
Partager la publication "Comparatif Macron Wauquiez Mélenchon Le Pen avec TwitteR"
Dans cet article nous verrons comment récupérer des tweets avec le logiciel R et la bibliothèque TwitteR. Nous verrons aussi comment extraire des données textuelles de ces tweets et essayer de les rendre intelligibles.
Pour cet exercice nous avons choisi de traiter des tweets concernant des personnalités politiques. à savoir, ici : Emmanuel Macron, Laurent Wauquiez, Jean-Luc Mélechon et Marine Le Pen. Ceci afin d’essayer de percevoir ce qu’en disent les Twittos.
Vous pouvez bien sûr tester ce programme pour des marques plutôt que des personnalités.
Logiciel R
Comme d’habitude, afin de pouvoir tester le code source de cette démonstration nous vous invitons à télécharger Le Logiciel R sur ce site https://cran.r-project.org/, ainsi que l’environnement de développement RStudio ici : https://www.rstudio.com/products/rstudio/download/.
Créer une application dans Twitter
Afin de pouvoir importer les tweets dans le Logiciel R, il vous sera nécessaire de créer une « application » dans Twitter pour les développeurs. Cet import se fera à partir de l’API (Application Programming Interface) de Twitter. Suivez cette procédure :
1 – Si vous n’avez pas de compte Twitter, créez en un !
2 – Allez sur la page de gestion d’applications : https://apps.twitter.com/ en vous connectant avec vos login et Mot de passe de votre compte Twitter.
3 – Cliquez sur « Create New App »

4 – Remplissez le formulaire à votre convenance et validez. Attention le champ Callback URL doit contenir l’URL « http://localhost:1410 ».
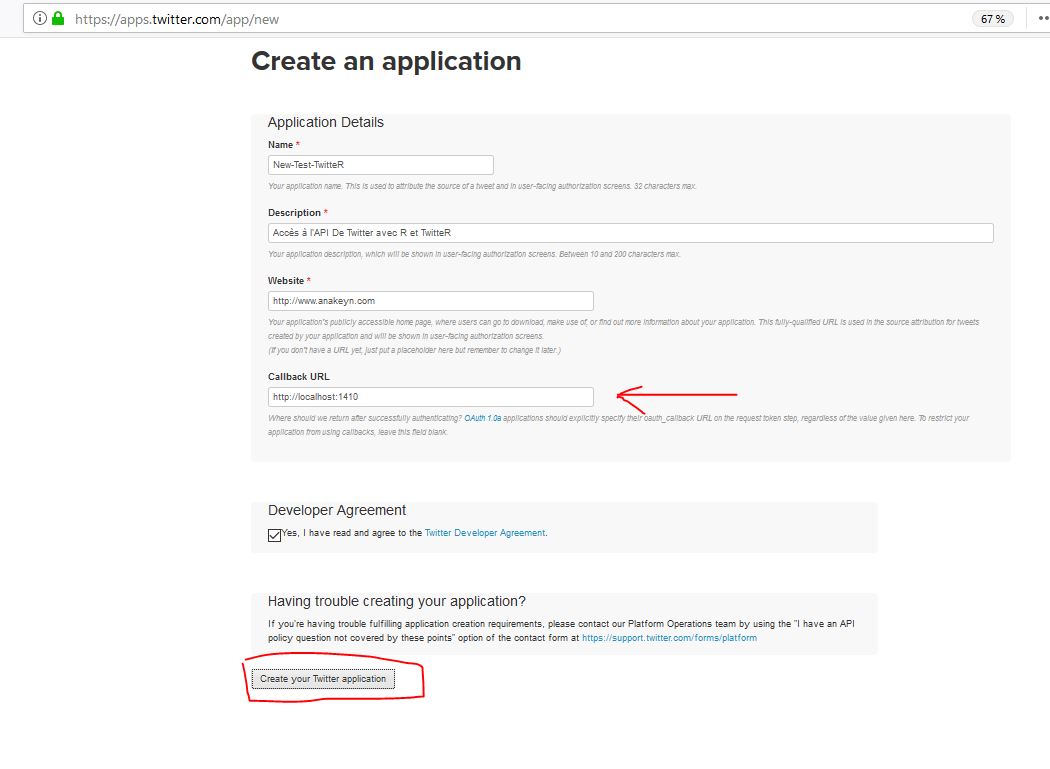
5 – Sur la page suivante cliquez sur l’onglet « Keys and Access Tokens »
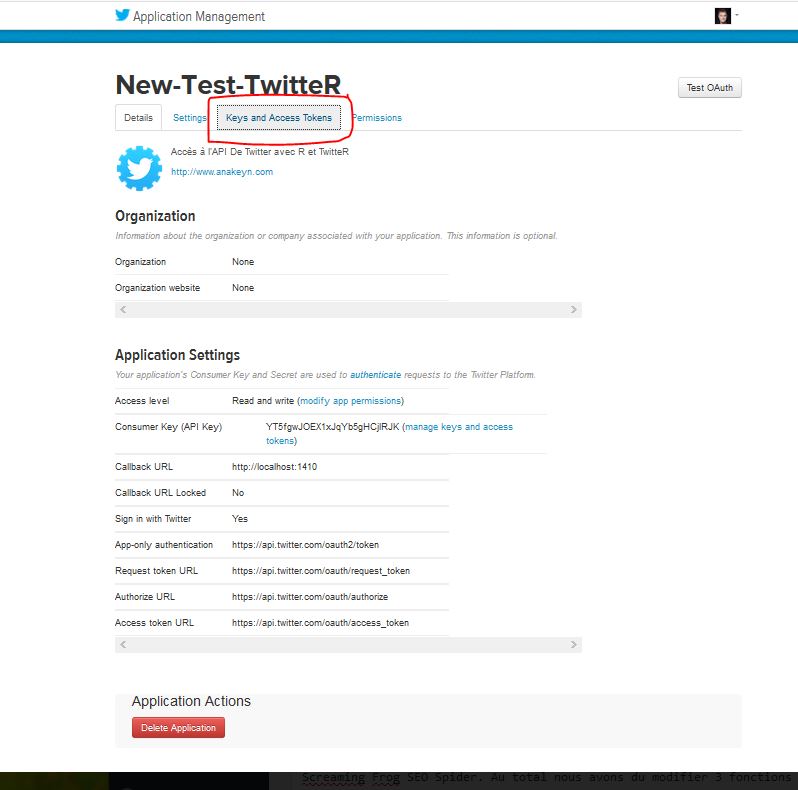
6 – Sur la page des clés et jetons cliquez en bas sur « Create my access token »
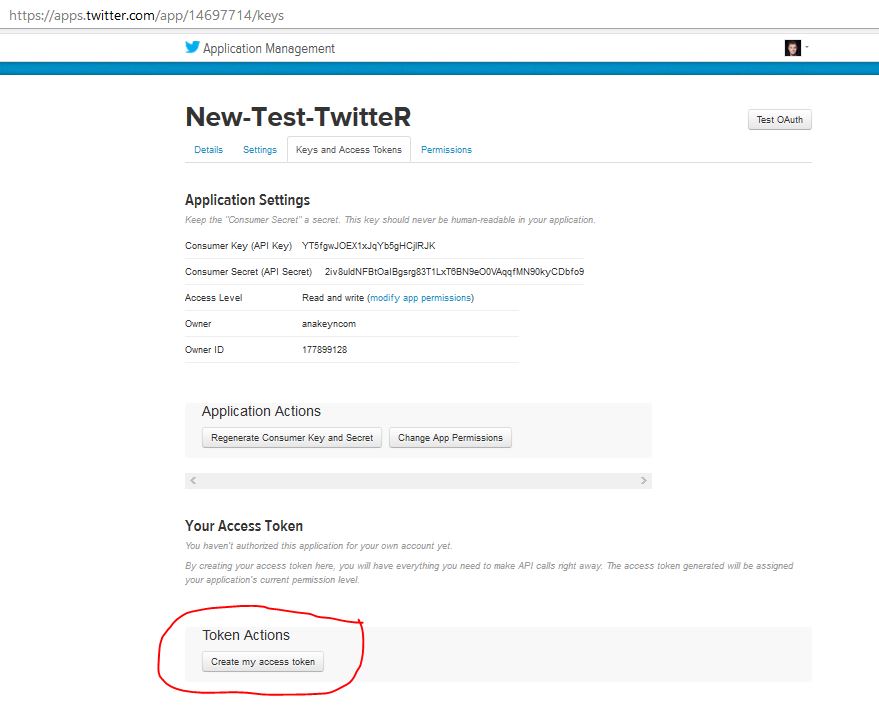
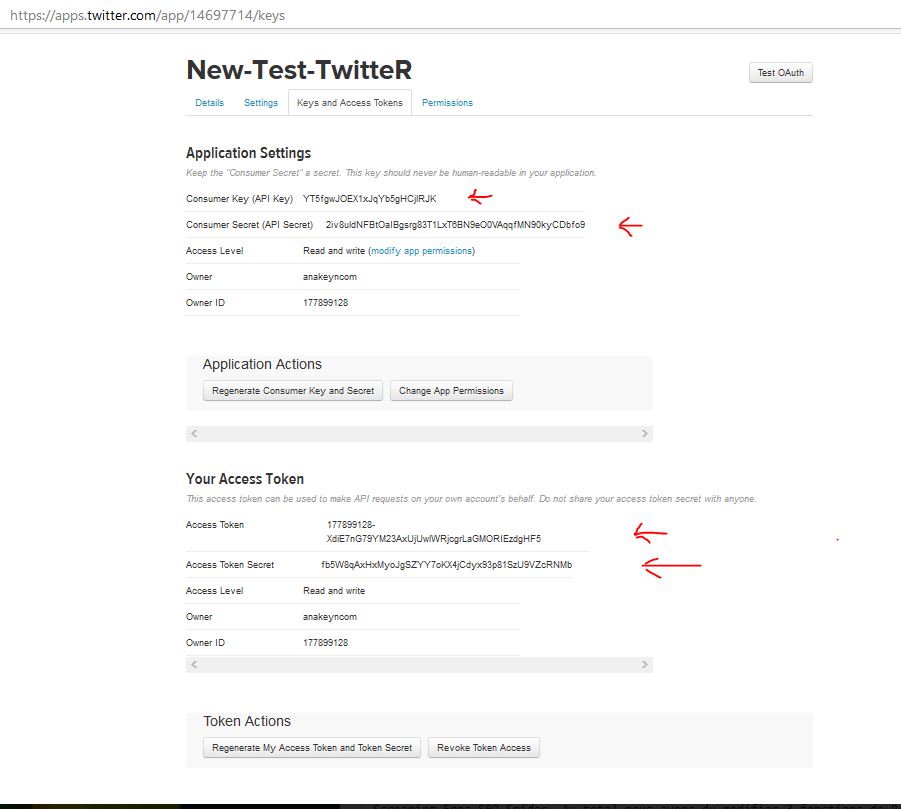
7 – Au final vous devriez avoir l’écran suivant qui comporte vos clés d’API et vos jetons dont vous aurez besoin dans le programme.
Code Source
Vous pouvez copier/coller les morceaux de codes source dans un script R pour les tester.
Vous pouvez aussi récupérér gratuitement le script en entier dans notre boutique à l’adresse : https://www.anakeyn.com/boutique/produit/script-r-exemple-bibliotheque-twitter/
Environnement
Environnement nécessaire à l’application à charger dans votre programme
#'
#'
#Intallation des packages (une fois)
#install.packages("twitteR") #une fois
#install.packages("tm") #une fois
#install.packages("qdap") #une fois
#install.packages("wordcloud")
#Chargement des bibliothèques
library(twitteR) #pour accéder à l'api Twitter.
library(tm) #pour le text mining : Vectorsource(), VCorpus() et le nettoyage removeSparseTerms
library(qdap) #Aussi pour text mining et nettoyage de texte
library(wordcloud) #Nuages de mots clés.
