe avec la fonction « transform ».
############## Scores Calculators
#Jaccard Scores Manually
def Jaccard_Scores(myArray, i) :
JaccardScores = np.zeros([myArray.shape[0]]) #myArray.shape[0]
for j in range(0, myArray.shape[0]):
CountArray1 = myArray[i].sum()
CountArray2 = myArray[j].sum()
Intersection = sum(myArray[i]*myArray[j])
JaccardScores[j] = float(Intersection/(CountArray1+CountArray2 - Intersection))
return JaccardScores
#Dice Scores Manually
def Dice_Scores(myArray, i) :
DiceScores = np.zeros([myArray.shape[0]]) #myArray.shape[0]
for j in range(0, myArray.shape[0]):
CountArray1 = myArray[i].sum()
CountArray2 = myArray[j].sum()
Intersection = sum(myArray[i]*myArray[j])
DiceScores[j] = float(2*Intersection/(CountArray1+CountArray2))
return DiceScores
#For TFIDF (cosine similarity)
#all similarity scores for TFIDF are calculated using the dot product of array and array.T
#np.dot Dot product of Two arrays : dot(a, b)[i,j,k,m] = sum(a[i,j,:] * b[k,:,m])
TFIDF_Scores=np.dot(tfidf_vectors,tfidf_vectors.T).toarray()
#TFIDF_Scores.shape
#For BM25
#Already Implemented in the BM25 class -> transform
#Calculate BM25 scores (example with 0 to others)
BM25_Scores0=bm25vectoriser.transform(dfCompanies.Description_Cleaned[0], dfCompanies.Description_Cleaned)
Récupération des résultats dans une dataframe
Ensuite, pour chaque document, On va récupérer les documents les plus similaires selon les 4 algorithmes précédents. Puis on stocke les résultats dans une dataframe (pandas).
################################################
# create dataframe for the Results : dfResults
################################################
column_names = ["Index",
"Name",
"Description",
"Description_Cleaned",
"Jaccard_Index",
"Jaccard_Name",
"Jaccard_Description",
"Jaccard_Description_Cleaned",
"Jaccard_Score",
"Dice_Index",
"Dice_Name",
"Dice_Description",
"Dice_Description_Cleaned",
"Dice_Score",
"TFIDF_Index",
"TFIDF_Name",
"TFIDF_Description",
"TFIDF_Description_Cleaned",
"TFIDF_Score",
"BM25_Index",
"BM25_Name",
"BM25_Description",
"BM25_Description_Cleaned",
"BM25_Score"]
dfResults = pd.DataFrame(columns = column_names) #All Results
MaxSize = dfCompanies.shape[0] #1329
#MaxSize = 100 #if it's too long or to test different values.
for i in range(0,MaxSize):
print("i:",i)
#Compare i to others
###### Jaccard Sore
#Create Current dataframe containing my jaccard_Scores for row i
dfCurrent_Jaccard_Scores=pd.DataFrame(Jaccard_Scores(count_vectors_array,i), columns=['Jaccard_Score'])
#index in column
dfCurrent_Jaccard_Scores['Jaccard_Index']=dfCurrent_Jaccard_Scores.index
#Remove the current row
dfCurrent_Jaccard_Scores.drop(i, inplace=True)
#Sort
dfCurrent_Jaccard_Scores.sort_values(by=['Jaccard_Score'], ascending=False, ignore_index=True, inplace=True)
#dfCurrent_Jaccard_Scores
Jaccard_Index= int(dfCurrent_Jaccard_Scores.loc[0].Jaccard_Index) #make sure you have an index
print("Jaccard_Index:",Jaccard_Index)
Jaccard_Score = dfCurrent_Jaccard_Scores.loc[0].Jaccard_Score
print("Jaccard_Score:",Jaccard_Score)
###### Dice Sore
#Create Current dataframe containing my dice scores for row i
dfCurrent_Dice_Scores=pd.DataFrame(Dice_Scores(count_vectors_array,i), columns=['Dice_Score'])
#index in column
dfCurrent_Dice_Scores['Dice_Index']=dfCurrent_Dice_Scores.index
#Remove the current row
dfCurrent_Dice_Scores.drop(i, inplace=True)
