Cet article est le second consacré à la recherche de facteurs SEO grâce à des méthodes de Machine Learning.
Dans un article précédent nous avions récupéré des données de positionnement de Pages dans les SERPs de Google au moyen de l’API de Yooda Insight.
Compte tenu des données dont nous disposions, nous avions décidé de nous consacrer à déterminer les facteurs qui permettent à une page de se positionner dans le Top 3 des pages de résultats de Google.
A ce stade, nous avions créé 6 variables explicatives potentielles à savoir :
kwindomain : compte l’occurence du mot clé dans le domaine.
kwinurl : compte l’occurence du mot clé dans le reste de l’url.
ishttps : est-ce une url en https ?
isSSLEV : le SSL est-il de type Extended Value ?
urlnchar : nombre de caractères dans l’url.
urlslashcount : nombre de / dans l’url (pseudo « level »)
Ce sont ces variables qui devaient nous donner nos facteur SEO.
Ensuite, nous avions testé ces données avec différents algorithmes de Machine Learning.
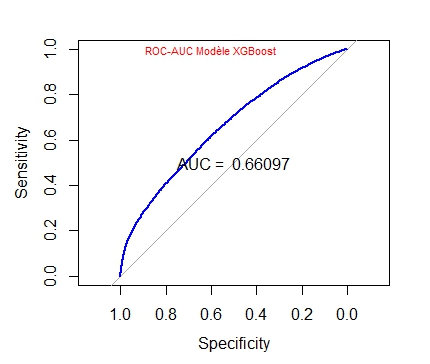
Le plus pertinent ayant été l’algorithme XGBoost nous avions eu les résultats suivants en ce qui concerne la courbe ROC et l’AUC :
ROC AUC XGBoost Données Yooda
et comme importance des variables la liste suivante
Le modèle n’étant pas suffisamment valide il convient d’enrichir nos données. Dans cette partie nous allons recueillir des données techniques sur les pages afin de « nourrir » l’algorithme.
Vous aurez aussi besoin du fichier de positionnement .csv sauvegardé précédemment. Vous pouvez le récupérer sous forme compressé .zip ici : AllDataKeywords.zip.
Crawler
Vous aurez besoin d’un « crawler » pour aller récupérer les données techniques des pages ainsi que le contenu qui servira plus tard.
Ce crawler est une modification d’un crawler que nous avions réalisé précédemment (voir dans cet article ).
Cette fois-ci, au lieu d’indiquer au crawler l’url d’un site qu’il va examiner en entier, on va donner au logiciel une liste d’URLs. Le code source du crawler vous est fourni plus loin.
Code Source
Vous pouvez copier/coller les morceaux de code source dans un script R pour les tester.
Attention ! si vous n’avez pas installé certains packages dans votre environnement RStudio, vous devez dé-commenter ceux qui vous intéressent.
#
#
######
#Test Machine Learning SEO PARTIE 2
#Données Yooda sur la thématique Cosmétiques Bio ###########
#On démarre en récupérant ALllDataKeywords.csv créé précédemment
#on enrichit les données avec des données on site crawlées
#on applique XGBoost pour définir un modele
#Qui répond à la question : Quelles sont les caractéristiques techniques on site des pages les mieux positionnées ?
#On teste le modele sur des pages
#
#########################################################################################################
#DEUXIEME PARTIE : crawl des pages Web et récupération d'informations techniques sur la page.
#########################################################################################################
#### Chargement des bibliothèques utiles ##########################################
#Installer une fois
#install.packages("doParallel")
#install.packages("xml2")
#install.packages("data.table")
#install.packages("Rcrawler")
#install.packages("plyr") #une fois
#install.packages("stringr") #une fois
#install.packages("lubridate") #une fois
#install.packages("pROC") #une fois
#install.packages("caret") #une fois
#install.packages("naivebayes") #une fois
#install.packages("randomforest") #une fois
#install.packages("ranger") #une fois
#install.packages("vtreat") #une fois
#install.packages("magrittr") #une fois
#install.packages("xgboost") #une fois
#install.packages("dplyr") #une fois
#Charger les bibliothèques
library(doParallel) #Notamment pour parallel::makeCluster
library(xml2) #Notamment pour read_html
library(data.table) #Notamment pour %like% %in% ...
