Partager la publication "Election Trump la mort des sondages vs Big Data"
Les sondages sont-ils morts par rapport au Big Data ?
Dans un article du 18 aout dernier nous avions pu prédire l’élection de Donald Trump, comme nous l’avions fait en 2012 pour prédire l’élection d’Obama en comparant les tendances des recherches dans Google Trends sur les mois qui précédaient l’élection.
Dans le cas de Trump ces données étaient en contradiction avec l’ensemble des sondages de l’époque et qui ont été confirmées jusque la veille des élections :
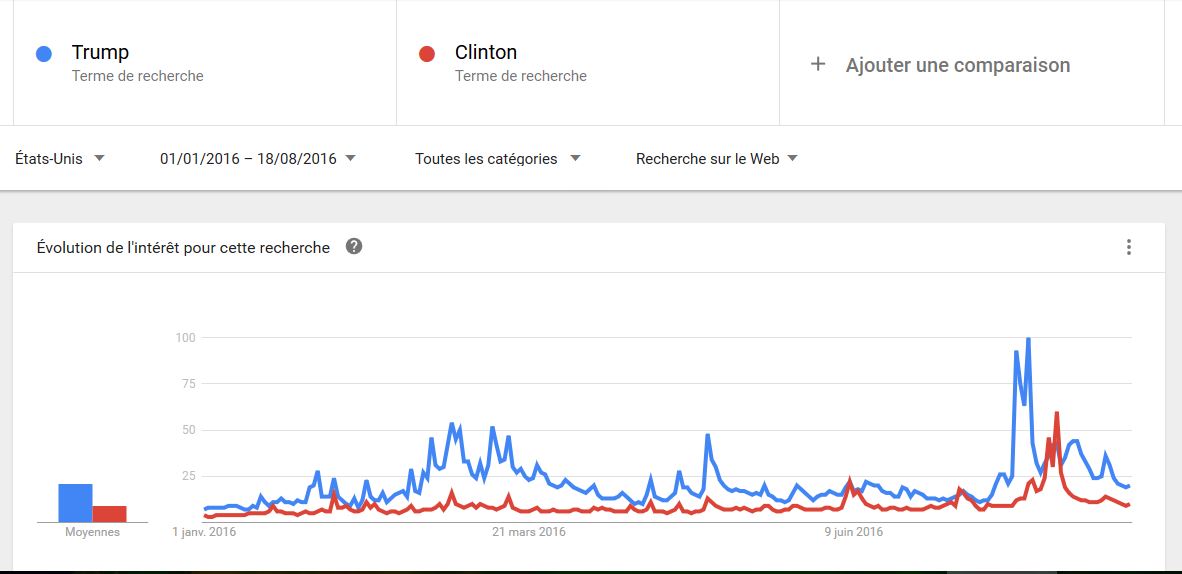
Les moyennes de l’intérêt pour ces recherches sont de 21 pour Donald Trump et de 9 pour Hillary Clinton. Période du 1er janvier au 18 août 2016.
Pour la période plus récente du 9 août au 6 novembre 2016 :
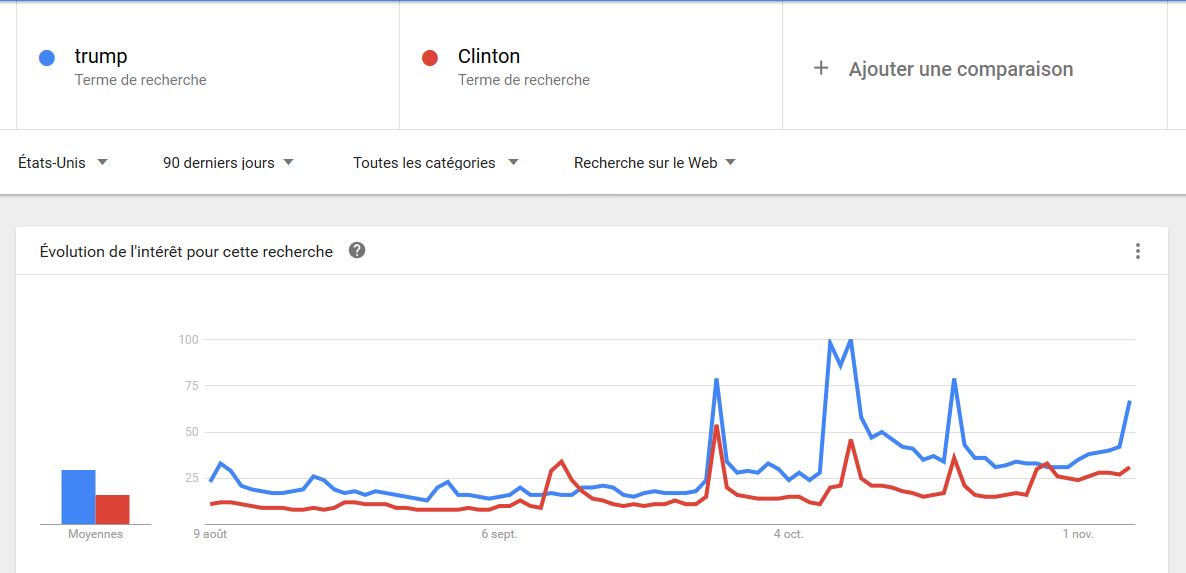
Les moyennes de l’intérêt pour ces recherches sont de 30 pour Donald Trump et de 16 pour Hillary Clinton.
Dans la dernière partie de la campagne Hillary Clinton n’a pas pu inverser la tendance de l’intérêt pour elle.
Que s’est-il passé ?
