Partager la publication "Recherche de facteurs SEO avec le Machine Learning (partie 2)"
Cet article est le second consacré à la recherche de facteurs SEO grâce à des méthodes de Machine Learning.
Dans un article précédent nous avions récupéré des données de positionnement de Pages dans les SERPs de Google au moyen de l’API de Yooda Insight.
Compte tenu des données dont nous disposions, nous avions décidé de nous consacrer à déterminer les facteurs qui permettent à une page de se positionner dans le Top 3 des pages de résultats de Google.
A ce stade, nous avions créé 6 variables explicatives potentielles à savoir :
- kwindomain : compte l’occurence du mot clé dans le domaine.
- kwinurl : compte l’occurence du mot clé dans le reste de l’url.
- ishttps : est-ce une url en https ?
- isSSLEV : le SSL est-il de type Extended Value ?
- urlnchar : nombre de caractères dans l’url.
- urlslashcount : nombre de / dans l’url (pseudo « level »)
Ce sont ces variables qui devaient nous donner nos facteur SEO.
Ensuite, nous avions testé ces données avec différents algorithmes de Machine Learning.
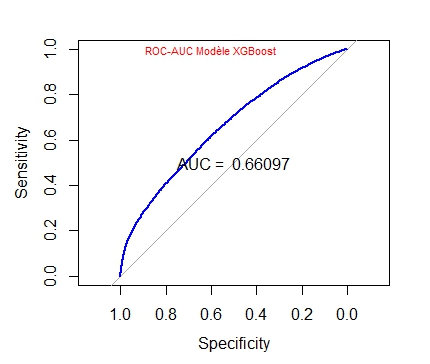
Le plus pertinent ayant été l’algorithme XGBoost nous avions eu les résultats suivants en ce qui concerne la courbe ROC et l’AUC :
et comme importance des variables la liste suivante
Feature Gain
1: urlnchar_clean 0.410036436
2: urlslashcount_clean 0.366750031
3: ishttps_clean 0.118527197
4: isSSLEV_clean 0.065902531
5: kwinurl_clean 0.035875160
6: kwindomain_clean 0.002908645
Le modèle n’étant pas suffisamment valide il convient d’enrichir nos données. Dans cette partie nous allons recueillir des données techniques sur les pages afin de « nourrir » l’algorithme.
De quoi aurons nous besoin ?
Logiciel R
Comme dans nos articles précédents nous vous invitons à télécharger Le Logiciel R sur ce site https://cran.r-project.org/, ainsi que l’environnement de développement RStudio ici : https://www.rstudio.com/products/rstudio/download/, afin de pouvoir tester vous même le code source.
Fichier précédent
Vous aurez aussi besoin du fichier de positionnement .csv sauvegardé précédemment. Vous pouvez le récupérer sous forme compressé .zip ici : AllDataKeywords.zip.
Crawler
Vous aurez besoin d’un « crawler » pour aller récupérer les données techniques des pages ainsi que le contenu qui servira plus tard.
Ce crawler est une modification d’un crawler que nous avions réalisé précédemment (voir dans cet article ).
Cette fois-ci, au lieu d’indiquer au crawler l’url d’un site qu’il va examiner en entier, on va donner au logiciel une liste d’URLs. Le code source du crawler vous est fourni plus loin.
Code Source
Vous pouvez copier/coller les morceaux de code source dans un script R pour les tester.
Vous pouvez aussi récupérer gratuitement le code source en entier dans notre boutique : https://www.anakeyn.com/boutique/produit/script-r-facteurs-seo-et-ml-2/
Chargement des bibliothèques
Attention ! si vous n’avez pas installé certains packages dans votre environnement RStudio, vous devez dé-commenter ceux qui vous intéressent.
#
#
######
#Test Machine Learning SEO PARTIE 2
#Données Yooda sur la thématique Cosmétiques Bio ###########
#On démarre en récupérant ALllDataKeywords.csv créé précédemment
#on enrichit les données avec des données on site crawlées
#on applique XGBoost pour définir un modele
#Qui répond à la question : Quelles sont les caractéristiques techniques on site des pages les mieux positionnées ?
#On teste le modele sur des pages
#
#########################################################################################################
#DEUXIEME PARTIE : crawl des pages Web et récupération d'informations techniques sur la page.
#########################################################################################################
#### Chargement des bibliothèques utiles ##########################################
#Installer une fois
#install.packages("doParallel")
#install.packages("xml2")
#install.packages("data.table")
#install.packages("Rcrawler")
#install.packages("plyr") #une fois
#install.packages("stringr") #une fois
#install.packages("lubridate") #une fois
#install.packages("pROC") #une fois
#install.packages("caret") #une fois
#install.packages("naivebayes") #une fois
#install.packages("randomforest") #une fois
#install.packages("ranger") #une fois
#install.packages("vtreat") #une fois
#install.packages("magrittr") #une fois
#install.packages("xgboost") #une fois
#install.packages("dplyr") #une fois
#Charger les bibliothèques
library(doParallel) #Notamment pour parallel::makeCluster
library(xml2) #Notamment pour read_html
library(data.table) #Notamment pour %like% %in% ...
library(Rcrawler) #Notamment pour GetEncoding, Linkparamsfilter...
library(plyr) #pour join
library(stringr) #pour str_match str_sub et autres traitements de chaines
library(lubridate) #pour parse_date_time
library(pROC) #pour ROC et AUC
library(caret) #pour varImp dans glm
library(naivebayes) #métode naive bayes
library(randomForest) #méthode Random Forest 1 avec randomForest
library(ranger) #méthode Random Forest 2 avec ranger
library(vtreat) #pour retraitement préalable pour XGBoost
library(magrittr) #pour le "pipe" %>%
library(xgboost) #pour XGBoost
library(dplyr) #pour mutate
Crawler
Le crawler est constitué de 3 fonctions : NetworkRobotParser, NetworkLinkNormalization et YoodaUrlsNetworkRcrawler. les 2 premières fonctions ne changent quasiment pas par rapport à ce que nous avions déjà vu dans des articles précédents.
YoodaUrlsNetworkRcrawler est ici spécifique. Cette version va enrichir un jeu de données fourni en entrée, va récupérer la réponse de la fonction GET et des informations qui nous intéressent.
Celles-ci sont récupérées dans le jeu de données « UrlsCrawled ». Le contenu des pages qui pourra servir par la suite sera sauvegardé dans des fichiers sur le disque dur. Ceux-ci sont organisés dans des répertoires par sites.
Le jeu de données en entrée doit comporter les informations suivantes :
- url.
- domain : nom de domaine ou de sous domaine.
- domain_id (fourni par Yooda).
- obs_domain_id : id d’observation pour le domaine
#
#
##############################################################################
### Fonctions nécessaires au crawl
##############################################################################
#' NetworkRobotParser modifie RobotParser qui générait une erreur d'encoding on rajoute MyEncod.
#' RobotParser fetch and parse robots.txt
#'
#' This function fetch and parse robots.txt file of the website which is specified in the first argument and return the list of correspending rules .
#' @param website character, url of the website which rules have to be extracted .
#' @param useragent character, the useragent of the crawler
#' @return
#' return a list of three elements, the first is a character vector of Disallowed directories, the third is a Boolean value which is TRUE if the user agent of the crawler is blocked.
#' @import httr
#' @export
#'
#' @examples
#'
#' RobotParser("http://www.glofile.com","AgentX")
#' #Return robot.txt rules and check whether AgentX is blocked or not.
#'
#'
NetworkRobotParser <- function(website, useragent, Encod="UTF-8") {
URLrobot<-paste(website,"/robots.txt", sep = "")
bots<-GET(URLrobot, user_agent("Mozilla/5.0 (Windows NT 6.3; WOW64; rv:42.0) Gecko/20100101 Firefox/42.0"),timeout(5))
#PR Ajout de Encod
MyEncod <- trimws(gsub("charset=", "", unlist(strsplit(bots$headers$'content-type', ";"))[2]))
if (is.null(MyEncod) || is.na(MyEncod) ) MyEncod <- Encod
bots<-as.character(content(bots, as="text", encoding = MyEncod)) #pour éviter erreur d encoding
write(bots, file = "robots.txt")
bots <- readLines("robots.txt") # dans le repertoire du site
if (missing(useragent)) useragent<-"NetworkRcrawler"
useragent <- c(useragent, "*")
ua_positions <- which(grepl( "[Uu]ser-[Aa]gent:[ ].+", bots))
Disallow_dir<-vector()
allow_dir<-vector()
for (i in 1:length(useragent)){
if (useragent[i] == "*") useragent[i]<-"\\*"
Gua_pos <- which(grepl(paste("[Uu]ser-[Aa]gent:[ ]{0,}", useragent[i], "$", sep=""),bots))
if (length(Gua_pos)!=0 ){
Gua_rules_start <- Gua_pos+1
Gua_rules_end <- ua_positions[which(ua_positions==Gua_pos)+1]-1
if(is.na(Gua_rules_end)) Gua_rules_end<- length(bots)
Gua_rules <- bots[Gua_rules_start:Gua_rules_end]
Disallow_rules<-Gua_rules[grep("[Dd]isallow",Gua_rules)]
Disallow_dir<-c(Disallow_dir,gsub(".*\\:.","",Disallow_rules))
allow_rules<-Gua_rules[grep("^[Aa]llow",Gua_rules)]
allow_dir<-c(allow_dir,gsub(".*\\:.","",allow_rules))
}
}
if ("/" %in% Disallow_dir){
Blocked=TRUE
print ("This bot is blocked from the site")} else{ Blocked=FALSE }
Rules<-list(Allow=allow_dir,Disallow=Disallow_dir,Blocked=Blocked )
return (Rules)
}
#' NetworkLinkNormalization :modification de LinkNormalization :
#' on ne renvoie pas des liens uniques mais multiples : le dédoublonnement des liens doit se faire lors de
#' l'étude du réseau avec igraph.