#Sort
dfCurrent_Dice_Scores.sort_values(by=['Dice_Score'], ascending=False, ignore_index=True, inplace=True)
#dfCurrent_Dice_Scores
Dice_Index= int(dfCurrent_Dice_Scores.loc[0].Dice_Index) #make sure you have an index
print("Dice_Index:",Dice_Index)
Dice_Score = dfCurrent_Dice_Scores.loc[0].Dice_Score
print("Dice_Score:",Dice_Score)
####################################################
###### For TF-IDF
#Create Current dataframe containing similarities from TFIDF_Scores for row i
dfCurrent_TFIDF_Scores=pd.DataFrame(TFIDF_Scores[i][:], columns=['TFIDF_Score'])
#index in column
dfCurrent_TFIDF_Scores['TFIDF_Index']=dfCurrent_TFIDF_Scores.index
#Remove the current row
dfCurrent_TFIDF_Scores.drop(i, inplace=True)
#Sort
dfCurrent_TFIDF_Scores.sort_values(by=['TFIDF_Score'], ascending=False, ignore_index=True, inplace=True)
#dfCurrent_TFIDF_Scores
TFIDF_Index= int(dfCurrent_TFIDF_Scores.loc[0].TFIDF_Index) #make sure you have an index
print("TFIDF_Index:",TFIDF_Index)
TFIDF_Score = dfCurrent_TFIDF_Scores.loc[0].TFIDF_Score
print("TFIDF_Score:",TFIDF_Score)
####################################################
###### For OKAPI BM25
#Create Current dataframe containing similarities from Bm25 Scores for row i
dfCurrent_BM25_Scores=pd.DataFrame(bm25vectoriser.transform(dfCompanies.Description_Cleaned[i], dfCompanies.Description_Cleaned), columns=['BM25_Score'])
#index in column
dfCurrent_BM25_Scores['BM25_Index']=dfCurrent_BM25_Scores.index
#Remove the current row
dfCurrent_BM25_Scores.drop(i, inplace=True)
#Sort
dfCurrent_BM25_Scores.sort_values(by=['BM25_Score'], ascending=False, ignore_index=True, inplace=True)
#dfCurrent_BM25_Scores
BM25_Index= int(dfCurrent_BM25_Scores.loc[0].BM25_Index) #make sure you have an index
print("BM25_Index:",BM25_Index)
BM25_Score = dfCurrent_BM25_Scores.loc[0].BM25_Score
print("BM25_Score:",BM25_Score)
dfCurrentResults = pd.DataFrame({
"Index" : i,
"Name" : dfCompanies.loc[i].Name,
"Description" : dfCompanies.loc[i].Description,
"Description_Cleaned" : dfCompanies.loc[i].Description_Cleaned,
"Jaccard_Index" : Jaccard_Index,
"Jaccard_Name" : dfCompanies.loc[Jaccard_Index].Name,
"Jaccard_Description" : dfCompanies.loc[Jaccard_Index].Description,
"Jaccard_Description_Cleaned" : dfCompanies.loc[Jaccard_Index].Description_Cleaned,
"Jaccard_Score" : Jaccard_Score,
"Dice_Index" : Dice_Index,
"Dice_Name" : dfCompanies.loc[Dice_Index].Name,
"Dice_Description" : dfCompanies.loc[Dice_Index].Description,
"Dice_Description_Cleaned" : dfCompanies.loc[Dice_Index].Description_Cleaned,
"Dice_Score" : Dice_Score,
"TFIDF_Index" : TFIDF_Index,
"TFIDF_Name" : dfCompanies.loc[TFIDF_Index].Name,
"TFIDF_Description" : dfCompanies.loc[TFIDF_Index].Description,
"TFIDF_Description_Cleaned" : dfCompanies.loc[TFIDF_Index].Description_Cleaned,
"TFIDF_Score" : TFIDF_Score,
"BM25_Index" : BM25_Index,
"BM25_Name" : dfCompanies.loc[BM25_Index].Name,
"BM25_Description" : dfCompanies.loc[BM25_Index].Description,
"BM25_Description_Cleaned" : dfCompanies.loc[BM25_Index].Description_Cleaned,
"BM25_Score" : BM25_Score},
index=[0])
dfResults = pd.concat([dfResults,dfCurrentResults]) #add to global results
dfResults.reset_index(inplace=True, drop=True) #reset index
Sauvegarde de différents résultats dans Excel
Pour pouvoir effectuer un comparatif de visu, on sauvegarde certains résultats dans des fichiers Excel.