Connexion à L’API
Indiquez les clés que vous avez créées dans Twitter
#' #' #Indiquer les clés et les jetons de votre API https://apps.twitter.com/ (ici mes clés de New-Test-TwitteR : merci d'utiliser les vôtres, de toute façon je vais supprimer ces codes :-)) api_key <- "YT5fgwJOEX1xJqYb5gHCjlRJK" api_secret <- "2iv8uldNFBtOaIBgsrg83T1LxT6BN9eO0VAqqfMN90kyCDbfo9" access_token <- "177899128-XdiE7nG79YM23AxUjUwlWRjcgrLaGMORIEzdgHF5" access_token_secret <- "fb5W8qAxHxMyoJgSZYY7oKX4jCdyx93p81SzU9VZcRNMb" #Connexion à l'API setup_twitter_oauth(api_key,api_secret,access_token,access_token_secret)
Récupération de Tweets
On a choisi de récupérer 1000 tweets max depuis hier. (Si vous demandez trop de tweets à l’API de Twitter elle peut temporiser.)
#'
#'
#Formatage de dates en chaînes de caractères. Peut être utile selon les cas.
strlast30days=as.character(Sys.Date()-30)
strlast7days=as.character(Sys.Date()-7)
strYesterday = as.character(Sys.Date()-1) #on a choisi 1 jour en arrière
strToday = as.character(Sys.Date())
#Récupération des derniers 1000 tweets max depuis hier pour Macron sans les Retweets
macron.tweets = searchTwitter('-RT Macron', since=strYesterday, n=1000, lang="fr")
#Récupération des derniers 1000 tweets max depuis hier pour Wauquiez sans les Retweets
wauquiez.tweets = searchTwitter('-RT Wauquiez', since=strYesterday, n=1000, lang="fr")
#Récupération des derniers 1000 tweets max depuis hier pour Mélenchon sans les Retweets
melenchon.tweets = searchTwitter('-RT Melenchon', since=strlast30days, n=1000, lang="fr")
#Récupération des derniers 1000 tweets max depuis hier pour Le Pen sans les Retweets
lepen.tweets = searchTwitter('-RT Le Pen', since=strlast30days, n=1000, lang="fr")
Vérification des dates des plus vieux Tweets
Par curiosité regardons le nombre de tweets et les dates des plus vieux tweets pour chacune des personnes pour voir si cela remonte beaucoup dans le temps.
#' #' #Nombres de Tweets récupérés length(macron.tweets) length(wauquiez.tweets) length(melenchon.tweets) length(lepen.tweets) #Date/heure du tweet le plus ancien macron.tweets[[length(macron.tweets)]][["created"]] wauquiez.tweets[[length(wauquiez.tweets)]][["created"]] melenchon.tweets[[length(melenchon.tweets)]][["created"]] lepen.tweets[[length(lepen.tweets)]][["created"]]
> length(macron.tweets)
[1] 1000
> length(wauquiez.tweets)
[1] 1000
> length(melenchon.tweets)
[1] 1000
> length(lepen.tweets)
[1] 1000
>
> #Date/heure du tweet le plus ancien
> macron.tweets[[length(macron.tweets)]][[« created »]]
[1] « 2018-01-18 08:41:53 UTC »
> wauquiez.tweets[[length(wauquiez.tweets)]][[« created »]]
[1] « 2018-01-17 09:46:20 UTC »
> melenchon.tweets[[length(melenchon.tweets)]][[« created »]]
[1] « 2018-01-16 17:59:08 UTC »
> lepen.tweets[[length(lepen.tweets)]][[« created »]]
[1] « 2018-01-16 17:33:25 UTC »
>
Pour Macron les 1000 tweets sont atteint en moins de 3 heures et pour les autres il faut attendre parfois plus de 24 heures.
Quoiqu’il en soit les tweets collent assez fortement à l’actualité pour tous.
Récupération des textes et nettoyage
Ici on va nettoyer les tweets pour enlever les informations non pertinentes.
#'
#'
#On récupère uniquement les textes des tweets
macron.text = lapply(macron.tweets, function(t) t$getText())
wauquiez.text = lapply(wauquiez.tweets, function(t) t$getText())
melenchon.text = lapply(melenchon.tweets, function(t) t$getText())
lepen.text = lapply(lepen.tweets, function(t) t$getText())
#Nettoyage ici car pb dans les fonction tm_map de nettoyage de corpus ???