#' correction aussi pour les liens avec # et mailto:, callto: et tel: qui étaient renvoyés.
#' correction de bug
#'
#' A function that take a URL _charachter_ as input, and transforms it into a canonical form.
#' @param links character, the URL to Normalize.
#' @param current character, The URL of the current page source of the link.
#' @return
#' return the simhash as a nmeric value
#' @author salim khalilc corrigé par Pierre Rouarch
#' @details
#' This funcion call an external java class
#' @export
#'
#' @examples
#'
#' # Normalize a set of links
#'
#' links<-c("http://www.twitter.com/share?url=http://glofile.com/page.html",
#' "/finance/banks/page-2017.html",
#' "./section/subscription.php",
#' "//section/",
#' "www.glofile.com/home/",
#' "glofile.com/sport/foot/page.html",
#' "sub.glofile.com/index.php",
#' "http://glofile.com/page.html#1"
#' )
#'
#' links<-LinkNormalization(links,"http://glofile.com" )
#'
#'
NetworkLinkNormalization<-function(links, current){
# protocole<-strsplit(current, "/")[[c(1,1)]] #Error ????
protocole<-strsplit(as.character(current), "/")[[c(1,1)]]
base <- strsplit(gsub("http://|https://", "", current), "/")[[c(1, 1)]]
base2 <- strsplit(gsub("http://|https://|www\\.", "", current), "/")[[c(1, 1)]]
rlinks<-c();
#base <- paste(base, "/", sep="")
for(t in 1:length(links)){
if (!is.null(links[t]) && length(links[t]) == 1){ #s'il y a qq chose
if (!is.na(links[t])){ #pas NA
if(substr(links[t],1,2)!="//"){ #si ne commence pas par //
if(sum(gregexpr("http", links[t], fixed=TRUE)[[1]] > 0)<2) { #Si un seul http
# remove spaces
if(grepl("^\\s|\\s+$",links[t])) {
links[t]<-gsub("^\\s|\\s+$", "", links[t] , perl=TRUE)
}
#if starts with # remplace par url courante
if (substr(links[t],1,1)=="#"){
links[t]<- current } #on est sut la même page (PR)
#if starts with / add base
if (substr(links[t],1,1)=="/"){
links[t]<-paste0(protocole,"//",base,links[t]) }
#if starts with ./ add base
if (substr(links[t],1,2)=="./") {
# la url current se termine par /
if(substring(current, nchar(current)) == "/"){
links[t]<-paste0(current,gsub("\\./", "",links[t]))
# si non
} else {
links[t]<-paste0(current,gsub("\\./", "/",links[t]))
}
}
if(substr(current,1,10)=="http://www" || substr(current,1,11)=="https://www") { #si on a un protocole + www sur la page courante.
if(substr(links[t],1,10)!="http://www" && substr(links[t],1,11)!="https://www" && substr(links[t],1,8)!="https://" && substr(links[t],1,7)!="http://" ){
if (substr(links[t],1,3)=="www") {
links[t]<-paste0(protocole,"//",links[t])
} else {
#tests liens particulier sans protocole http://
if(substr(links[t],1,7)!="mailto:" && substr(links[t],1,7)!="callto:" && substr(links[t],1,4)!="tel:") {
links[t]<-paste0(protocole,"//www.",links[t])
}
}
}
}else { #à priori pas de http sans www dans current
if(substr(links[t],1,7)!="http://" && substr(links[t],1,8)!="https://" ){
#test liens cas particuliers sans protocole http://
if(substr(links[t],1,7)!="mailto:" && substr(links[t],1,7)!="callto:" && substr(links[t],1,4)!="tel:") {
links[t]<-paste0(protocole,"//",links[t])
}
}
}
if(grepl("#",links[t])){links[t]<-gsub("\\#(.*)","",links[t])} #on vire ce qu'il y a derrière le #
rlinks <- c(rlinks,links[t]) #ajout du lien au paquet de liens
}
}
}
}
}
#rlinks<-unique(rlinks) #NON : garder tous les liens, pas d'unicité.
return (rlinks)
}
#' YoodaUrlsNetworkRcrawler (modification NetworkRcrawler) :
#' YoodaUrlsNetworkRcrawler a pour objectif d'enrichir un fichier de données d'urls fourni par Yooda.
#' le data.frame en entrée doit comporter les variables suivantes :
#' - url
#' - domain : nom de domaine ou de sous domaine
#' - domain_id (fourni par Yooda)
#' - obs_domain_id : id d'observation pour le domaine
#'
#' Un fichier d'URLs est fourni au lieu d'une seule url de site.
#' uniquement les pages fornies sont crawlées, on ne rajoute pas de nouvelles pages au fur et à mesure du crawl.
#' Pour sauvegarder la mémoire on ne met pas le contenu de la page dans le fichiers des Noeuds mais on le sauvegarde
#' dans des fichiers .html à part.
#'
#' Paramètres
#' @param no_cores integer, specify the number of clusters (logical cpu) for parallel crawling, by default it's the numbers of available cores.
#' @param no_conn integer, it's the number of concurrent connections per one core, by default it takes the same value of no_cores.
#' @param RequestsDelay integer, The time interval between each round of parallel http requests, in seconds used to avoid overload the website server. default to 0.
#' @param Obeyrobots boolean, if TRUE, the crawler will parse the website\'s robots.txt file and obey its rules allowed and disallowed directories.
#' @param Useragent character, the User-Agent HTTP header that is supplied with any HTTP requests made by this function.it is important to simulate different browser's user-agent to continue crawling without getting banned.
#' @param Encod character, set the website caharacter encoding, by default the crawler will automatically detect the website defined character encoding.
#' @param Timeout integer, the maximum request time, the number of seconds to wait for a response until giving up, in order to prevent wasting time waiting for responses from slow servers or huge pages, default to 5 sec.
#' @param URLlenlimit integer, the maximum URL length limit to crawl, to avoid spider traps; default to 255.
#' @param urlExtfilter character's vector, by default the crawler avoid irrelevant files for data scraping such us xml,js,css,pdf,zip ...etc, it's not recommanded to change the default value until you can provide all the list of filetypes to be escaped.
#' @param ignoreUrlParams character's vector, the list of Url paremeter to be ignored during crawling .
#' @param NetwExtLinks boolean, If TRUE external hyperlinks (outlinks) also will be counted on Network edges and nodes.
#' Paramètres ajoutés
#' @param Urls data.frame a Urls collection (format yooda) #anciennement un Website uniquement
#' @param MaxPagesParsed integer, Maximum de pages à Parser (Ajout PR)
#' @param XPathLinksAreaNodes character, xpath, si l'on veut cibler la zone de la page ou récupérér les liens (Ajout PR)
#' Attention si la zone n'est pas trouvé tous les liens de la page sont récupérés.
#'
#'
#' @return
#'
#' The crawling and scraping process may take a long time to finish, therefore, to avoid data loss
#' in the case that a function crashes or stopped in the middle of action, some important data are
#' exported at every iteration to R global environment:
#'
#' - NetwNodes : Dataframe with alls hyperlinks and parameters of pages founded.
#'
#' @author salim khalil modifié simplifié par Pierre Rouarch
#' @import foreach doParallel parallel data.table selectr
#' @export
#' @importFrom utils write.table
#' @importFrom utils flush.console
#'
YoodaUrlsNetworkRcrawler <- function (Urls, no_cores, no_conn, RequestsDelay=0, Obeyrobots=FALSE,
Useragent, Encod, Timeout=5, URLlenlimit=255, urlExtfilter,
ignoreUrlParams = "", NetwExtLinks=FALSE,
MaxPagesParsed=500) {
DIR<-getwd() #Répertoire courant
urlbotfiler=" " #ne sert pas à grand chose
if (missing(no_cores)) no_cores<-parallel::detectCores()-1
if (missing(no_conn)) no_conn<-no_cores
if(missing(Useragent)) {Useragent="Mozilla/5.0 (Windows NT 6.3; WOW64; rv:42.0) Gecko/20100101 Firefox/42.0"}
if (missing(Encod)) Encod<-"UTF-8"
#Filtrer les documents/fichiers non souhaités
if(missing(urlExtfilter)) {
urlExtfilter<-c("flv","mov","swf","txt","xml","js","css","zip","gz","rar","7z","tgz","tar","z",
"gzip","bzip","tar","mp3","mp4","aac","wav","au","wmv","avi","mpg","mpeg","pdf",
"doc","docx","xls","xlsx","ppt","pptx","jpg","jpeg","png","gif","psd","ico","bmp",
"odt","ods","odp","odb","odg","odf")
} #/if(missing(urlExtfilter))
pkg.env <- new.env() #créé un nouvel environnement pour données locales
#Création des variables pour la data.frame des noeuds/pages pkg.env$GraphNodes à partir de Urls
#on va enrichir les données de notre paquet d'urls avec celles que l'on récupère sur la page
#Recupérés de GET
Urls[,"status_code"] <- NA
Urls[,"headers.set_cookie"] <- NA
Urls[,"headers.date"] <- NA
Urls[,"headers.content_type"] <- NA
Urls[,"headers.content_type.encoding"] <- NA #ajout
Urls[,"headers.transfer_encoding"] <- NA
Urls[,"headers.connection"] <- NA
Urls[,"headers.server"] <- NA
Urls[,"headers.x_powered_by"] <- NA
Urls[,"headers.p3p"] <- NA
Urls[,"headers.vary"] <- NA
Urls[,"headers.accept_ranges"] <- NA
Urls[,"headers.link"] <- NA
Urls[,"headers.content_encoding"] <- NA
Urls[,"headers.x_ipbl_instance"] <- 0
Urls[,"headers.cache_control"] <- NA
Urls[,"all_headers.status"] <- NA
Urls[,"all_headers.version"] <- NA
Urls[,"all_headers.headers.set_cookie"] <- NA
Urls[,"all_headers.headers.content_type"] <- NA
Urls[,"all_headers.headers.transfer_encoding"] <- NA
Urls[,"all_headers.headers.server"] <- NA
Urls[,"all_headers.headers.x_powered_by"] <- NA
Urls[,"all_headers.headers.vary"] <- NA
Urls[,"all_headers.headers.link"] <- NA
Urls[,"all_headers.headers.content_encoding"] <- NA
Urls[,"all_headers.headers.x_ipbl_instance"] <- 0
Urls[,"content_length"] <- 0
Urls[,"response_date"] <- NA
Urls[,"times.redirect"] <- 0
Urls[,"times.namelookup"] <- 0
Urls[,"times.connect"] <- 0
Urls[,"times.pretransfer"] <- 0
Urls[,"times.starttransfer"] <- 0
Urls[,"times.total"] <- 0
#En fonction du contenu
Urls[,"NbIntLinks"] <- 0 #Nombre de liens internes
Urls[,"NbExtLinks"] <- 0 #Nombre de liens externes
#pour le traitement interne
Urls[,"MyStatusPage"] <- NA #crawlée ou non
pkg.env$GraphNodes <- Urls
#Autres variables intermédiaires utiles.