#####################################################################
# Save Results in Excel
#####################################################################
#All Results
dfResults.shape
dfResults.to_excel("SyntaxResults"+str(MaxSize)+".xlsx", sheet_name='SyntaxFResults', index=False)
#All Similar results
dfJDTBResults = dfResults.loc[(dfResults['Jaccard_Index'] == dfResults['Dice_Index']) &
(dfResults['Jaccard_Index'] == dfResults['TFIDF_Index']) &
(dfResults['Jaccard_Index'] == dfResults['BM25_Index']) ]
dfJDTBResults.shape
dfJDTBResults.to_excel("JDTBResults"+str(MaxSize)+".xlsx", sheet_name='JDTBResults', index=False)
######## Jaccard vs Dice
#Jaccard Dice Same results
dfJDResults = dfResults.loc[(dfResults['Jaccard_Index'] == dfResults['Dice_Index'])]
dfJDResults.drop(columns=["TFIDF_Index", "TFIDF_Name", "TFIDF_Description", "TFIDF_Description_Cleaned", "TFIDF_Score",
"BM25_Index", "BM25_Name", "BM25_Description", "BM25_Description_Cleaned", "BM25_Score"], inplace=True)
dfJDResults.shape
dfJDResults.to_excel("JDResults"+str(MaxSize)+".xlsx", sheet_name='JDResults', index=False)
#Jaccard Dice Different results
dfNotJDResults = dfResults.loc[(dfResults['Jaccard_Index'] != dfResults['Dice_Index'])]
dfNotJDResults.drop(columns=["TFIDF_Index", "TFIDF_Name", "TFIDF_Description", "TFIDF_Description_Cleaned", "TFIDF_Score",
"BM25_Index", "BM25_Name", "BM25_Description", "BM25_Description_Cleaned", "BM25_Score"], inplace=True)
dfNotJDResults.shape
dfNotJDResults.to_excel("NotJDResults"+str(MaxSize)+".xlsx", sheet_name='NotJDResults', index=False)
######## Jaccard vs TF-IDF
#Jaccard TF-IDF Same results
dfJTResults = dfResults.loc[(dfResults['Jaccard_Index'] == dfResults['TFIDF_Index'])]
dfJTResults.drop(columns=["Dice_Index", "Dice_Name", "Dice_Description", "Dice_Description_Cleaned", "Dice_Score",
"BM25_Index", "BM25_Name", "BM25_Description", "BM25_Description_Cleaned", "BM25_Score"], inplace=True)
dfJTResults.shape
dfJTResults.to_excel("JTResults"+str(MaxSize)+".xlsx", sheet_name='JTResults', index=False)
#Jaccard TF-IDF Different results
dfNotJTResults = dfResults.loc[(dfResults['Jaccard_Index'] != dfResults['TFIDF_Index'])]
dfNotJTResults.drop(columns=["Dice_Index", "Dice_Name", "Dice_Description", "Dice_Description_Cleaned", "Dice_Score",
"BM25_Index", "BM25_Name", "BM25_Description", "BM25_Description_Cleaned", "BM25_Score"], inplace=True)
dfNotJTResults.shape
dfNotJTResults.to_excel("NotJTResults"+str(MaxSize)+".xlsx", sheet_name='NotJTResults', index=False)
######## Jaccard vs BM25
#Jaccard BM25 Same results
dfJBResults = dfResults.loc[(dfResults['Jaccard_Index'] == dfResults['BM25_Index'])]
dfJBResults.drop(columns=["Dice_Index", "Dice_Name", "Dice_Description", "Dice_Description_Cleaned", "Dice_Score",
"TFIDF_Index", "TFIDF_Name", "TFIDF_Description", "TFIDF_Description_Cleaned", "TFIDF_Score"], inplace=True)
dfJBResults.shape
dfJBResults.to_excel("JBResults"+str(MaxSize)+".xlsx", sheet_name='JBResults', index=False)
#Jaccard BM25 Different results
dfNotJBResults = dfResults.loc[(dfResults['Jaccard_Index'] != dfResults['BM25_Index'])]
dfNotJBResults.drop(columns=["Dice_Index", "Dice_Name", "Dice_Description", "Dice_Description_Cleaned", "Dice_Score",
"TFIDF_Index", "TFIDF_Name", "TFIDF_Description", "TFIDF_Description_Cleaned", "TFIDF_Score"], inplace=True)
dfNotJBResults.shape
dfNotJBResults.to_excel("NotJBResults"+str(MaxSize)+".xlsx", sheet_name='NotJBResults', index=False)