library(Rcrawler) #Notamment pour GetEncoding, Linkparamsfilter...
library(plyr) #pour join
library(stringr) #pour str_match str_sub et autres traitements de chaines
library(lubridate) #pour parse_date_time
library(pROC) #pour ROC et AUC
library(caret) #pour varImp dans glm
library(naivebayes) #métode naive bayes
library(randomForest) #méthode Random Forest 1 avec randomForest
library(ranger) #méthode Random Forest 2 avec ranger
library(vtreat) #pour retraitement préalable pour XGBoost
library(magrittr) #pour le "pipe" %>%
library(xgboost) #pour XGBoost
library(dplyr) #pour mutate
Crawler
Le crawler est constitué de 3 fonctions : NetworkRobotParser, NetworkLinkNormalization et YoodaUrlsNetworkRcrawler. les 2 premières fonctions ne changent quasiment pas par rapport à ce que nous avions déjà vu dans des articles précédents.
YoodaUrlsNetworkRcrawler est ici spécifique. Cette version va enrichir un jeu de données fourni en entrée, va récupérer la réponse de la fonction GET et des informations qui nous intéressent.
Celles-ci sont récupérées dans le jeu de données « UrlsCrawled ». Le contenu des pages qui pourra servir par la suite sera sauvegardé dans des fichiers sur le disque dur. Ceux-ci sont organisés dans des répertoires par sites.
Le jeu de données en entrée doit comporter les informations suivantes :
url.
domain : nom de domaine ou de sous domaine.
domain_id (fourni par Yooda).
obs_domain_id : id d’observation pour le domaine
#
#
##############################################################################
### Fonctions nécessaires au crawl
##############################################################################
#' NetworkRobotParser modifie RobotParser qui générait une erreur d'encoding on rajoute MyEncod.
#' RobotParser fetch and parse robots.txt
#'
#' This function fetch and parse robots.txt file of the website which is specified in the first argument and return the list of correspending rules .
#' @param website character, url of the website which rules have to be extracted .
#' @param useragent character, the useragent of the crawler
#' @return
#' return a list of three elements, the first is a character vector of Disallowed directories, the third is a Boolean value which is TRUE if the user agent of the crawler is blocked.
#' @import httr
#' @export
#'
#' @examples
#'
#' RobotParser("http://www.glofile.com","AgentX")
#' #Return robot.txt rules and check whether AgentX is blocked or not.
#'
#'
NetworkRobotParser 0)<2) { #Si un seul http
# remove spaces
if(grepl("^\\s|\\s+$",links[t])) {
links[t]
Préparation des urls à crawler
Comme notre jeu de données comporte plusieurs fois les mêmes urls, nous allons extraire celles-ci afin de ne crawler qu’une seule fois chaque page. N’oubliez pas de dézipper le fichier AllDataKeywords.csv dans le répertoire courant de votre projet R.
#
#
############################################################################################
####### On démarre ici en récupérant le AllDataKeywords.csv précédent
AllDataKeywords
Comme vous pouvez le constater, nous avons quand même 49229 pages à crawler !!! Ce qui peut durer toute la nuit ! On veille aussi à libérer de la mémoire en sauvegardant sur le disque dur les jeux de données intermédiaires qui ne sont pas utiles tout de suite. Le crawl est gourmand en mémoire !
Notez aussi que l’on ne va s’intéresser qu’aux pages HTML. Il peut y avoir des documents en d’autres formats : .zip, .pdf, .doc… En effet, dans un prochain article on s’intéressera au contenu et aux balises des pages.
Crawl des Urls
Afin de faciliter le crawl et d’éviter de devoir tout refaire en cas de plantage, nous avons décidé de diviser en paquet de 5000 les urls. Les résultats sont sauvegardés dans des fichiers intermédiaires sur le disque dur. Si le système se bloque, vous pouvez diminuer la quantité d’urls par paquet en fonction de la mémoire de votre ordinateur. (j’ai 12 GO De RAM).