allpaquet<-list() #Contient les paquets de pages crawlées parsées.
Links<-vector() #Liste des liens sur la page
IndexErrPages<-c(200, 300, 301, 302, 404, 403, 500, 501, 502, 503, NULL, NA, "")
#Cela ne sert pas à grand chose
t<-1 #index de début de paquet de pages à parser (pour GET)
i<-0 #index de pages parsées pour GET
TotalPagesParsed <- 1 #Nombre total de pages crawlées/parsées : ici la même chose.
#cluster initialisation pour pouvoir travailler sur plusieurs clusters en même temps .
cl <- makeCluster(no_cores, outfile="") #création des clusters nombre no_cores fourni par nos soins.
registerDoParallel(cl)
clusterEvalQ(cl, library(httr)) #Pour la fonction GET
############################################################################################
# Utilisation de GET()
############################################################################################
#Tant qu'il reste des pages à crawler :
while (t<=nrow(pkg.env$GraphNodes) & t<=MaxPagesParsed) {
# Calcul du nombre de pages à crawler !
rest<-nrow(pkg.env$GraphNodes)-t #Rest = nombre de pages restantes à crawler = nombre de pages - pointeur actuel de début de paquet
#Si le nombre de connections simultanées est inférieur au nombre de pages restantes à crawler.
if (no_conn<=rest){
l<-t+no_conn-1 #la limite du prochain paquet de pages à crawler = pointeur actuel + nombre de connections - 1
} else {
l<-t+rest #Sinon la limite = pointeur + reste
} #/else
#Délai
if (RequestsDelay!=0) {
Sys.sleep(RequestsDelay)
} #/delay
#Extraction d'un paquet de pages de t pointeur actuel à l limite
allGetResponse <- foreach(i=t:l, .verbose=FALSE, .inorder=FALSE, .errorhandling='pass') %dopar%
{
TheUrl <- pkg.env$GraphNodes[i,"url"] #url de la page à crawler.
GET(url = TheUrl, timeout = Timeout )
} #/ foreach
#On regarde ce que l'on a récupéré de GET
for (s in 1:length(allGetResponse)) {
TheUrl <- pkg.env$GraphNodes[t+s-1,"url"] #t+s-1 pointeur courant dans GraphNodes
#cat("TheURL ", TheUrl, "!!")
domain <- pkg.env$GraphNodes[t+s-1,"domain"] #pour tester liens externes/internes
#cat("Domaine ", domain, "!!")
domain_id <- pkg.env$GraphNodes[t+s-1,"domain_id"] #pour le nom du folder
obs_domain_id <- pkg.env$GraphNodes[t+s-1,"obs_domain_id"] #pourle nom du fichier html ???
foldername<-paste(domain,"-",domain_id ,sep = "")
path<-paste(DIR,"/", foldername ,sep = "")
if (!file.exists(path)) dir.create(path, recursive = TRUE, mode = "0777") #creation du sous-répertoire
if (!is.null(allGetResponse[[s]])) { #Est-ce que l'on a une réponse pour cette page ?
if (!is.null(allGetResponse[[s]]$status_code)) { #Est-ce que l'on a un status pour cette page ?
#Recupération des données de la page crawlée et/ou parsée.
#status code
pkg.env$GraphNodes[t+s-1, "status_code"] <- allGetResponse[[s]]$status_code
#headers
if (!is.null(allGetResponse[[s]]$headers$`set-cookie`))
pkg.env$GraphNodes[t+s-1, "headers.set_cookie"] <- allGetResponse[[s]]$headers$`set-cookie`
if (!is.null(allGetResponse[[s]]$headers$date))
pkg.env$GraphNodes[t+s-1, "headers.date"] <- allGetResponse[[s]]$headers$date
if (!is.null(allGetResponse[[s]]$headers$`content-type`)) {
pkg.env$GraphNodes[t+s-1, "headers.content_type"] <- allGetResponse[[s]]$headers$`content-type`
# Si on n'avait pas déjà Encoding
pkg.env$GraphNodes[t+s-1, "headers.content_type.encoding"] <- trimws(gsub("charset=", "", unlist(strsplit(allGetResponse[[s]]$headers$'content-type', ";"))[2]))
}
if (!is.null(allGetResponse[[s]]$headers$`transfer-encoding`))
pkg.env$GraphNodes[t+s-1, "headers.transfer_encoding"] <- allGetResponse[[s]]$headers$`transfer-encoding`
if (!is.null(allGetResponse[[s]]$headers$connection))
pkg.env$GraphNodes[t+s-1, "headers.connection"] <- allGetResponse[[s]]$headers$connection
if (!is.null(allGetResponse[[s]]$headers$server))
pkg.env$GraphNodes[t+s-1, "headers.server"] <- allGetResponse[[s]]$headers$server
if (!is.null(allGetResponse[[s]]$headers$`x-powered-by`))
pkg.env$GraphNodes[t+s-1, "headers.x_powered_by"] <- allGetResponse[[s]]$headers$`x-powered-by`
if (!is.null(allGetResponse[[s]]$headers$p3p))
pkg.env$GraphNodes[t+s-1, "headers.p3p"] <- allGetResponse[[s]]$headers$p3p
if (!is.null(allGetResponse[[s]]$headers$vary))
pkg.env$GraphNodes[t+s-1, "headers.vary"] <- allGetResponse[[s]]$headers$vary
if (!is.null(allGetResponse[[s]]$headers$`accept-ranges`))
pkg.env$GraphNodes[t+s-1, "headers.accept_ranges"] <- allGetResponse[[s]]$headers$`accept-ranges`
if (!is.null(allGetResponse[[s]]$headers$link))
pkg.env$GraphNodes[t+s-1, "headers.link"] <- allGetResponse[[s]]$headers$link
if (!is.null(allGetResponse[[s]]$headers$`content-encoding`))
pkg.env$GraphNodes[t+s-1, "headers.content_encoding"] <- allGetResponse[[s]]$headers$`content-encoding`
if (!is.null(allGetResponse[[s]]$headers$`x-ipbl-instance`))
pkg.env$GraphNodes[t+s-1, "headers.x_ipbl_instance"] <- allGetResponse[[s]]$headers$`x-ipbl-instance`
if (!is.null(allGetResponse[[s]]$headers$`cache-control`))
pkg.env$GraphNodes[t+s-1, "headers.cache_control"] <- allGetResponse[[s]]$headers$`cache-control`
#all_headers[[1]]
if (!is.null(allGetResponse[[s]]$all_headers[[1]]$status))
pkg.env$GraphNodes[t+s-1, "all_headers.status"] <- allGetResponse[[s]]$all_headers[[1]]$status
if (!is.null(allGetResponse[[s]]$all_headers[[1]]$version))
pkg.env$GraphNodes[t+s-1, "all_headers.version"] <- allGetResponse[[s]]$all_headers[[1]]$version
#all_headers headers
if (!is.null(allGetResponse[[s]]$all_headers[[1]]$headers$`set-cookie`))
pkg.env$GraphNodes[t+s-1, "all_headers.headers.set_cookie"] <- allGetResponse[[s]]$all_headers[[1]]$headers$`set-cookie`
if (!is.null(allGetResponse[[s]]$all_headers[[1]]$headers$`content-type`))
pkg.env$GraphNodes[t+s-1, "all_headers.headers.content_type"] <- allGetResponse[[s]]$all_headers[[1]]$headers$`content-type`
if (!is.null(allGetResponse[[s]]$all_headers$headers[[1]]$`transfer-encoding`))
pkg.env$GraphNodes[t+s-1, "all_headers.headers.transfer_encoding"] <- allGetResponse[[s]]$all_headers[[1]]$headers$`transfer-encoding`
if (!is.null(allGetResponse[[s]]$all_headers[[1]]$headers$server))
pkg.env$GraphNodes[t+s-1, "all_headers.headers.server"] <- allGetResponse[[s]]$all_headers[[1]]$headers$server
if (!is.null(allGetResponse[[s]]$all_headers[[1]]$headers$`x-powered-by`))
pkg.env$GraphNodes[t+s-1, "all_headers.headers.x_powered_by"] <- allGetResponse[[s]]$all_headers[[1]]$headers$`x-powered-by`
if (!is.null(allGetResponse[[s]]$all_headers[[1]]$headers$vary))
pkg.env$GraphNodes[t+s-1, "all_headers.headers.vary"] <- allGetResponse[[s]]$all_headers[[1]]$headers$vary
if (!is.null(allGetResponse[[s]]$all_headers[[1]]$headers$link))
pkg.env$GraphNodes[t+s-1, "all_headers.headers.link"] <- allGetResponse[[s]]$all_headers[[1]]$headers$link
if (!is.null(allGetResponse[[s]]$all_headers[[1]]$headers$`content-encoding`))
pkg.env$GraphNodes[t+s-1, "all_headers.headers.content_encoding"] <- allGetResponse[[s]]$all_headers[[1]]$headers$`content-encoding`
if (!is.null(allGetResponse[[s]]$all_headers[[1]]$headers$`x-ipbl-instance`))
