Partager la publication "Calcul d’un score BERT pour le référencement SEO"
Dans cet article nous verrons comment calculer un « score BERT » pour déterminer si une page web est susceptible de répondre à une question posée dans Google.
Pour ceux qui n’auraient pas fait attention, l’algorithme BERT a été déployé sur les résultats de Google pour l’anglais aux US depuis le 25 octobre 2019, et depuis le 9 décembre de cette même année pour d’autres langues, dont le français.
En clair, pour des requêtes longues et /ou des questions, BERT va essayer de trouver les pages qui répondent le mieux en faisant une analyse « sémantique » du contenu.
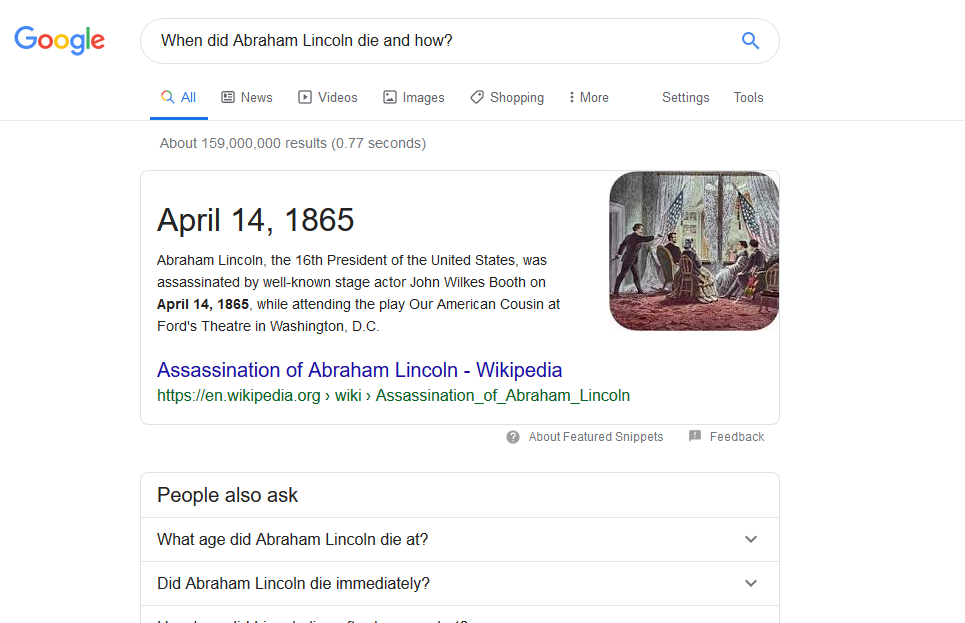
Ceci permet notamment d’avoir des résultats ou Google répond directement à une question. Par exemple ici : « When did Abraham Lincoln die and how? »
Qu’est-ce que BERT ?
Même si BERT est nouveau pour la communauté des référenceurs, celui-ci était déjà connu de la communauté des data scientists depuis 2018 (ce qui n’est pas très ancien non plus). En fait depuis le 2 novembre 2018 et la publication en open source par Google de cet algorithme utilisé notamment dans le traitement du langage naturel.
Voir aussi le code source de BERT sur Github.
BERT signifie Bidirectional Encoder Representations from Transformers. La chose importante à retenir ici est le mot bidirectionnel.
Ceci veut dire que BERT peut comprendre la signification d’un mot en analysant le contexte avant et après le mot. Ce qui est un progrès par rapport aux modèles précédents.
Attention, pour pouvoir être efficace BERT a été pré entrainé sur un large corpus de textes et notamment Wikipédia.
Comment BERT (de base) est pré-entrainé ?
BERT utilise 2 tâches non supervisées pour entrainer son modèle :
- Le Masked Language Model (MLM) dont le principe est de découvrir la probabilité d’un mot manquant dans une phrase.
- Le Next Sentence Processing (NSP) qui comme son nom l’indique doit prévoir la phrase suivante d’une phrase.
A quoi peut servir BERT ensuite ?
Une fois pré entrainé, on peut utiliser BERT pour lui faire faire des tâches plus précises (on parle de « fine-tuning ») comme par exemple :
- L’analyse de sentiment sur des textes.
- Des tâches de Questions Réponses (c’est ce qui nous intéresse ici).
- La reconnaissance d’entité : par exemple savoir si l’on a affaire à une personne, un lieu, une date etc…
- …
A quoi peut servir BERT pour Google ?