######## TF-IDF vs BM25
#TF-IDF BM25 Same results
dfTBResults = dfResults.loc[(dfResults['TFIDF_Index'] == dfResults['BM25_Index'])]
dfTBResults.drop(columns=["Jaccard_Index", "Jaccard_Name", "Jaccard_Description", "Jaccard_Description_Cleaned", "Jaccard_Score",
"Dice_Index", "Dice_Name", "Dice_Description", "Dice_Description_Cleaned", "Dice_Score"], inplace=True)
dfTBResults.shape
dfTBResults.to_excel("TBResults"+str(MaxSize)+".xlsx", sheet_name='TBResults', index=False)
#TF-IDF BM25 Different results
dfNotTBResults = dfResults.loc[(dfResults['TFIDF_Index'] != dfResults['BM25_Index'])]
dfNotTBResults.drop(columns=["Jaccard_Index", "Jaccard_Name", "Jaccard_Description", "Jaccard_Description_Cleaned", "Jaccard_Score",
"Dice_Index", "Dice_Name", "Dice_Description", "Dice_Description_Cleaned", "Dice_Score"], inplace=True)
dfNotTBResults.shape
dfNotTBResults.to_excel("NotTBResults"+str(MaxSize)+".xlsx", sheet_name='NotTBResults', index=False)
Comparatif Jaccard et Dice
On notera que, dans notre cas, Jaccard et Dice donnent exactement les mêmes résultats, le fichier des résultats différents pour Jaccard et Dice « NotJDResults1288.xlsx » étant vide :


Comparatif Jaccard TF-IDF
Afin de nous faire une idée nous avons créé un fichier de comparaison à partir du fichiers des résultats différents entre Jaccard et TF-IDF « NotJTResults1288.xlsx ».
Le fichier de comparaison se nomme « NotJTResults1288Compare.xlsx » nous n’avons conservé que les descriptions de départ et avons rajouté ensuite les champs « Jaccard_OK » et « TFIDF_OK ». Ce fichier est disponible en téléchargement avec le code source.
Ensuite nous avons comparé les résultats à la main en indiquant un 1 si la réponse de Jaccard et/ou de TFIDF était satisfaisante. Nous comprenons que cette méthode est légèrement subjective.
Les résultats sons les suivants :
- Sur 1288 descriptions les différences existent 709 fois.
- Nous avons considéré comme correctes 212 réponses par Jaccard et 304 réponses par TF-IDF.
- Les réponses correctes aux 2 méthodes (notez que ce ne sont pas les mêmes résultats) sont de 144.
- Pour 337 réponses nous avons considéré qu’aucune méthode ne fonctionnait.
En étudiant de près les résultats vous pourrez constater que si TF-IDF fait mieux c’est grâce à la pondération inverse qui permet de booster certains termes (ou expressions) discriminants plus rares. Par exemple : Logiciels Libres, Expertise Comptable, Sage…
Globalement TF-IDF fait 1/3 de mieux que Jaccard.
Comparaison TF-IDF BM25
Comme précédemment nous avons créé un fichier de comparaison à partir des résultats différents de TF-IDF et BM25 « NotTBResults1288.xlsx ».
Le fichier de comparaison se nomme « NotTBResultsCompare.xlsx » et est aussi disponible dans le téléchargement des codes sources et a été créé à la main de façon subjective.
Les résultats sont les suivants :
- Sur les 1288 résultats, cette fois 591 sont différents.
- Nous avons considéré comme correctes 242 réponses par TF-IDF et 210 par BM25.
- Les réponses correctes aux 2 méthodes sont de 149.
- Pour 288 réponses nous avons considéré qu’aucune méthode ne fonctionnait.
Comme vous pouvez le constater, dans notre cas, nous avons considéré que TF-IDF fonctionnait mieux que BM25. Ceci va à l’encontre de nombreux de mes confrères qui présentent en général BM25 comme plus pertinent que TF-IDF…
Il ne vous reste plus qu’à consulter vos fichiers Excel pour vous faire votre propre opinion.
A bientôt,
Pierre