pkg.env$GraphNodes[t+s-1, "all_headers.headers.x_ipbl_instance"] <- allGetResponse[[s]]$all_headers[[1]]$headers$`x-ipbl-instance`
#Taille du fichier
if (!is.null(allGetResponse[[s]]$content))
pkg.env$GraphNodes[t+s-1, "content_length"] <- length(allGetResponse[[s]]$content)
#date de response
if (!is.null(allGetResponse[[s]]$date))
pkg.env$GraphNodes[t+s-1, "response_date"] <- allGetResponse[[s]]$date
#times (speed)
if (!is.null(allGetResponse[[s]]$times["redirect"]))
pkg.env$GraphNodes[t+s-1, "times.redirect"] <- allGetResponse[[s]]$times["redirect"]
if (!is.null(allGetResponse[[s]]$times["namelookup"]))
pkg.env$GraphNodes[t+s-1, "times.namelookup"] <- allGetResponse[[s]]$times["namelookup"]
if (!is.null(allGetResponse[[s]]$times["connect"]))
pkg.env$GraphNodes[t+s-1, "times.connect"] <- allGetResponse[[s]]$times["connect"]
if (!is.null(allGetResponse[[s]]$times["pretransfer"]))
pkg.env$GraphNodes[t+s-1, "times.pretransfer"] <- allGetResponse[[s]]$times["pretransfer"]
if (!is.null(allGetResponse[[s]]$times["starttransfer"]))
pkg.env$GraphNodes[t+s-1, "times.starttransfer"] <- allGetResponse[[s]]$times["starttransfer"]
if (!is.null(allGetResponse[[s]]$times["total"]))
pkg.env$GraphNodes[t+s-1, "times.total"] <- allGetResponse[[s]]$times["total"]
#cat("Content type ", pkg.env$GraphNodes[t+s-1, "headers.content_type"], "\n")
#Marque la page comme "headers_red"
pkg.env$GraphNodes[t+s-1, "MyStatusPage"] <- "headers_red" #mais pas parsé pour l'instant
if (grepl("html",pkg.env$GraphNodes[t+s-1, "headers.content_type"])) {
#On va sauvegarder tout le contenu HTML dans un fichier
MyEncod <- pkg.env$GraphNodes[t+s-1, "headers.content_type.encoding"] #Verifie que l'on a un encoding auparavant
if (is.null(MyEncod) || is.na(MyEncod) ) MyEncod <- Encod #sinon force à Encod
tc <- tryCatch(read_html(x = httr::content(allGetResponse[[s]], "text")),
error = function(e){'empty-page'})
if (!grepl("empty-page",tc)) {
#cat("tryCatch OK \n")
x <- read_html(x = httr::content(allGetResponse[[s]], "text")) #objet html
#if (is.na(x)) x <- read_html(x = httr::content(allGetResponse[[s]], "raw")) #objet brut
if (!is.na(x)) {
#Sauvegarde dans un fichier
#cat("on sauvegarde le fichier \n")
filename<-paste(domain,"-",obs_domain_id,".html")
filepath<-paste(path,"/",filename, sep = "")
#cat("myEncod", MyEncod, "!!\n")
#cat("classe de x", class(x), "!!\n")
write_html(x,filepath)
#Parsing !!! Ici rechercher les liens si c'est autorisé et page interne.
#x <- read_html(x = content(allGetResponse[[s]], "text")) #objet html #déjà plus haut
links<-xml2::xml_find_all(x, "//a/@href") #trouver les liens
links<-as.vector(paste(links)) #Vectorisation des liens
links<-gsub(" href=\"(.*)\"", "\\1", links) #on vire href
#Va récupérer les liens normalisés.
links<-NetworkLinkNormalization(links,TheUrl) #revient avec les protocoles http/https sauf liens mailto etc.
#on ne conserve que les liens avec http / https
links<-links[links %like% "http" ]
# Ignore Url parameters
links<-sapply(links , function(x) Linkparamsfilter(x, ignoreUrlParams), USE.NAMES = FALSE)
# Link robots.txt filter #non pertinent ici
#if (!missing(urlbotfiler)) links<-links[!links %like% paste(urlbotfiler,collapse="|") ]
#Récupération des liens internes et des liens externes
IntLinks <- vector() #Vecteur des liens internes
ExtLinks <- vector() #Vecteur des liens externes.
if(length(links)!=0) {
for(iLinks in 1:length(links)){
if (!is.na(links[iLinks])){
#limit length URL to 255
if( nchar(links[iLinks])<=URLlenlimit) {
ext<-tools::file_ext(sub("\\?.+", "", basename(links[iLinks])))
#Filtre eliminer les liens externes , le lien source lui meme, les lien avec diese ,
#les types de fichier filtrer, les liens tres longs , les liens de type share
#if(grepl(domain,links[iLinks]) && !(links[iLinks] %in% IntLinks) && !(ext %in% urlExtfilter)){
#Finalement on garde les liens déjà dans dans la liste
#(c'est à iGraph de voir si on souhaite simplifier le graphe)
if(grepl(domain,links[iLinks]) && !(ext %in% urlExtfilter)){ #on n'enlève que les liens hors domaine et à filtrer.
#C'est un lien interne
IntLinks<-c(IntLinks,links[iLinks])
} #/if(grepl(domain,links[iLinks]) && !(ext %in% urlExtfilter))
else {
#C'est un lien externe
ExtLinks<-c(ExtLinks,links[iLinks])
} #/else pour liens externes
} #if( nchar(links[iLinks])<=URLlenlimit)
} #/if (!is.na(links[iLinks]))
} #/for(iLinks in 1:length(links))
} #/if(length(links)!=0)
#Sauvegarde du nombre de liens internes sur la page parsée
pkg.env$GraphNodes[t+s-1, "NbIntLinks"] <- length(IntLinks)
#Sauvegarde du nombnre de liens externes sur la page parsée
pkg.env$GraphNodes[t+s-1, "NbExtLinks"] <- length(ExtLinks)
pkg.env$GraphNodes[t+s-1, "MyStatusPage"] <- "parsed"
TotalPagesParsed <- TotalPagesParsed + 1 #Total des pages parsées (pour info)
} #/if (!is.na(x))
} #/ if (!grepl("empty-page",tc))
} #/if (grepl("html",pkg.env$GraphNodes[t+s-1, "headers.content_type"]))
} #/if (is.null(allGetResponse[[s]]$status_code))
} #/if (!is.null(allGetResponse[[s]]))
} #/for (s in 1:length(allGetResponse))
cat("Crawl with GET :",format(round((t/nrow(pkg.env$GraphNodes)*100), 2),nsmall = 2),"% : ",t,"to",l,"crawled from ",nrow(pkg.env$GraphNodes)," Parsed:", TotalPagesParsed-1, "\n")
t<-l+1 #Paquet suivant
#Sauvegarde des données vers l'environnement global au fur et à mesure
assign("UrlsCrawled", pkg.env$GraphNodes, envir = as.environment(1) ) #Idem Nodes
} #/while (t<=nrow(pkg.env$graphNodes)
#Arret des clusters.
stopCluster(cl)
stopImplicitCluster()
rm(cl)
cat("+ Urls Crawled plus parameters are stored in a variable named : UrlsCrawled \n")
} #/YoodaNetworkRcrawler
########################################################################################
Préparation des urls à crawler
Comme notre jeu de données comporte plusieurs fois les mêmes urls, nous allons extraire celles-ci afin de ne crawler qu’une seule fois chaque page. N’oubliez pas de dézipper le fichier AllDataKeywords.csv dans le répertoire courant de votre projet R.
#
#
############################################################################################
####### On démarre ici en récupérant le AllDataKeywords.csv précédent
AllDataKeywords <- read.csv2(file = "AllDataKeywords.csv")
#on ne va garder que les pages html (à priori) on filtre les extensions qui ne nous intéressent pas.
urlExtfilter<-c("flv","mov","swf","txt","xml","js","css","zip","gz","rar","7z","tgz","tar","z","gzip",
"bzip","tar","mp3","mp4","aac","wav","au","wmv","avi","mpg","mpeg","pdf","doc","docx",
"xls","xlsx","ppt","pptx","jpg","jpeg","png","gif","psd","ico","bmp","odt","ods","odp",
"odb","odg","odf")
str(AllDataKeywords) #154979 obs
HTMLDataKeywords <- AllDataKeywords[which(!(tools::file_ext(stringr::str_sub(AllDataKeywords$url,-255,-1)) %in% urlExtfilter)), ]
str(HTMLDataKeywords) #154940
rm(AllDataKeywords) #on récupère un peu de place
##### on ne va crawler qu'une fois les pages HTML
UrlsToCrawl <- data.frame(url = as.character(unique(HTMLDataKeywords$url)))
str(UrlsToCrawl) #Oups qd même 49229 obs #et il m'a remis en factor ????