D’après le Search Engine Journal qui a écrit un article très fouillé sur BERT et Google, BERT permet de résoudre un certain nombre de problèmes existants dans la compréhension du langage comme les ambiguïtés lexicales (les mots qui peuvent être des noms, des verbes ou des adjectifs), les mots ayant plusieurs sens, les homophonies (mots qui se prononcent pareils), la résolution des anaphores et cataphores grammaticales…
Il permet aussi et c’est l’objet de cet article, de répondre à des questions directement dans ses résultats de recherche.
Remarque importante : comme les modèles BERT pré entrainés sur les Questions Réponses que nous avons trouvés sont en anglais, l’outil fonctionnera pour l’instant en anglais sur Google.com.
Si quelqu’un a un modèle en français, il peut laisser un message en commentaires ! Merci 🙂 !
De quoi aurons nous besoin ?
Pour tester le programme, je vous propose cette fois 2 possibilités, soit le tester sur votre ordinateur, soit dans Google Colab.
Sur votre Ordinateur
Comme d’habitude, nous vous conseillons de travailler avec la version Python Anaconda (aujourd’hui la version 3.7) qui comprend les outils de base pour le Data Scientist et aussi l’interface de développement Spyder et l’outil Jupyter Notebook qui permet de créer et de partager des documents exécutant du code Python (Nous reverrons cela avec Google Colab).
Nota Bene : Nous utilisons ici la bibliothèque de Deep Learning PyTorch (développée par FaceBook) avec Transformers (de Hugging Face) et non pas Keras et Tensorflow (développée par Google) pour manipuler un algorithme BERT (développé par Google). Bon tout cela peut paraitre curieux, mais cela fonctionne sur Python 3.7.
Rendez-vous ensuite dans notre boutique à l’adresse : https://www.anakeyn.com/boutique/produit/script-python-calcul-dun-score-bert-seo/ pour télécharger les codes source gratuitement.
Veillez à les installer dans un sous répertoire « Bert_Squad_SEO » (évitez les « – » dans le nom du répertoire, ce sera utile ensuite dans Google Colab.
CODE SOURCE de Bert_Squad_SEO_Score.py
Lancer le programme Spyder et ouvrez le fichier python Bert_Squad_SEO_Score.py nous allons commentez ici le code source :
InSTANtIATION de la CLASSE « QA » : Question Réponse
Récupérez des noms de modèles pré entrainés avec SQuAD sur la page officielle de Hugging Face : https://huggingface.co/transformers/pretrained_models.html. Pour l’instant nous en avons 2 :
- ‘bert-large-uncased-whole-word-masking-finetuned-squad’
- ‘bert-large-cased-whole-word-masking-finetuned-squad’
Le paramètres n_best_size indique le nombre de meilleures réponses que nous souhaitons pour chaque document (ici des pages Web). 20 est largement suffisant. La moyenne du score des 20 meilleures réponses servira d’indicateur BERT Score entre 0 Et 1 pour chaque page Web.
Indiquez aussi votre question (en anglais) dans la variable myKeyword.
# -*- coding: utf-8 -*-
"""
Created on Sun Dec 15 16:03:38 2019
@author: Pierre
"""
#############################################################
# Bert_Squad_SEO_Score.py
# Anakeyn Bert Squad Score for SEO Alpha 0.1
# This tool provide a "Bert Score" for first max 30 pages responding to a question in Googe.
#This tool is using Bert-SQuad created by Kamal Raj. We modified it to calculate a "Bert-Score"
# regarding severall documents and not a score inside a unique document.
# see original BERT-SQuAD : #https://github.com/kamalkraj/BERT-SQuAD
#############################################################
#Copyright 2019 Pierre Rouarch
# License GPL V3
#############################################################
myKeyword="When Abraham Lincoln died and how?"
from bert import QA
#from bert import QA
n_best_size = 20
#list of pretrained model
#https://huggingface.co/transformers/pretrained_models.html
#!!!!! instantiate a BERT model fine tuned on SQuAD
#Choose your model
#'bert-large-uncased-whole-word-masking-finetuned-squad'
#'bert-large-cased-whole-word-masking-finetuned-squad'
model = QA('bert-large-uncased-whole-word-masking-finetuned-squad', n_best_size)
Bibliothèques et fonctions nécessaires
#import needed libraries
import pandas as pd
import numpy as np
#pip install google #to install Google Search by Mario Vilas see
#https://python-googlesearch.readthedocs.io/en/latest/
import googlesearch #Scrap serps
#to randomize pause
import random
import time #to calcute page time download
from datetime import date
import sys #for sys variables
import requests #to read urls contents
from bs4 import BeautifulSoup #to decode html
from bs4.element import Comment
#remove comments and non visible tags from html
def tag_visible(element):
if element.parent.name in ['style', 'script', 'head', 'title', 'meta', '[document]']:
return False
if isinstance(element, Comment):
return False
return True
Récupération des 30 premières pages
Nous allons récupérer les URLS des 30 premières pages qui répondent le mieux à notre question dans Google.