#
#
###############################################################################
### Crawl des URLS pour récuperer des donnéess "on page" complémentaires
# on va utiliser notre crawler écrit précédemment que l'on va modifier.
##############################################################################
#on va spliter le dataframe à crawler s'il est > 5000 obs.
chunk chunk) {
ListUrlsToCrawl
Exploration des données
Si vous n’avez pas pu crawler les pages, vous pouvez récupérer le fichier au format .zip ici : AllUrlsCrawledData.zip. N’oubliez-pas de le dézipper dans le répertoire courant de votre projet R.
Dans cette partie, nous allons examiner toutes les variables qui ont été récupérées précédemment pour chaque page. Ceci permettra de sélectionner et éventuellement transformer celles qui nous intéressent. Vous n’êtes pas obligés de faire les mêmes choix que moi.
#
#
#############################################################################
### Examinons ce que nous avons trouvé - Exploration des données
#############################################################################
AllUrlsCrawledData pas intéressant pas assez de données
##### /device view
#expires???
expires à voir
rm(max_age) #on fait de la place mémoire
#on va utiliser un max-age recalculé !!! voir plus bas avec la date. à garder.
##### /max-age
#Domain ??? nom de domaine indiqué dans le Cookie
cookie.domain transformer en booleen pour éviter les NA
#on prend !!!!!!
AllUrlsCrawledData$headers.set.cookie.domain.provided max_age
#######################################################################################
# headers.content_type.content_type
#######################################################################################
str(AllUrlsCrawledData) #affiche les variables
plyr::count(AllUrlsCrawledData$headers.content_type)
#
headers.content_type.content_type
Récupération des données de pages dans le data.frame des positions.
Nous allons maintenant récupérer les données sur les pages dans le jeu de données principal qui contient les informations de positions.
#
#
#############################################################################
### Enrichissement du fichier de positions global avec les données de pages
#############################################################################
AllUrlsCrawledData
Sélection des variables pour XGBoost
On sélectionne les variables explicatives que l’on souhaite tester à partir de l’exploration précédente.
#
#
#############################################################################
### Machine Learning sur les données intéressantes
#############################################################################
#############################################################################
### Creation du fichier de données à tester, de train et de test
#### Sélection des variables (passage 1)
#############################################################################
AllDataKeywords
Création du « train » et du « test »
On va créer les données d’entrainement et de test nécessaires au modèle.
#
#
##############################################################################
# Données à étudier (Passage 1 et 2)
##############################################################################
#Selection des variables.
Urlcoltokeep
Modèle XGBoost
On va préparer les données et lancer le modèle XGBoost
#
#
#######################################################################################
# XGBoost sur istop3pos
########################################################################################
#Traitements préalables des données pour être utilisées par XGBoost
# Création d'un "plan de traitement" à partir de train (données d'entrainement)
# ici le système va créer des variables supplémentaires booléennes pour différents niveaux de facteurs dans les
# variables originales : "one hot Encoding"
treatplan %
use_series(scoreFrame) %>%
filter(code %in% c("clean","lev")) %>% # get the rows you care about
use_series(varName)) # get the varName column
# Preparation des données d'entrainement à partir du plan de traitement créé précédemment
train.treat %
summarize(ntrees.train = which.min(train_error_mean), # find the index of min(train_rmse_mean)
ntrees.test = which.min(test_error_mean)) ) # find the index of min(test_rmse_mean)
#on prend le plus petit des 2
ntrees = min(Twotreesvalue$ntrees.train, Twotreesvalue$ntrees.test)
# The number of trees to use, as determined by xgb.cv
ntrees #passage 1 : 662 ; avec 75000 enr. 328
# Run xgboost
xgbmod
Pour info le nombre d’arbres ou d’itérations optimal pour ce jeu de données est 702.