UrlsToCrawl$url <- as.character(UrlsToCrawl$url) #force en caracteres
str(UrlsToCrawl)
#on récupere les données domain, domain_id et obs_domain_id dont on a besoin dasn YoodaUrlsNetworkRcrawler
UrlsToCrawl <- join(x=UrlsToCrawl, y=HTMLDataKeywords[, c("domain", "domain_id", "obs_domain_id", "url")], by = "url", type = "left", match="first")
UrlsToCrawl$domain <- as.character(UrlsToCrawl$domain)
str(UrlsToCrawl)
#########
#Sauvegarde de HTMLDataKeywords et libération de mémoire
write.csv2(HTMLDataKeywords, file = "HTMLDataKeywords.csv", row.names = FALSE) #ecriture avec sep ";" sans numéro de ligne.
rm(HTMLDataKeywords) #liberation de memoire
Comme vous pouvez le constater, nous avons quand même 49229 pages à crawler !!! Ce qui peut durer toute la nuit ! On veille aussi à libérer de la mémoire en sauvegardant sur le disque dur les jeux de données intermédiaires qui ne sont pas utiles tout de suite. Le crawl est gourmand en mémoire !
Notez aussi que l’on ne va s’intéresser qu’aux pages HTML. Il peut y avoir des documents en d’autres formats : .zip, .pdf, .doc… En effet, dans un prochain article on s’intéressera au contenu et aux balises des pages.
Crawl des Urls
Afin de faciliter le crawl et d’éviter de devoir tout refaire en cas de plantage, nous avons décidé de diviser en paquet de 5000 les urls. Les résultats sont sauvegardés dans des fichiers intermédiaires sur le disque dur. Si le système se bloque, vous pouvez diminuer la quantité d’urls par paquet en fonction de la mémoire de votre ordinateur. (j’ai 12 GO De RAM).
#
#
###############################################################################
### Crawl des URLS pour récuperer des donnéess "on page" complémentaires
# on va utiliser notre crawler écrit précédemment que l'on va modifier.
##############################################################################
#on va spliter le dataframe à crawler s'il est > 5000 obs.
chunk <- 5000
n <- nrow(UrlsToCrawl)
r <- rep(1:ceiling(n/chunk),each=chunk)[1:n]
if (n > chunk) {
ListUrlsToCrawl <- split(UrlsToCrawl,r)
} else {
ListUrlsToCrawl <- list(UrlsToCrawl)
}
##############
str(ListUrlsToCrawl)
rm(UrlsToCrawl) #liberation de memoire
for(numList in 1:length(ListUrlsToCrawl) ) {
gc() #vider la mémoire
YoodaUrlsNetworkRcrawler (Urls = ListUrlsToCrawl[[numList]], no_cores = 8, no_conn = 8,
Obeyrobots = FALSE,
Timeout = 5, # Timeout = 5 par défaut
Useragent = "Mozilla/5.0 (Windows NT 6.3; Trident/7.0; rv:11.0) like Gecko",
NetwExtLinks = TRUE,
MaxPagesParsed = 5000) #on limite à 5000 pour préserver la mémoire
#on sauvegarde les UrlsCrawled au fur et à mesure sur le disque dur
MyFileName <- paste("UrlsCrawled", "-",numList,".csv", sep="")
write.csv2(UrlsCrawled, file = MyFileName, row.names = FALSE) #Ecriture du fichier .csv avec séparateur ";" sans numéro de ligne.
gc() #vider la mémoire
}
######liberation de memoire
rm(ListUrlsToCrawl)
rm(UrlsCrawled)
#Recupération des données d'URls en une seule data.frame à partir des fichiers.
#lecture des fichiers de positionnements par domaines
UrlsCrawledFiles <- list.files(path = ".", pattern = "UrlsCrawled-.*\\.csv$")
AllUrlsCrawledFiles <- lapply(UrlsCrawledFiles,function(i){
read.csv(i, check.names=FALSE, header=TRUE, sep=";", quote="\"")
})
class(AllUrlsCrawledFiles) #C'est une liste
str(AllUrlsCrawledFiles) #verif
#for (i in 1:length(AllUrlsCrawledFiles)) cat("i=",i," nombre de colonnes:", ncol(AllUrlsCrawledFiles[[i]]))
AllUrlsCrawledData <- do.call(rbind, AllUrlsCrawledFiles) #transformation en data.frame
#rm(AllUrlsCrawledFiles) #pour faire de la place mémoire
#Sauvegarde
write.csv2(AllUrlsCrawledData, file = "AllUrlsCrawledData.csv", row.names = FALSE)
Exploration des données
Si vous n’avez pas pu crawler les pages, vous pouvez récupérer le fichier au format .zip ici : AllUrlsCrawledData.zip. N’oubliez-pas de le dézipper dans le répertoire courant de votre projet R.
Dans cette partie, nous allons examiner toutes les variables qui ont été récupérées précédemment pour chaque page. Ceci permettra de sélectionner et éventuellement transformer celles qui nous intéressent. Vous n’êtes pas obligés de faire les mêmes choix que moi.
#
#
#############################################################################
### Examinons ce que nous avons trouvé - Exploration des données
#############################################################################
AllUrlsCrawledData <- read.csv2(file = "AllUrlsCrawledData.csv")
str(AllUrlsCrawledData) #description de la structure du dataframe
#Status_code
plyr::count(as.factor(AllUrlsCrawledData$status_code)) #330 NA à virer ensuite ! 49010 200 on ne conserve que les 200 ??? Oui
###########################################################
#headers.set.cookie - voyons ce qu'il y a dans le cookie
###########################################################
str(AllUrlsCrawledData$headers.set_cookie)
#device view ???
device_view <- lapply(tolower(as.character(AllUrlsCrawledData$headers.set_cookie)), str_match , pattern = "device_view=(.*?);")
str(device_view)
headers.set.cookie.device_view <- vector()
for (i in 1:length(device_view)) { headers.set.cookie.device_view[i] <- device_view[[i]][2] }
str(headers.set.cookie.device_view)
rm(device_view) #on fait de la place mémoire
rm(headers.set.cookie.device_view) #on fait de la place mémoire
#plyr::count(headers.set.cookie.device_view) #7full et 49222 NA -> pas intéressant pas assez de données
##### /device view
#expires???
expires <- lapply(as.character(AllUrlsCrawledData$headers.set_cookie), str_match , pattern = "expires=(.*?);")
#str(expires)
headers.set.cookie.expires <- vector()
for (i in 1:length(expires)) { headers.set.cookie.expires[i] <- expires[[i]][2] }
plyr::count(!is.na(headers.set.cookie.expires)) #12147 TRUE avec qqchose à comparer avec headers.date ou voir max-age
rm(expires) #on fait de la place mémoire
#on le garde pour pour l'instant - on va utiliser un max-age recalculé !!!
##### /expires
#max-age ??? durée déclaré dans le cookie
max_age <- lapply(tolower(as.character(AllUrlsCrawledData$headers.set_cookie)), str_match , pattern = "max-age=(.*?);")
#str(max_age)
headers.set.cookie.max_age <- vector()
for (i in 1:length(max_age)) { headers.set.cookie.max_age[i] <- max_age[[i]][2] }
str(headers.set.cookie.max_age)
summary(as.numeric(headers.set.cookie.max_age))
plyr::count(!is.na(headers.set.cookie.max_age)) #7526 TRUE et 41703 NA -> à voir
rm(max_age) #on fait de la place mémoire
#on va utiliser un max-age recalculé !!! voir plus bas avec la date. à garder.
##### /max-age
#Domain ??? nom de domaine indiqué dans le Cookie
cookie.domain <- lapply(tolower(as.character(AllUrlsCrawledData$headers.set_cookie)), str_match , pattern = "domain=(.*?);")
#str(cookie.domain)
headers.set.cookie.domain <- vector()
for (i in 1:length(cookie.domain)) { headers.set.cookie.domain[i] <- cookie.domain[[i]][2] }
str(headers.set.cookie.domain)
plyr::count(headers.set.cookie.domain) #21 type dont 42630 en NA peut être intéressant pour voir si un domaine déclaré
#a un plus. -> transformer en booleen pour éviter les NA
#on prend !!!!!!
AllUrlsCrawledData$headers.set.cookie.domain.provided <- ifelse(!is.na(headers.set.cookie.domain), 1,0)
plyr::count(AllUrlsCrawledData$headers.set.cookie.domain.provided) #verif
#libération de mémoire.
rm(cookie.domain)
rm(headers.set.cookie.domain)
#/Domain ???
#cookie path ??? nom de domaine indiqué dans le Cookie
cookie.path <- lapply(tolower(as.character(AllUrlsCrawledData$headers.set_cookie)), str_match , pattern = "path=(.*?);")
#str(cookie.path)
headers.set.cookie.path <- vector()
for (i in 1:length(cookie.path)) { headers.set.cookie.path[i] <- cookie.path[[i]][2] }
#str(headers.set.cookie.path)
plyr::count(headers.set.cookie.path) #4 types dont 40485 en NA peut être intéressant pour voir si un path déclaré a un plus ???
#On Prend en booléen
AllUrlsCrawledData$headers.set.cookie.path.provided <- ifelse(!is.na(headers.set.cookie.path)
& !is.null(headers.set.cookie.path),1,0)
plyr::count(AllUrlsCrawledData$headers.set.cookie.path.provided)
#libération de mémoire
rm(cookie.path)
rm(headers.set.cookie.path)
#/cookie path
#httponly ??? httponly indiqué dans le Cookie
cookie.httponly <- lapply(tolower(as.character(AllUrlsCrawledData$headers.set_cookie)), str_match , pattern = "httponly")
#str(cookie.httponly)
headers.set.cookie.httponly <- vector()
for (i in 1:length(cookie.httponly)) { headers.set.cookie.httponly[i] <- cookie.httponly[[i]][1] } #ici le 1
#str(headers.set.cookie.httponly)
plyr::count(headers.set.cookie.httponly) #2 types dont 41173 en NA peut être intéressant pour voir si httponly a un plus ???