Pour cela on utilisera la bibliothèque googlesearch de Mario Vilas que nous avions déjà utilisée : https://python-googlesearch.readthedocs.io/en/latest/
###############################################
# Search in Google and scrap Urls
###############################################
dfScrap = pd.DataFrame(columns=['keyword', 'page', 'position', 'BERT_score', 'source', 'search_date'])
myNum=10
myStart=0
myStop=10 #get by ten
myMaxStart=30 #only 30 pages
myLowPause=5
myHighPause=15
myDate=date.today()
nbTrials = 0
myTLD = "com" #Google tld -> we search in google.com
myHl = "en" #in english
#this may be long
while myStart < myMaxStart:
print("PASSAGE NUMBER :"+str(myStart))
print("Query:"+myKeyword)
#change user-agent and pause to avoid blocking by Google
myPause = random.randint(myLowPause,myHighPause) #long pause
print("Pause:"+str(myPause))
#change user_agent and provide local language in the User Agent
#myUserAgent = getRandomUserAgent(myconfig.userAgentsList, myUserAgentLanguage)
myUserAgent = googlesearch.get_random_user_agent()
print("UserAgent:"+str(myUserAgent))
#myPause=myPause*(nbTrials+1) #up the pause if trial get nothing
#print("Pause:"+str(myPause))
try :
urls = googlesearch.search(query=myKeyword, tld=myTLD, lang=myHl, safe='off',
num=myNum, start=myStart, stop=myStop, domains=None, pause=myPause,
tpe='', user_agent=myUserAgent)
df = pd.DataFrame(columns=['keyword', 'page', 'position', 'BERT_score', 'source', 'search_date'])
for url in urls :
print("URL:"+url)
df.loc[df.shape[0],'page'] = url
df['keyword'] = myKeyword #fill with current keyword
# df['tldLang'] = myTLDLang #fill with current country / tld lang not use here all in in english
df['position'] = df.index.values + 1 + myStart #position = index +1 + myStart
df['BERT_score'] = 0 #not yet calculate
df['source'] = "Scrap" #fill with source origin here scraping Google
#other potentials options : Semrush, Yooda Insight...
df['search_date'] = myDate
dfScrap = pd.concat([dfScrap, df], ignore_index=True) #concat scraps
# time.sleep(myPause) #add another pause
if (df.shape[0] > 0):
nbTrials = 0
myStart += 10
else :
nbTrials +=1
if (nbTrials > 3) :
nbTrials = 0
myStart += 10
#myStop += 10
except :
exc_type, exc_value, exc_traceback = sys.exc_info()
print("ERROR")
print(exc_type.__name__)
print(exc_value)
print(exc_traceback)
# time.sleep(600) #add a big pause if you get an error.
#/while myStart < myMaxStart:
dfScrap.info()
dfScrapUnique=dfScrap.drop_duplicates() #remove duplicates
dfScrapUnique.info()
#Save
dfScrapUnique.to_csv("dfScrapUnique.csv", sep=",", encoding='utf-8', index=False) #sep ,
dfScrapUnique.to_json("dfScrapUnique.json")
Récupération du contenu des pages
On va ensuite récupérer le contenu des pages. On enlève au préalable les documents non html.