Les méthodes de sondages actuelles sont basés sur les travaux de George Gallup, comme vous pouvez le voir sur sa fiche Wikipedia qui a mis en évidence le biais d’échantillon qui était le lot des sondages d’opinion avant 1936. Il a montré qu’un plus petit échantillon (50.000 quand même) mais plus « représentatif » était plus pertinent qu’un échantillon de de 2 millions de personnes (mais basé uniquement sur des lecteurs de la revue Literary Digest).
En général, dans les études on prend des échantillons de 1000 personnes car ils sont considérés comme suffisamment précis au regard du coût de l’étude. Toutefois avec un échantillon de 1000 personnes l’erreur d’estimation est d’environ 3% :
Ci dessous la courbe d’erreur d’estimation selon la taille de l’échantillon.
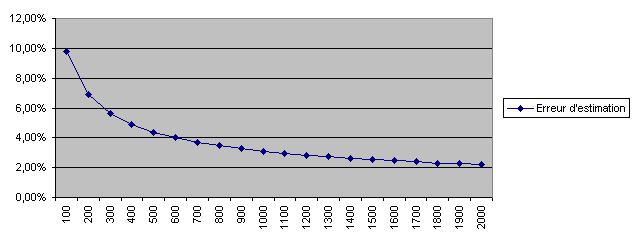
Si on veut améliorer la précision il ne suffit pas de doubler la taille de l’échantillon, en fait la précision du sondage est proportionnelle à la racine carrée de l’inverse de l’échantillon. En bref il existe une formule permettant de calculer la taille en fonction de la précision voulue. Par exemple si l’on veut une précision de 1 point la taille de l’échantillon sera plutôt de l’ordre de 9000 individus que de 3000.
Si auparavant cela coutait très cher, aujourd’hui nous avons des informations sur des millions voire des centaines de millions d’individus grâce au big Data. Quand l’échantillon tend vers un pourcentage important de la population totale, par exemple 80 % des américains utilise Google, la marge d’erreur à tendance à s’amenuiser et le biais d’erreur d’échantillon devient négligeable.
Biais de désirabilité sociale
En revanche dans les sondages il existe bien d’autres biais liés au fait que c’est du déclaratif et notamment le « biais de désirabilité sociale » : la désirabilité sociale est le biais qui consiste à vouloir se présenter sous un jour favorable à ses interlocuteurs. Ce mécanisme psychologique peut s’exercer de façon implicite, sans qu’on en ait conscience, ou au contraire être le résultat d’une volonté consciente de manipuler son image aux yeux des autres. (source Wikipédia)
Ce biais est connu des sondeurs français notamment concernant le Front National. Pendant des années les résultats des enquêtes concernant les électeurs du Front National étaient corrigés pour tenir compte d’une réalité. Il n’était pas très avouable de voter Front National à l’époque (cela a peut être changé aujourd’hui).
Or ce biais est difficile à évaluer. Dans le cas du Front National la correction était faite en fonction des élections précédentes. Dans le cas de Trump, il n’y a pas de précédent, donc comment l’évaluer ?
Par ailleurs celui-ci peut évoluer dans le temps : nous avons tout lieu de penser qu’au début de la campagne les résultats de Trump étaient sous évalués car ce choix n’était pas « politiquement correct ». Au fur et à mesure qu’ils se sont sentis moins seuls les électeurs de Trump on été de plus en plus honnêtes avec eux-mêmes.
En d’autres termes la convergence des résultats entre Hillary Clinton et Donald Trump n’est pas du au fait que les électeurs de Donald Trump se sont mobilisés mais au fait qu’ils se sont dévoilés.
Déclaratif vs Comportement
On notera qu’il est tout de même intéressant qu’un outil public comme Google Trends permette d’anticiper des meilleurs résultats que tous les instituts de sondage et ceux malgré l’imprécision de cet outil qui dépend de ce que Google veut bien nous donner.
On mesure donc ici la puissance de prévision que peuvent faire Google et FaceBook, qui eux sont capables d’affiner ce modèle car ils ont des informations vous concernant très précises (âge, sexe, habitudes d’achat, sites visités, appréciations politiques et religieuse…) en se basant sur votre comportement et non pas vos déclarations.
Ils peuvent même savoir avant vous pour qui vous allez voter !
Curieusement ni Google ni FaceBook n’ont fait de déclarations, alors qu’ils savaient !
Bienvenue dans un nouveau Monde 🙂
Ph.RIS
9 novembre 2016 at 20 h 16 minLe comportement apparaît effectivement plus objectif que le déclaratif. Cependant, le comportement peut marquer un intérêt positif (j’agis dans le sens de ce que je veux vraiment faire) mais aussi négatif (j’agis pour me moquer, dénigrer, …).
Le second point est-il assez mineur pour être négligé ?
Avez-vous mis en place des filtres pour éliminer le comportement négatif non représentatif du choix réel ?
En tout cas bravo pour la prédiction.
Pierre Rouarch • Post Author •
10 novembre 2016 at 11 h 26 minVous avez raison, il serait intéressant d’analyser toutes les requêtes tapées pour voir si elle sont « positives » ou « négatives » par exemple à partir d’un outil nous fournissant toutes les requêtes contenant « Donald Trump » ou « Hillary Clinton », par exemple Adwords (mais encore là on n’a que les informations que nous donne Google). En revanche, avec les données accessibles publiquement je ne peux pas savoir qu’elle était l’intention de celui ou celle qui a tapé la requête. Google a certainement la possibilité de connaître cette intention et ou en tout cas de « profiler » chaque utilisateur en « pro » ou « con » par rapport a une requête. Pour ma part, comme il ne s’agit pas ici de donner un pourcentage exact des résultats mais un « intérêt » global pour une personnalité, j’ai négligé cet aspect car le modèle avait fonctionné pour les 4 élections précédentes. Si les tendances avaient été proches il aurait certainement été intéressant d’aller plus avant.