#On Prend sou forme booleen pour éviter les NA
AllUrlsCrawledData$headers.set.cookie.httponly.provided <- ifelse(!is.na(headers.set.cookie.httponly),1,0)
plyr::count(AllUrlsCrawledData$headers.set.cookie.httponly.provided)
#liberation de memoire
rm(cookie.httponly)
rm(headers.set.cookie.httponly)
#/httponly
#secure ??? secure indiqué dans le Cookie
cookie.secure <- lapply(tolower(as.character(AllUrlsCrawledData$headers.set_cookie)), str_match , pattern = "secure")
#str(cookie.secure)
headers.set.cookie.secure <- vector()
for (i in 1:length(cookie.secure)) { headers.set.cookie.secure[i] <- cookie.secure[[i]][1] } #ici le 1
#str(headers.set.cookie.secure)
plyr::count(headers.set.cookie.secure) #2 types dont 44249 en NA peut être intéressant pour voir si secure a un plus ???
#On Prend sous forme booleen pour éviter les NA.
AllUrlsCrawledData$headers.set.cookie.secure.provided <- ifelse(!is.na(headers.set.cookie.secure),1,0)
plyr::count(AllUrlsCrawledData$headers.set.cookie.secure.provided)
#liberation de memoire
rm(cookie.secure)
rm(headers.set.cookie.secure)
#/secure
#######################################################################################
#headers.date - voyons ce qu'il y a dans la date du header pour récupperer un max_age
#########################################################################################
headers.date.POSIXct <- parse_date_time(AllUrlsCrawledData$headers.date, orders="a, d-b-Y H:M:S", tz="GMT", locale="us")
#str(headers.date.POSIXct)
plyr::count(!is.na(headers.date.POSIXct))
#récupérons la date d'expiration du cookie en POSIXct
headers.set.cookie.expires.POSIXct <- parse_date_time(headers.set.cookie.expires,
orders="a, d-b-Y H:M:S", tz="GMT",
locale="us")
#str(headers.set.cookie.expires.POSIXct)
plyr::count(!is.na(headers.set.cookie.expires.POSIXct))
#Voyons la différence : il ne prend calcule que si les 2 variables ne sont pas en NA.
headers.diff.dates <- as.vector(difftime(headers.set.cookie.expires.POSIXct, headers.date.POSIXct, unit="secs"))
#str(headers.diff.dates)
#plyr::count(headers.diff.dates)
plyr::count(!is.na(headers.diff.dates)) #on a 12129
plyr::count(!is.na(headers.set.cookie.max_age))
headers.set.cookie.max_age <- as.numeric(headers.set.cookie.max_age)
headers.diff.dates2 <- numeric()
#on privilégie max_age
for (i in 1:length(headers.diff.dates)) {
headers.diff.dates2[i] <- headers.diff.dates[i]
if (!is.na(headers.set.cookie.max_age[i])) {
#cat("max age",headers.set.cookie.max_age[i], "\n")
#cat("diff dates",headers.set.cookie.max_age[i], "\n")
headers.diff.dates2[i] <- headers.set.cookie.max_age[i]
}
}
plyr::count(!is.na(headers.diff.dates2)) #on a toujours 12129
class(headers.diff.dates2)
class(headers.diff.dates)
plyr::count(headers.diff.dates2 == headers.diff.dates) #mais on a 1131 de différents.
#On détermine un max-age par défaut si non indiqué : 20 mns (pour une session) soit 1200 secondes. Remarque normalement
#c'est jusqu'à ce que le browser soit fermé.
headers.diff.dates2 <- ifelse(is.na(headers.diff.dates2), 1200,headers.diff.dates2 )
plyr::count(headers.diff.dates2)
#on traite les max-age négatifs de la même façon à savoir 1200 secondes
headers.diff.dates2 <- ifelse(headers.diff.dates2<0, 1200,headers.diff.dates2 )
plyr::count(headers.diff.dates2)
#on le récupère
AllUrlsCrawledData$headers.set.cookie.max_age <- headers.diff.dates2
#liberation de mémoire
rm(headers.set.cookie.expires)
rm(headers.set.cookie.expires.POSIXct)
rm(headers.date.POSIXct)
rm(headers.set.cookie.max_age)
rm(headers.diff.dates)
rm(headers.diff.dates2)
#/headers.date - > max_age
#######################################################################################
# headers.content_type.content_type
#######################################################################################
str(AllUrlsCrawledData) #affiche les variables
plyr::count(AllUrlsCrawledData$headers.content_type)
#
headers.content_type.content_type <- vector()
for (i in 1:nrow(AllUrlsCrawledData) ) {
headers.content_type.content_type[i] <- unlist(strsplit(tolower(as.character(AllUrlsCrawledData$headers.content_type[i])), split = ";" ))[1]
}
head(headers.content_type.content_type)
plyr::count(headers.content_type.content_type)
#on prend headers.content_type.content_type pour pouvoir sélectionner uniquement les urls en text/html par la suite
AllUrlsCrawledData$headers.content_type.content_type <- headers.content_type.content_type
#liberation de mémoire
rm(headers.content_type.content_type)
# /headers.content_type.content_type
#######################################################################################
# headers.Content type.encoding - ok bon
#######################################################################################
plyr::count(AllUrlsCrawledData$headers.content_type.encoding)
#pour regrouper les facteurs on passe tout en minuscule.
headers.content_type.encoding <- tolower(AllUrlsCrawledData$headers.content_type.encoding)
plyr::count(headers.content_type.encoding)
#headers.content_type.encoding <- ifelse(is.na(headers.content_type.encoding), "",headers.content_type.encoding)
#plyr::count(headers.content_type.encoding)
#on remplace avec le contenu regroupé.
AllUrlsCrawledData$headers.content_type.encoding <- as.factor(headers.content_type.encoding)
str(AllUrlsCrawledData)
#liberation de mémoire
rm(headers.content_type.encoding)
# / headers.Content type.encoding
#######################################################################################
# headers.transfer_encoding.provided - chunked ou non
#######################################################################################
#en savoir plus https://fr.wikipedia.org/wiki/Chunked_transfer_encoding
#a à voir dans l'accélérattion du chargement de la page.
plyr::count(AllUrlsCrawledData$headers.transfer_encoding)
#On Prend sous forme booleen pour éviter les NA
AllUrlsCrawledData$headers.transfer_encoding.provided <- ifelse(!is.na(AllUrlsCrawledData$headers.transfer_encoding),1,0)
plyr::count(AllUrlsCrawledData$headers.transfer_encoding.provided)
str(AllUrlsCrawledData)
#/ headers.transfer_encoding.provided
#######################################################################################
# headers.connection
#######################################################################################
plyr::count(AllUrlsCrawledData$headers.connection)
#on garde tel que
#/ headers.connection
#######################################################################################
# headers.server on va regrouper les serveurs par familles pour être plus lisibles.
#######################################################################################
plyr::count(AllUrlsCrawledData$headers.server)
#on va faire des familles
headers.server.family <- tolower(AllUrlsCrawledData$headers.server)
headers.server.family <- ifelse(grepl("apache",headers.server.family), "apache", headers.server.family)
headers.server.family <- ifelse(grepl("cloudflare|odiso|reblaze",headers.server.family), "cloud", headers.server.family)
headers.server.family <- ifelse(grepl("gunicorn",headers.server.family), "gunicorn", headers.server.family)
headers.server.family <- ifelse(grepl("microsoft-iis",headers.server.family), "microsoft-iis", headers.server.family)
headers.server.family <- ifelse(grepl("nginx|openresty",headers.server.family), "nginx", headers.server.family)
plyr::count(headers.server.family)
AllUrlsCrawledData$headers.server.family <- as.factor(headers.server.family)
#liberation de mémoire
rm(headers.server.family)
# / headers.server
#######################################################################################
# headers.x_powered_by pour l'instant rien beaucoup de NA
#######################################################################################
plyr::count(AllUrlsCrawledData$headers.x_powered_by)# 43775 beaucoup de NA !!!!
str(AllUrlsCrawledData)
#######################################################################################
# headers.p3p - pour l'instant rien beaucoup de NA
#######################################################################################
plyr::count(AllUrlsCrawledData$headers.p3p) # NA = 42502 beaucoup de NA !!!!
str(AllUrlsCrawledData)
#######################################################################################
# headers.vary on éclate en 4 variables booléennes
#######################################################################################
plyr::count(AllUrlsCrawledData$headers.vary) # voyons voir
AllUrlsCrawledData$headers.vary.accept_encoding <- ifelse(grepl(pattern = "accept-encoding", tolower(AllUrlsCrawledData$headers.vary)), 1, 0)
plyr::count(AllUrlsCrawledData$headers.vary.accept_encoding)
AllUrlsCrawledData$headers.vary.user_agent <- ifelse(grepl(pattern = "user-agent", tolower(AllUrlsCrawledData$headers.vary)), 1, 0)
plyr::count(AllUrlsCrawledData$headers.vary.user_agent)
AllUrlsCrawledData$headers.vary.cookie <- ifelse(grepl(pattern = "cookie", tolower(AllUrlsCrawledData$headers.vary)), 1, 0)
plyr::count(AllUrlsCrawledData$headers.vary.cookie)
AllUrlsCrawledData$headers.vary.host <- ifelse(grepl(pattern = "host", tolower(AllUrlsCrawledData$headers.vary)), 1, 0)
plyr::count(AllUrlsCrawledData$headers.vary.host)
str(AllUrlsCrawledData) #verif
#/ headers.vary
#######################################################################################
# headers.accept_ranges
#######################################################################################
plyr::count(AllUrlsCrawledData$headers.accept_ranges)
AllUrlsCrawledData$headers.accept_ranges.bytes <- ifelse(grepl(pattern = "bytes", tolower(AllUrlsCrawledData$headers.accept_ranges)), 1, 0)
str(AllUrlsCrawledData)
#######################################################################################
# headers.link - pas utilisé
#######################################################################################
plyr::count(AllUrlsCrawledData$headers.link)
str(AllUrlsCrawledData)
#######################################################################################
# headers.content_encoding - tout le monde en gzip cela ne va pas être parlant
#######################################################################################
plyr::count(AllUrlsCrawledData$headers.content_encoding) #quasi tout le monde en gzip !!!