###### filter extensions
extensionsToCheck = ('.7z','.aac','.au','.avi','.bmp','.bzip','.css','.doc',
'.docx','.flv','.gif','.gz','.gzip','.ico','.jpg','.jpeg',
'.js','.mov','.mp3','.mp4','.mpeg','.mpg','.odb','.odf',
'.odg','.odp','.ods','.odt','.pdf','.png','.ppt','.pptx',
'.psd','.rar','.swf','.tar','.tgz','.txt','.wav','.wmv',
'.xls','.xlsx','.xml','.z','.zip')
indexGoodFile= dfScrapUnique ['page'].apply(lambda x : not x.endswith(extensionsToCheck) )
dfUrls2=dfScrapUnique.iloc[indexGoodFile.values]
dfUrls2.reset_index(inplace=True, drop=True)
dfUrls2.info()
#######################################################
# Scrap Urls only one time
########################################################
myPagesToScrap = dfUrls2['page'].unique()
dfPagesToScrap= pd.DataFrame(myPagesToScrap, columns=["page"])
#dfPagesToScrap.size #9
#add new variables
dfPagesToScrap['statusCode'] = np.nan
dfPagesToScrap['html'] = '' #
dfPagesToScrap['encoding'] = '' #
dfPagesToScrap['elapsedTime'] = np.nan
for i in range(0,len(dfPagesToScrap)) :
url = dfPagesToScrap.loc[i, 'page']
print("Page i = "+url+" "+str(i))
startTime = time.time()
try:
#html = urllib.request.urlopen(url).read()$
r = requests.get(url,timeout=(5, 14)) #request
dfPagesToScrap.loc[i,'statusCode'] = r.status_code
print('Status_code '+str(dfPagesToScrap.loc[i,'statusCode']))
if r.status_code == 200. : #can't decode utf-7
print("Encoding="+str(r.encoding))
dfPagesToScrap.loc[i,'encoding'] = r.encoding
if r.encoding == 'UTF-7' : #don't get utf-7 content pb with db
dfPagesToScrap.loc[i, 'html'] =""
print("UTF-7 ok page ")
else :
dfPagesToScrap.loc[i, 'html'] = r.text
#au format texte r.text - pas bytes : r.content
print("ok page ")
#print(dfPagesToScrap.loc[i, 'html'] )
except:
print("Error page requests ")
endTime= time.time()
dfPagesToScrap.loc[i, 'elapsedTime'] = endTime - startTime
#/
dfPagesToScrap.info()
#merge dfUrls2, dfPagesToScrap -> dfUrls3
dfUrls3 = pd.merge(dfUrls2, dfPagesToScrap, on='page', how='left')
#keep only status code = 200
dfUrls3 = dfUrls3.loc[dfUrls3['statusCode'] == 200]
#dfUrls3 = dfUrls3.loc[dfUrls3['encoding'] != 'UTF-7'] #can't save utf-7 content in db ????
dfUrls3 = dfUrls3.loc[dfUrls3['html'] != ""] #don't get empty html
dfUrls3.reset_index(inplace=True, drop=True)
dfUrls3.info() #
dfUrls3 = dfUrls3.dropna() #remove rows with at least one na
dfUrls3.reset_index(inplace=True, drop=True)
dfUrls3.info() #
#Remove Duplicates before calculate Bert Score
dfPagesUnique = dfUrls3.drop_duplicates(subset='page') #remove duplicate's pages
dfPagesUnique = dfPagesUnique.dropna() #remove na
dfPagesUnique.reset_index(inplace=True, drop=True) #reset index
Récupération du BERT SCORE
On récupérera la partie visible de la page HTML. 0n sauvegardera ensuite les informations données par la fonction de prédiction :
answer = model.predict( dfPagesUnique.loc[i, 'body'],myKeyword)
dans différents fichiers Excel.