#on enlève les URLs
macron.text <- gsub("(f|ht)tp(s?)://\\S+", "", macron.text)
wauquiez.text <- gsub("(f|ht)tp(s?)://\\S+", "", wauquiez.text)
melenchon.text <- gsub("(f|ht)tp(s?)://\\S+", "", melenchon.text)
lepen.text <- gsub("(f|ht)tp(s?)://\\S+", "", lepen.text)
#On remplace les caractères spéciaux par des blancs
macron.text <- gsub("[][!#$%()*,.:;<=>@^_|~.{}]", " ", macron.text)
wauquiez.text <- gsub("[][!#$%()*,.:;<=>@^_|~.{}]", " ", wauquiez.text)
melenchon.text <- gsub("[][!#$%()*,.:;<=>@^_|~.{}]", " ", melenchon.text)
lepen.text <- gsub("[][!#$%()*,.:;<=>@^_|~.{}]", " ", lepen.text)
# Replace abbreviations
macron.text <- replace_abbreviation(macron.text)
wauquiez.text <- replace_abbreviation(wauquiez.text)
melenchon.text <- replace_abbreviation(melenchon.text)
lepen.text <- replace_abbreviation(lepen.text)
# Replace contractions
macron.text <- replace_contraction(macron.text)
wauquiez.text <- replace_contraction(wauquiez.text)
melenchon.text <- replace_contraction(melenchon.text)
lepen.text <- replace_contraction(lepen.text)
# Replace symbols with words
macron.text <- replace_symbol(macron.text)
wauquiez.text <- replace_symbol(wauquiez.text)
melenchon.text <- replace_symbol(melenchon.text)
lepen.text <- replace_symbol(lepen.text)
#Enlève la ponctuation
macron.text <- removePunctuation(macron.text)
wauquiez.text <- removePunctuation(wauquiez.text)
melenchon.text <- removePunctuation(melenchon.text)
lepen.text <- removePunctuation(lepen.text )
#Enlève les nombres
macron.text <- removeNumbers(macron.text)
wauquiez.text <- removeNumbers(wauquiez.text)
melenchon.text <- removeNumbers(melenchon.text)
lepen.text <- removeNumbers(lepen.text)
#bas de casse : en minuscule
macron.text <- tolower(macron.text)
wauquiez.text <- tolower(wauquiez.text)
melenchon.text <- tolower(melenchon.text)
lepen.text<- tolower(lepen.text)
#Premier nettoyage mots non significatifs avec stopwords("french")
macron.text <- removeWords(macron.text, stopwords("french") )
wauquiez.text <- removeWords(wauquiez.text, stopwords("french") )
melenchon.text <- removeWords(melenchon.text, stopwords("french") )
lepen.text <- removeWords(lepen.text, stopwords("french") )
#Nettoyage mots non significatifs 2 :
#Ici on récupère un fichier de stopwords sur le Net.
stopwords_fr <- scan(file = "http://members.unine.ch/jacques.savoy/clef/frenchST.txt", what = character())
macron.text <- removeWords(macron.text, stopwords_fr )
wauquiez.text <- removeWords(wauquiez.text, stopwords_fr )
melenchon.text <- removeWords(melenchon.text, stopwords_fr )
lepen.text <- removeWords(lepen.text, stopwords_fr )
#Nettoyage mots non significatifs 3 : liste spécifique fournie par nos soins.