str(AllUrlsCrawledData)
#######################################################################################
# headers.x_ipbl_instance - tout le monde à 0 !!!!
#######################################################################################
plyr::count(AllUrlsCrawledData$headers.x_ipbl_instance)
summary(AllUrlsCrawledData$headers.x_ipbl_instance)
str(AllUrlsCrawledData)
#######################################################################################
# headers.cache_control à diviser !!! on prend juste max_age.
#######################################################################################
plyr::count(AllUrlsCrawledData$headers.cache_control)
######## headers.cache_control.max_age.value
#on extrait d'abord max_age=xxxx
headers.cache_control.max_age <- vector()
for (i in 1:nrow(AllUrlsCrawledData)) {
headers.cache_control.max_age[i] <- str_extract(as.character(AllUrlsCrawledData[i,"headers.cache_control"]), "max-age=[0-9]+")
}
str(headers.cache_control.max_age)
#puis on extrait la valeur xxxx
headers.cache_control.max_age.value <- numeric()
for (i in 1:length(headers.cache_control.max_age)) {
headers.cache_control.max_age.value[i] <- str_extract(as.character(headers.cache_control.max_age[i]), "[0-9]+")
}
plyr::count(headers.cache_control.max_age.value)
#on prend
AllUrlsCrawledData$headers.cache_control.max_age.value <- headers.cache_control.max_age.value
#libération de mémoire
rm(headers.cache_control.max_age)
rm(headers.cache_control.max_age.value)
######## / headers.cache_control.max_age.value
#On arrête ici pour headers.cache_control
#######################################################################################
# All_headers.status - finalement beaucoup de 200 donc peu explicatif. pas intéressant
#######################################################################################
plyr::count(AllUrlsCrawledData$all_headers.status) #on prend en facteur pour voir !!!
AllUrlsCrawledData$all_headers.status <- as.factor(AllUrlsCrawledData$all_headers.status)
str(AllUrlsCrawledData)
#######################################################################################
# all_headers.version - version du http
#######################################################################################
plyr::count(AllUrlsCrawledData$all_headers.version) #pratiquement tout le monde en http:/1.1
#pas intéressant.
str(AllUrlsCrawledData)
#######################################################################################
# content_length - taille du contenu
#######################################################################################
summary(AllUrlsCrawledData$content_length)
#on prend tel que
#######################################################################################
# times #on prend tel que
#######################################################################################
#times.redirect : num 0 0 3.16 0 0 ...
#times.namelookup : num 0.5 0.703 0 0.61 0.563 0.265 0.234 0.125 0 0 ...
#times.connect : num 0.562 0.75 0 0.672 0.625 0.328 0.297 0.188 0 0 ...
#times.pretransfer : num 2.88 3.19 0 4 4.02 ...
#times.starttransfer : num 3.25 3.7 0.5 4.78 4.69 ...
#times.total
#on sauvegarde le nouveau AllUrlsCrawledData préparé
write.csv2(AllUrlsCrawledData, file = "AllUrlsCrawledDataPrepared.csv", row.names = FALSE)
#### Fin exploration / sélection / création de variables.
Récupération des données de pages dans le data.frame des positions.
Nous allons maintenant récupérer les données sur les pages dans le jeu de données principal qui contient les informations de positions.
# # ############################################################################# ### Enrichissement du fichier de positions global avec les données de pages ############################################################################# AllUrlsCrawledData <- read.csv2(file = "AllUrlsCrawledDataPrepared.csv") HTMLDataKeywords <- read.csv2(file = "HTMLDataKeywords.csv") str(HTMLDataKeywords) #on vire de AllUrlsCrawledData les colonnes qui sont aussi dans HRMLDatakeywords : #domain, obs_domain_id, domain_id str(AllUrlsCrawledData) AllUrlsCrawledData2 <- AllUrlsCrawledData[, -(2:4)] str(AllUrlsCrawledData2) #Merge HTMLDataKeywords avec AllUrlsCrawledData2. #remet le nom AllDataKeywords pour ne pas avoir à refaire le reste. AllDataKeywords <- merge(HTMLDataKeywords, AllUrlsCrawledData2, by = "url") str(AllDataKeywords) #verif #on ne garde que les statuts à 200. AllDataKeywords <- AllDataKeywords[which(AllDataKeywords$status_code == 200),] str(AllDataKeywords) #verif #149438 observations #on ne garde que les "headers.content_type.content_type" en "text/html" AllDataKeywords <- AllDataKeywords[which(AllDataKeywords$headers.content_type.content_type == "text/html"),] str(AllDataKeywords) write.csv2(AllDataKeywords, file = "YoodaTechDataKeywords.csv", row.names = FALSE) #liberation de mémoire rm(AllUrlsCrawledData) rm(AllUrlsCrawledData2) rm(HTMLDataKeywords) plyr::count(AllDataKeywords$istop3pos) #verif presque moitié moitié. write.csv2(AllDataKeywords, file = "YoodaTechDataKeywords.csv", row.names = FALSE)
Sélection des variables pour XGBoost
On sélectionne les variables explicatives que l’on souhaite tester à partir de l’exploration précédente.
#
#
#############################################################################
### Machine Learning sur les données intéressantes
#############################################################################
#############################################################################
### Creation du fichier de données à tester, de train et de test
#### Sélection des variables (passage 1)
#############################################################################
AllDataKeywords <- read.csv2( file = "YoodaTechDataKeywords.csv") #données pour passage 1
######################
str(AllDataKeywords) #verif des donnnées disponibles.
# Variable à expliquer
(outcome <- "istop3pos") #utilisé avec XGBoost
# Variables explicatives #utilisé avec XGBoost
(vars <- c("kwindomain", "kwinurl", "ishttps", "isSSLEV", "urlnchar", "urlslashcount",
"headers.content_type.encoding", "headers.connection", "headers.server.family",
"headers.set.cookie.domain.provided",
"headers.set.cookie.path.provided", "headers.set.cookie.httponly.provided",
"headers.set.cookie.secure.provided", "headers.set.cookie.max_age",
"headers.transfer_encoding.provided", "headers.vary.accept_encoding",
"headers.vary.user_agent", "headers.vary.cookie", "headers.vary.host",
"headers.accept_ranges.bytes", "headers.cache_control.max_age.value",
"all_headers.status", "content_length", "times.redirect", "times.namelookup", "times.connect",
"times.pretransfer", "times.starttransfer", "times.total", "NbIntLinks", "NbExtLinks"))
Création du « train » et du « test »
On va créer les données d’entrainement et de test nécessaires au modèle.
# # ############################################################################## # Données à étudier (Passage 1 et 2) ############################################################################## #Selection des variables. Urlcoltokeep <- c(outcome, vars) UrlDataKeywords <- AllDataKeywords[, Urlcoltokeep] str(AllDataKeywords) #verif str(UrlDataKeywords) #verif #Decoupage en train et test ## 70% of the sample size smp_size <- floor(0.70 * nrow(UrlDataKeywords)) ## set the seed to make your partition reproductible set.seed(12345) train_ind <- sample(seq_len(nrow(UrlDataKeywords)), size = smp_size) train <- UrlDataKeywords[train_ind, ] test <- UrlDataKeywords[-train_ind, ] str(train) #verif str(test) #verif #liberation demémoire rm(Urlcoltokeep) rm(UrlDataKeywords) rm(AllDataKeywords)
Modèle XGBoost
On va préparer les données et lancer le modèle XGBoost
#
#
#######################################################################################
# XGBoost sur istop3pos
########################################################################################
#Traitements préalables des données pour être utilisées par XGBoost
# Création d'un "plan de traitement" à partir de train (données d'entrainement)
# ici le système va créer des variables supplémentaires booléennes pour différents niveaux de facteurs dans les
# variables originales : "one hot Encoding"
treatplan <- designTreatmentsZ(train, vars, verbose = TRUE)
#str(treatplan)
# On récupère les variables "clean" et "lev" du scoreFrame : treatplan$scoreframe
(newvars <- treatplan %>%
use_series(scoreFrame) %>%
filter(code %in% c("clean","lev")) %>% # get the rows you care about
use_series(varName)) # get the varName column
# Preparation des données d'entrainement à partir du plan de traitement créé précédemment
train.treat <- prepare(treatmentplan = treatplan, dframe = train , varRestriction = newvars)
# Preparation des données de test à partir du plan de traitement créé précédemment
test.treat <- prepare(treatmentplan = treatplan, dframe = test, varRestriction = newvars)
str(train.treat)
str(test.treat)