#Create body from HTML and get Bert_score ### may be long
dfPagesAnswers = pd.DataFrame(columns=['keyword', 'page', 'position', 'BERT_score', 'source', 'search_date','answers','starts', 'ends', 'local_probs', 'total_probs'])
for i in range(0,len(dfPagesUnique)) :
soup=""
print("Page keyword tldLang i = "+ dfPagesUnique.loc[i, 'page']+" "+ dfPagesUnique.loc[i, 'keyword']+" "+str(i))
encoding = dfPagesUnique.loc[i, 'encoding'] #get previously
print("get body content encoding"+encoding)
try:
soup = BeautifulSoup( dfPagesUnique.loc[i, 'html'], 'html.parser')
except :
soup=""
if len(soup) != 0 :
#TBody Content
texts = soup.findAll(text=True)
visible_texts = filter(tag_visible, texts)
myBody = " ".join(t.strip() for t in visible_texts)
myBody=myBody.strip()
#myBody = strip_accents(myBody, encoding).lower() #think to do a global clean instead
myBody=" ".join(myBody.split(" ")) #remove multiple spaces
print(myBody)
dfPagesUnique.loc[i, 'body'] = myBody
answer = model.predict( dfPagesUnique.loc[i, 'body'],myKeyword)
print("BERT_score"+str(answer['mean_total_prob']))
dfPagesUnique.loc[i, 'BERT_score'] = answer['mean_total_prob']
dfAnswer = pd.DataFrame(answer, columns=['answers','starts', 'ends', 'local_probs', 'total_probs'])
dfPageAnswer = pd.DataFrame(columns=['keyword', 'page', 'position', 'BERT_score', 'source', 'search_date','answers','starts', 'ends', 'local_probs', 'total_probs'])
for k in range (0, len(dfAnswer)) :
dfPageAnswer.loc[k, 'keyword'] = dfPagesUnique.loc[i, 'keyword']
dfPageAnswer.loc[k, 'page'] = dfPagesUnique.loc[i, 'page']
dfPageAnswer.loc[k, 'position'] = dfPagesUnique.loc[i, 'position']
dfPageAnswer.loc[k,'BERT_score'] = dfPagesUnique.loc[i, 'BERT_score']
dfPageAnswer.loc[k,'source'] = dfPagesUnique.loc[i,'source']
dfPageAnswer.loc[k,'search_date'] = dfPagesUnique.loc[i,'search_date']
dfPageAnswer.loc[k,'answers'] = dfAnswer.loc[k,'answers']
dfPageAnswer.loc[k,'starts'] = dfAnswer.loc[k,'starts']
dfPageAnswer.loc[k,'ends'] = dfAnswer.loc[k,'ends']
dfPageAnswer.loc[k, 'local_probs'] = dfAnswer.loc[k, 'local_probs']
dfPageAnswer.loc[k, 'total_probs'] = dfAnswer.loc[k, 'total_probs']
dfPagesAnswers = pd.concat([dfPagesAnswers, dfPageAnswer], ignore_index=True) #concat Pages Answers
dfPagesAnswers.info()
#Save Answers
dfPagesAnswers.to_csv("dfPagesAnswers.csv", sep=",", encoding='utf-8', index=False)
dfPagesUnique.info()
#Save Bert Scores by page
dfPagesSummary = dfPagesUnique[['keyword', 'page', 'position', 'BERT_score', 'search_date']]
dfPagesSummary.to_csv("dfPagesSummary.csv", sep=",", encoding='utf-8', index=False)
#Save page content in csv and json
dfPagesUnique.to_csv("dfPagesUnique.csv", sep=",", encoding='utf-8', index=False) #sep ,
dfPagesUnique.to_json("dfPagesUnique.json")
Résultats
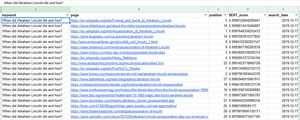
2 fichiers nous intéressent : dfPagesSummary.csv et dfPagesAnswers.csv
dfPagesSummary.csv contient les Scores BERT en fonction des pages. Ici pour la question « When did Abraham Lincoln die and how? » toutes les pages trouvées ont un bon score :
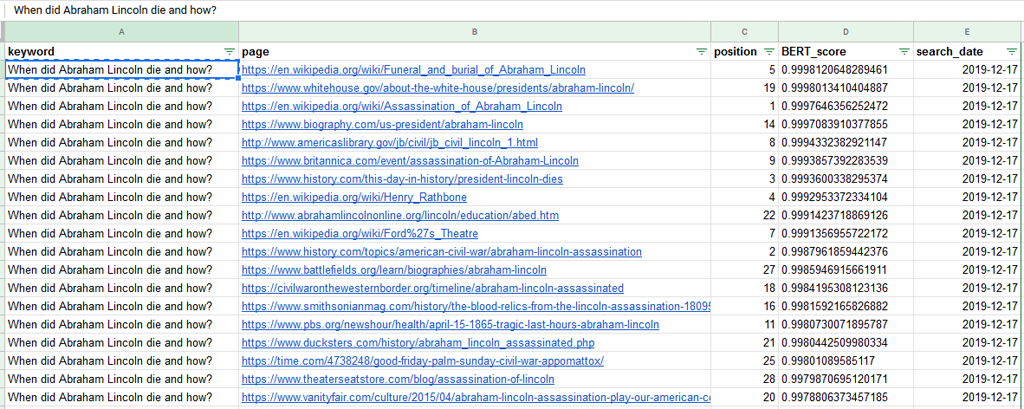
Comme on le voit sur l’image, la plupart des pages bien positionnées ont aussi un bon score BERT.