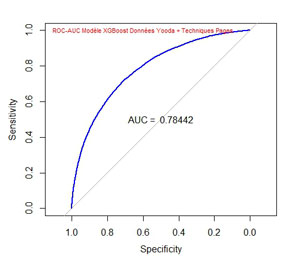
ROC AUC XGBoost Données Yooda + Techniques Pages
La courbe ROC et l’AUC sont les suivantes :
L’AUC (Area under the curve) est ici de 0,78442 par rapport à 0,66097 ce qui améliore considérablement la validité du modèle
A ce stade on peut voir que la taille du contenu, le nombre de liens internes, le temps de chargement des données, le nombre de caractères dans l’url expliquent le mieux le modèle.
D’un autre coté on peut voir que le fait que le mot-clé soit présent dans le nom de domaine ou non importe peu.
Attention à l’interprétation des données : pour chacune des variables il s’agit d’une contribution relative au modèle.
Par ailleurs on ne voit pas vraiment comment la variable contribue : par exemple on ne peut pas dire « plus la longueur du contenu augmente plus la page est susceptible d’être bien classée, ou inversement ».
Amélioration de l’interprétation
Afin d’améliorer la compréhension des variables d’importance nous allons relancer la fonction xgb.importance en ajoutant les informations data et label (ici pour nous data=as.matrix(train.treat) et label = train$istop3pos) de notre xgboost. Le système va splitter certaines variables et va nous fournir de nouvelles informations.
Si vous souhaitez en savoir plus sur ce sujet consultez l’article (en anglais) Understand your dataset with XGBoost dans la documentation sur XGBoost.
Notez que cette opération est très gourmande en ressources et si vous n’avez pas assez de mémoire vous devrez prendre un échantillon de votre jeu de données. Pour notre part nous avons pris un échantillon de 75.000 lignes.
#
#
#Précision sur l'importance des variables
#l'opération suivante est très gourmande en mémoire
#nettoyons la memoire
rm(cv)
rm(elog)
rm(importance)
rm(ROC)
rm(test)
rm(test.treat)
rm(treatplan)
memory.limit() #verification de la mémoire réservée pour R
memory.limit(size=80000) #augmentation de la mémoire j'ai 12 GO donc 8 pour R et 4 pour tout le reste ....
gc()
#pour l'interprétation des données :
#voir ici http://xgboost.readthedocs.io/en/latest/R-package/discoverYourData.html
(importanceRaw définition de outcome / vars
###################################################################
############# FIN PARTIE 2
Voici les variables les plus importantes trouvées par le système (sur 5220 !!!):
Feature
Split
Gain
RealCover
RealCover %
times.starttransfer_clean
0.5935
0.027933262
25256
0.92330189
headers.transfer_encoding.provided_clean
0.5
0.024140897
10470
0.38275938
urlslashcount_clean
3.5
0.019446893
21513
0.78646633
headers.set.cookie.domain.provided_clean
0.5
0.018943024
2614
0.09556189
headers.server.family_lev_x.apache
0.5
0.015215883
8054
0.29443591
ishttps_clean
0.5
0.015037965
17061
0.62371134
Vous voyez ici une nouvelle colonne, la colonne split. Il faut interpréter cette donnée comme « inférieur à ».
Par exemple, on peut dire que si le temps de chargement de la page (times.starttransfer_clean) est inférieur à 0,5935 ms, elle aura plus de chance d’être dans le Top 3.
De la même façon, on peut dire que les pages d’accueil (urlslashcount_clean < 3.5) sont plus susceptibles d’être dans le Top 3.Les pages d’accueil on à priori 2 ou 3 « / » dans l’url.
A contrario, sur certaines variables, l’information est difficile à interpréter.
Par exemple, si la variable headers.transfer_encoding.provided_clean est en dessous de 0.5, donc dans ce cas 0, car on a un booléen, cela voudrait dire que le fait de ne pas fournir une information donnerait plus de chance d’être bien positionné ??? Ceci n’a évidemment pas beaucoup de sens.
Je vous laisse examiner par vous même les informations que vous pouvez recueillir et en tirer vos conclusions.
Dans un prochain article, nous ajouterons des informations liées au contenu des pages pour enrichir notre modèle.
Si vous avez des remarques, questions suggestions n’hésitez pas à laisser un commentaire.
A bientôt,
Pierre
Partager la publication "Recherche de facteurs SEO avec le Machine Learning (partie 2)"