# on commence par faire tourner xgb.cv pour déterminer le nombre d'arbres optimal.
cv <- xgb.cv(data = as.matrix(train.treat),
label = train$istop3pos,
nrounds = 1000,
nfold = 5,
objective = "binary:logistic",
eta = 0.3,
max_depth = 6,
early_stopping_rounds = 100,
verbose = 1 # silent
)
#str(cv)
#pour regression linéaire objective = "reg:linear",
#pour binaire objective = "binary:logistic",
# Get the evaluation log
elog <- cv$evaluation_log
str(elog)
# Determinatiion du nombre d'arbres qui minimise l'erreur sur le jeu de train et le jeu de test
(Twotreesvalue <- elog %>%
summarize(ntrees.train = which.min(train_error_mean), # find the index of min(train_rmse_mean)
ntrees.test = which.min(test_error_mean)) ) # find the index of min(test_rmse_mean)
#on prend le plus petit des 2
ntrees = min(Twotreesvalue$ntrees.train, Twotreesvalue$ntrees.test)
# The number of trees to use, as determined by xgb.cv
ntrees #passage 1 : 662 ; avec 75000 enr. 328
# Run xgboost
xgbmod <- xgboost(data = as.matrix(train.treat), # training data as matrix
label = train$istop3pos, # column of outcomes
nrounds = ntrees, # number of trees to build
objective = "binary:logistic", # objective
eta = 0.3,
depth = 6,
verbose = 1 # affichage ou non
)
#Predictions
pred.xgbmod <-predict(xgbmod, as.matrix(test.treat))
#Matrice de Confusion
table(round(pred.xgbmod) , test$istop3pos)
mean(round(pred.xgbmod) == test$istop3pos) ###
#ROC et AUC
ROC <- roc(test$istop3pos, pred.xgbmod)
AUC <- auc(ROC) #passage 1 : 0.7851, extrait de 75000 : 0,7669
# Plot the ROC curve
plot(ROC, col = "blue")
text(0.5,0.5,paste("AUC = ",format(AUC, digits=5, scientific=FALSE)))
text(0.6, 1, "ROC-AUC Modèle XGBoost Données Yooda + Techniques Pages", col="red", cex=0.7)
#importance #c'est le gain qui nous intéresse !
(importance <- xgb.importance(feature_names = colnames(x = train.treat), model = xgbmod))
Pour info le nombre d’arbres ou d’itérations optimal pour ce jeu de données est 702.

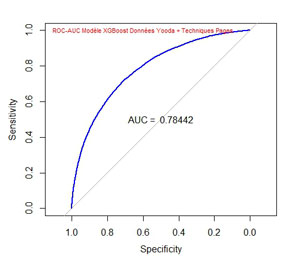
La courbe ROC et l’AUC sont les suivantes :
L’AUC (Area under the curve) est ici de 0,78442 par rapport à 0,66097 ce qui améliore considérablement la validité du modèle
l’importance des variables est la suivante :
Feature Gain
1: content_length_clean 2.117932e-01
2: NbIntLinks_clean 1.516675e-01
3: times.starttransfer_clean 1.196500e-01
4: urlnchar_clean 1.040387e-01
5: NbExtLinks_clean 7.338380e-02
6: times.total_clean 7.196810e-02
7: urlslashcount_clean 4.387834e-02
8: headers.transfer_encoding.provided_clean 2.017011e-02
9: ishttps_clean 1.693336e-02
10: headers.connection_lev_x.keep.alive 1.671510e-02
11: times.pretransfer_clean 1.404700e-02
12: times.connect_clean 1.345248e-02
13: times.redirect_clean 1.198297e-02
14: headers.server.family_lev_x.nginx 1.090950e-02
15: kwinurl_clean 1.014609e-02
16: isSSLEV_clean 1.000471e-02
17: headers.server.family_lev_x.apache 9.713127e-03
18: headers.set.cookie.max_age_clean 8.888817e-03
19: headers.connection_lev_NA 7.886618e-03
20: headers.accept_ranges.bytes_clean 7.669600e-03
21: headers.vary.user_agent_clean 7.633505e-03
22: headers.set.cookie.domain.provided_clean 7.595291e-03
23: times.namelookup_clean 7.231314e-03
24: headers.vary.accept_encoding_clean 6.922125e-03
25: headers.cache_control.max_age.value_lev_x.0 4.725493e-03
26: headers.server.family_lev_NA 4.340520e-03
27: headers.cache_control.max_age.value_lev_x.120 3.373820e-03
28: headers.set.cookie.path.provided_clean 3.018192e-03
29: headers.content_type.encoding_lev_x.iso.8859.1 2.324668e-03
30: headers.server.family_lev_x.cloud 2.193010e-03
31: headers.cache_control.max_age.value_lev_NA 2.187461e-03
32: headers.content_type.encoding_lev_NA 2.153618e-03
33: headers.set.cookie.secure.provided_clean 2.105665e-03
34: headers.server.family_lev_x.gunicorn 1.611823e-03
35: all_headers.status_lev_x.200 1.590576e-03
36: headers.content_type.encoding_lev_x.utf.8 1.331743e-03
37: all_headers.status_lev_x.301 1.168175e-03
38: headers.connection_lev_x.close 1.131894e-03
39: headers.cache_control.max_age.value_lev_x.360 1.036583e-03
40: kwindomain_clean 8.142906e-04
41: headers.set.cookie.httponly.provided_clean 3.158085e-04
42: headers.cache_control.max_age.value_lev_x.1200 1.450235e-04
43: headers.vary.cookie_clean 8.187216e-05
44: headers.vary.host_clean 5.415452e-05
45: headers.content_type.encoding_lev_x.iso.8859.15 1.417488e-05
A ce stade on peut voir que la taille du contenu, le nombre de liens internes, le temps de chargement des données, le nombre de caractères dans l’url expliquent le mieux le modèle.
D’un autre coté on peut voir que le fait que le mot-clé soit présent dans le nom de domaine ou non importe peu.
Attention à l’interprétation des données : pour chacune des variables il s’agit d’une contribution relative au modèle.
Par ailleurs on ne voit pas vraiment comment la variable contribue : par exemple on ne peut pas dire « plus la longueur du contenu augmente plus la page est susceptible d’être bien classée, ou inversement ».
Amélioration de l’interprétation
Afin d’améliorer la compréhension des variables d’importance nous allons relancer la fonction xgb.importance en ajoutant les informations data et label (ici pour nous data=as.matrix(train.treat) et label = train$istop3pos) de notre xgboost. Le système va splitter certaines variables et va nous fournir de nouvelles informations.
Si vous souhaitez en savoir plus sur ce sujet consultez l’article (en anglais) Understand your dataset with XGBoost dans la documentation sur XGBoost.
Notez que cette opération est très gourmande en ressources et si vous n’avez pas assez de mémoire vous devrez prendre un échantillon de votre jeu de données. Pour notre part nous avons pris un échantillon de 75.000 lignes.
# # #Précision sur l'importance des variables #l'opération suivante est très gourmande en mémoire #nettoyons la memoire rm(cv) rm(elog) rm(importance) rm(ROC) rm(test) rm(test.treat) rm(treatplan) memory.limit() #verification de la mémoire réservée pour R memory.limit(size=80000) #augmentation de la mémoire j'ai 12 GO donc 8 pour R et 4 pour tout le reste .... gc() #pour l'interprétation des données : #voir ici http://xgboost.readthedocs.io/en/latest/R-package/discoverYourData.html (importanceRaw <- xgb.importance(feature_names = colnames(x = train.treat), model = xgbmod, data=as.matrix(train.treat), label = train$istop3pos)) # Cleaning for better display importanceClean <- importanceRaw[,`:=`(Cover=NULL, Frequency=NULL)] head(importanceClean) #Si cela plante on va prendre un extrait et refaire le processus AllDataKeywords <- read.csv2( file = "YoodaTechDataKeywords.csv") #données pour passage 1 str(AllDataKeywords) AllDataKeywords <- dplyr::sample_n(AllDataKeywords, size = 75000) #on prend 75.000 enregistrements (au lieu de ~ 150.000) str(AllDataKeywords) #retourner plus haut -> définition de outcome / vars ################################################################### ############# FIN PARTIE 2
Voici les variables les plus importantes trouvées par le système (sur 5220 !!!):
| Feature | Split | Gain | RealCover | RealCover % |
| times.starttransfer_clean | 0.5935 | 0.027933262 | 25256 | 0.92330189 |
| headers.transfer_encoding.provided_clean | 0.5 | 0.024140897 | 10470 | 0.38275938 |
| urlslashcount_clean | 3.5 | 0.019446893 | 21513 | 0.78646633 |
| headers.set.cookie.domain.provided_clean | 0.5 | 0.018943024 | 2614 | 0.09556189 |
| headers.server.family_lev_x.apache | 0.5 | 0.015215883 | 8054 | 0.29443591 |
| ishttps_clean | 0.5 | 0.015037965 | 17061 | 0.62371134 |
Vous voyez ici une nouvelle colonne, la colonne split. Il faut interpréter cette donnée comme « inférieur à ».
Par exemple, on peut dire que si le temps de chargement de la page (times.starttransfer_clean) est inférieur à 0,5935 ms, elle aura plus de chance d’être dans le Top 3.
De la même façon, on peut dire que les pages d’accueil (urlslashcount_clean < 3.5) sont plus susceptibles d’être dans le Top 3.Les pages d’accueil on à priori 2 ou 3 « / » dans l’url.
A contrario, sur certaines variables, l’information est difficile à interpréter.
Par exemple, si la variable headers.transfer_encoding.provided_clean est en dessous de 0.5, donc dans ce cas 0, car on a un booléen, cela voudrait dire que le fait de ne pas fournir une information donnerait plus de chance d’être bien positionné ??? Ceci n’a évidemment pas beaucoup de sens.
Je vous laisse examiner par vous même les informations que vous pouvez recueillir et en tirer vos conclusions.
Dans un prochain article, nous ajouterons des informations liées au contenu des pages pour enrichir notre modèle.
Si vous avez des remarques, questions suggestions n’hésitez pas à laisser un commentaire.
A bientôt,
Pierre