Regardons dans le fichier dfPagesAnswers pour affiner les résultats et voir si le programme répond bien à la question :
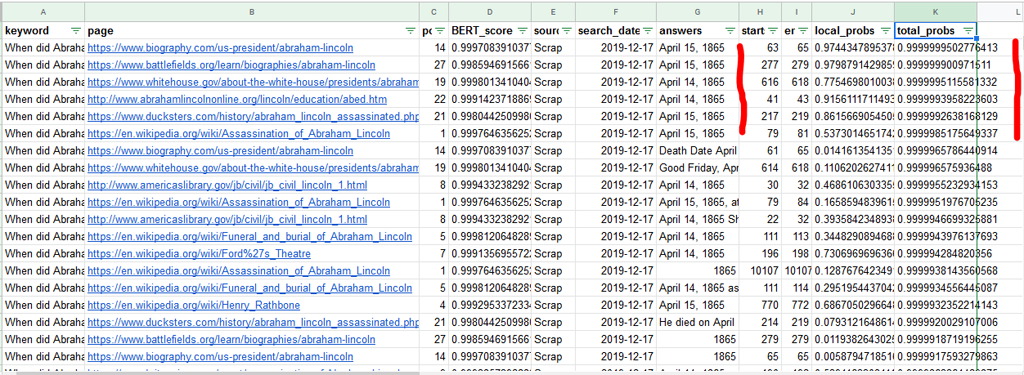
Comme on peut le voir dans la colonne « answers », le programme est efficace pour trouver des bonnes réponses. Le score qui nous intéresse ici est « total_probs » qui est le score « absolu » pour la réponse (pas la page). On voit que les scores sont très importants.
Le score « local_probs » est le score de cette réponse relativement aux 19 autres réponses dans la page.
Les éléments start et end correspondent au numéro de mot (ou plutôt de jetons) de départ et de fin de la réponse. Si l’on élargit l’intervalle autour de la réponse, cela permettrait d’avoir une vision du contexte et d’avoir une aide pour rédiger des réponses efficaces.
Rem: on pourra imaginer par la suite de reprendre les scores BERT calculés de cette façon. Puis les utiliser comme facteurs de classement dans le SEO et les ajouter à nos modèles de classification via le Deep Learning ou le Machine Learning.
CODE SOURCE de bert.py
Nous n’allons pas présenter en détail le programme bert.py mais seulement les modifications que nous avons apportées, par rapport à l’original réalisé par Kamal Raj. Pour avoir des détails sur l’original reportez-vous à son github : https://github.com/kamalkraj/BERT-SQuAD.
Rappel : le fichier bert.py modifié se trouve en entier sur notre Github : https://github.com/Anakeyn/Bert_Squad_SEO.
Ici nous présentons le début du programme où nous avons fait les modifications, à savoir :
- Nous avons changé « pytorch_transformers » en « transformers » le nom ayant changé chez Hugging Face (ligne 13)
- Nous avons mis en paramètre en entrée « n_best_size » dans la classe QA que vous pouvez ainsi modifier selon vos besoins (ligne 27 et 32)
- Dans Load Model nous avons décidé de charger un modèle pré entrainé chez Hugging Face (voir liste des modèles ici : https://huggingface.co/transformers/pretrained_models.html) plutôt que le modèle entrainé par Kamal et sauvegardé sur notre machine.
#Original by Kamal Raj see https://github.com/kamalkraj/BERT-SQuAD
#modified by Pierre Rouarch 16/12/2019. see #PR
from __future__ import absolute_import, division, print_function
import collections
import logging
import math
import numpy as np
import torch
#PR new : transformers instead of pytorch_transformers
from transformers import (WEIGHTS_NAME, BertConfig,
BertForQuestionAnswering, BertTokenizer)
from torch.utils.data import DataLoader, SequentialSampler, TensorDataset
from utils import (get_answer, input_to_squad_example,
squad_examples_to_features, to_list)
RawResult = collections.namedtuple("RawResult",
["unique_id", "start_logits", "end_logits"])
class QA:
def __init__(self,model_path: str, n_best_size=20):
self.max_seq_length = 384 #original 384
self.doc_stride = 128
self.do_lower_case = True
self.max_query_length =64# orig 64
self.n_best_size = n_best_size #orig 20 #PR we set this as an input parameter in QA
self.max_answer_length = 30
self.model, self.tokenizer = self.load_model(model_path)
if torch.cuda.is_available():
self.device = 'cuda'
else:
self.device = 'cpu'
self.model.to(self.device)
self.model.eval()
def load_model(self,model_path: str,do_lower_case=False):
#old version by Kam
#config = BertConfig.from_pretrained(model_path + "/bert_config.json")
#tokenizer = BertTokenizer.from_pretrained(model_path, do_lower_case=do_lower_case)
#model = BertForQuestionAnswering.from_pretrained(model_path, from_tf=False, config=config)
#PR use a standard https://huggingface.co/transformers/pretrained_models.html SQuAD fine Tune Model
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertForQuestionAnswering.from_pretrained(model_path)
return model, tokenizer
Code source utils.py
Comme précédemment, nous n’allons pas publier et commenter l’ensemble du programme utils.py.
Rappel : le fichier utils.py modifié se trouve en entier sur notre github : https://github.com/Anakeyn/Bert_Squad_SEO.
les modifications ont été les suivantes :
- Au début du programme, nous avons changé « pytorch_transformers » en « transformers » le nom ayant changé chez Hugging Face (ligne 12)
- A la fin du programme, dans la fonction get_answer nous avons calculé des scores « absolu », total_probs (sous forme de probabilité entre 0 et 1 ) à partir des score total_scores sous forme de logit (entre – ∞ et + ∞ ) pour chaque réponse trouvée dans la page.
- La valeur mean_total_probs étant la moyenne des ces valeurs, et nous servira de score « BERT ».
#PR get values in separate lists
total_scores = []
answers = []
starts = []
ends = []
for entry in nbest:
total_scores.append(entry.start_logit + entry.end_logit)
answers.append(entry.text)
starts.append(entry.start_index)
ends.append(entry.end_index)
#relative to the document sum(local_probs)==1 we keep it
probs = _compute_softmax(total_scores)
#PR Total_probs create from total_scores (which is a logit)
total_probs = []
for score in total_scores : #total score =
total_probs.append(1/(1+math.exp(-score)))
mean_total_prob = np.mean(total_probs )
#PR change answer outputs
answer = {"answers" : answers, #responses texts
"starts" : starts, #Start indexes of responses
"ends" : ends, #end indexes responses
"doc_tokens" : example.doc_tokens, #document tokens
"local_probs" : probs, #all best local probs (old indicators or results after softmax)
"total_scores" :total_scores, #All best scores (not softmaxed)
"total_probs" : total_probs, #All best probs (not softmaxed)
"mean_total_prob" : mean_total_prob #the new bert score indicator !!!
}
return answer
Sur Google Colab
Google Colab est un outil en ligne de Google qui permet d’exécuter des Notebook Jupyter directement dans le « cloud ».

Un Notebook Jupyter est un fichier qui contient à la fois du texte, des images et du code source exécutable, notamment en Python.
L’avantage de Google Colab est que vous pouvez utiliser virtuellement un processeur graphique GPU, ou un Processeur pour Tenseurs, Tensor Processing Unit (TPU), ce qui permet d’accélérer grandement les calculs.
Google Colab peut fonctionner avec votre Google Drive. Ceci vous permet de sauvegarder vos notebooks et aussi des données (nous verrons comment).
Notebook Bert_Squad_SEO_Score_Colab.ipynb
Dans notre Github que vous avez normalement téléchargé à l’adresse https://github.com/Anakeyn/Bert_Squad_SEO, vous trouverez le fichier NoteBook Jupyter Bert_Squad_SEO_Score_Colab.ipynb.
Pour faciliter sa manipulation dans Google Colab, ce notebook Jupyter contient à la fois le code source de Bert_Squad_SEO_Score.py, bert.py et utils.py.
Upload sur Google Drive
Dans un premier temps vous allez uploader le fichier Bert_Squad_SEO_Score_Colab.ipynb dans un répertoire (par exemple Bert_Squad_SEO) sur votre Google Drive.
Pour uploader un fichier ou un dossier, cliquez sur nouveau à gauche de l’écran de Google Drive :
Attention !!!! Ne pas donner de nom de fichier avec des « – » (tiret du 6) cela plante Google Colab, je ne sais pas pourquoi.
Une fois votre environnement mis en place cliquez sur le NoteBook :
le système vous propose de l’ouvrir avec Google Colab :
Avant toute chose il est nécessaire de paramétrer l’utilisation du processeur graphique GPU pour votre NoteBook : Modifier -> Paramètres du NoteBook :
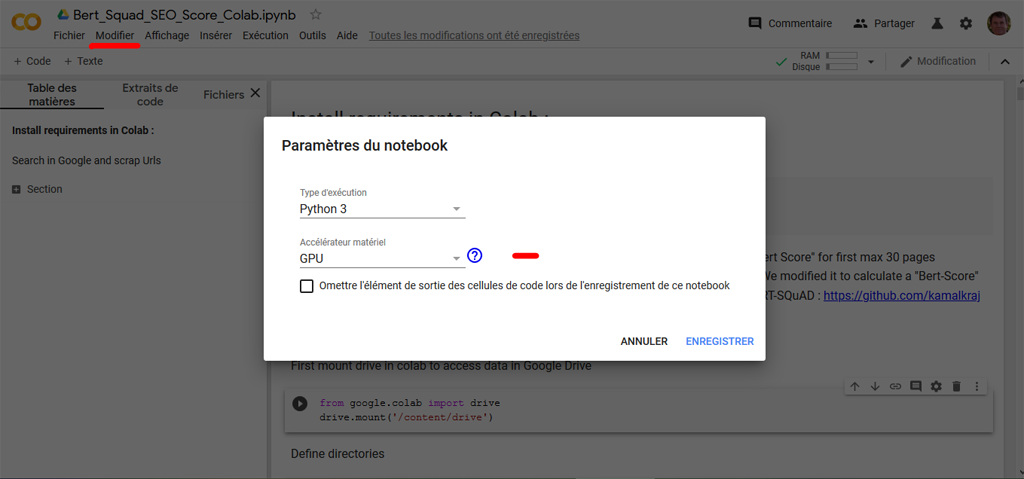
Vous pouvez maintenant démarrer l’exécution du NoteBook. Celui -ci s’exécute morceau de code par morceau de code.
Nous n’allons pas revenir sur ce que nous avions vu précédemment pour la version ordinateur. Nous allons juste parler des spécificités dans Google Colab.
Chargement des bibliothèques non fournies par GoOGle Colab
Google Colab propose par défaut de nombreuses bibliothèques, il peut toutefois arriver qu’il manque celles qui nous intéressent. Ici à priori : « transformers » qui gère notamment BERT pour Pytorch et « google » la bibliothèque qui permet de scraper les pages de Google.
Dans Google Colab vous utilisez la commande « pip » traditionnelle avec un « ! » avant :
!pip install transformers !pip install google
Utiliser son Google Drive avec GoOGle Colab
Pour pouvoir utiliser votre Google Drive afin d’importer des données ou de sauvegarder des données il est nécessaires de le « monter » (comme avec Unix/Linux). La commande est la suivante :
from google.colab import drive
drive.mount('/content/drive')
Quand vous lancez la commande, Google Colab va vous demander d’aller récupérer un code d’autorisation. Suivez le lien et les instructions de Google (plusieurs pop-ups s’affichent),entrez votre code dans la zone prévue et tapez sur entrée.
Une fois la connexion avec Drive effectuée, celui ci sera accessible :
import os base_dir = 'drive/My Drive/Bert_Squad_SEO' print(base_dir)
drive/My Drive/Bert_Squad_SEO
Attention !!!! pour des raisons que j’ignore, le répertoire de votre Google Drive est à l’emplacement « drive/My Drive/ » et non pas « content/drive/My Drive/ » !!!!
Exécutez ensuite les parties de code une à une.
A un moment donné vous verrez la ligne :
myKeyword="When did Abraham Lincoln die and how?"
vous pouvez bien sûr changer la question voulue.
Comme vous pouvez le constater, l’exécution sur Google Colab est beaucoup plus rapide que sur un ordinateur sans GPU.
A la fin, le système sauvegarde les fichiers de résultats sur votre Google Drive :
Et vous quels sont vos résultats ? Et pour quelles requêtes ?
N’hésitez pas à commenter !!
Merci pour votre attention,
Pierre
This article is also available in English here : https://www.jcchouinard.com/get-bert-score-for-seo-by-pierre-rouarch/. Thanks to Jean-Christophe Chouinard for the translation.
Jean-Christophe Chouinard
15 janvier 2020 at 15 h 15 minSuper article qui mérite d’être vu par le plus grand nombre! J’ai terminé de le traduire en anglais. Il s’en viens sous peu 🙂
Pierre • Post Author •
15 janvier 2020 at 15 h 36 minSuper ! j’ai hâte de voir cela !
Pierre • Post Author •
10 février 2020 at 9 h 21 minVoilà j’ai mis un lien vers la version en anglais !