specificWords <- c("cest", "faut", "être", "comme", "non", "alors", "depuis",
"fait", "quil")
macron.text <- removeWords(macron.text, specificWords )
wauquiez.text <- removeWords(wauquiez.text, specificWords )
melenchon.text <- removeWords(melenchon.text , specificWords )
lepen.text <- removeWords(lepen.text, specificWords )
#Nettoyage mots personnalisés en fonction des cas
macron.text <- removeWords(macron.text, c("macron", "emmanuel", "emmanuelmacron") )
wauquiez.text <- removeWords(wauquiez.text, c("laurent", "wauquiez", "laurentwauquiez") )
melenchon.text <- removeWords(melenchon.text, c("melenchon", "mélenchon", "jean-luc", "jeanluc", "jeanlucmelenchon", "jlmelenchon") )
lepen.text <- removeWords(lepen.text, c("marine", "le pen", "lepen", "marinelepen") )
#Nettoyage des blancs
macron.text <- stripWhitespace(macron.text)
wauquiez.text <- stripWhitespace(wauquiez.text)
melenchon.text <- stripWhitespace(melenchon.text)
lepen.text<- stripWhitespace(lepen.text)
#/Nettoyage
Retraitement des données pour le « Text Mining »
Ici on va retraiter les données pour les mettre dans des formats intéressants pour la « fouille de données »
#' #' #Transformations pour traitements. #Transformation en vecteurs Vmacron.text <- unlist(macron.text) Vwauquiez.text <- unlist(wauquiez.text) Vmelenchon.text <- unlist(melenchon.text) Vlepen.text <- unlist(lepen.text) #Transformation en vecteurs source macron.source <- VectorSource(Vmacron.text) wauquiez.source <- VectorSource(Vwauquiez.text) melenchon.source <- VectorSource(Vmelenchon.text) lepen.source <- VectorSource(Vlepen.text) #Transformation en Corpus macron.corpus <- VCorpus(macron.source) wauquiez.corpus <- VCorpus(wauquiez.source) melenchon.corpus <- VCorpus(melenchon.source) lepen.corpus <- VCorpus(lepen.source) # creation de Term Document Matrix macron.tdm <- TermDocumentMatrix(macron.corpus) wauquiez.tdm <- TermDocumentMatrix(wauquiez.corpus) melenchon.tdm <- TermDocumentMatrix(melenchon.corpus) lepen.tdm <- TermDocumentMatrix(lepen.corpus) # Conversion TDM en matrice macron.m <- as.matrix(macron.tdm) wauquiez.m <- as.matrix(wauquiez.tdm) melenchon.m <- as.matrix(melenchon.tdm) lepen.m <- as.matrix(lepen.tdm) # Somme des lignes pour fréquences des termes et tri par fréquence. macron.term_frequency <- rowSums(macron.m) macron.term_frequency <- sort(macron.term_frequency, decreasing = TRUE) wauquiez.term_frequency <- rowSums(wauquiez.m) wauquiez.term_frequency <- sort(wauquiez.term_frequency, decreasing = TRUE) melenchon.term_frequency <- rowSums(melenchon.m) melenchon.term_frequency <- sort(melenchon.term_frequency, decreasing = TRUE) lepen.term_frequency <- rowSums(lepen.m) lepen.term_frequency <- sort(lepen.term_frequency, decreasing = TRUE)
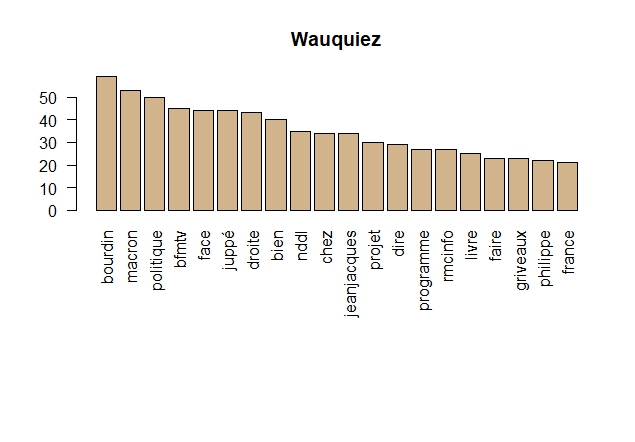
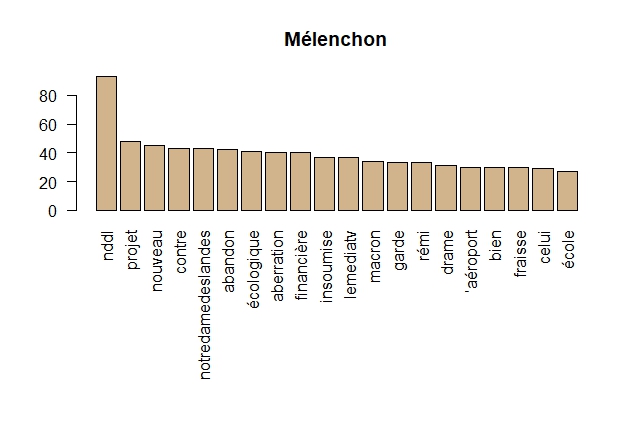
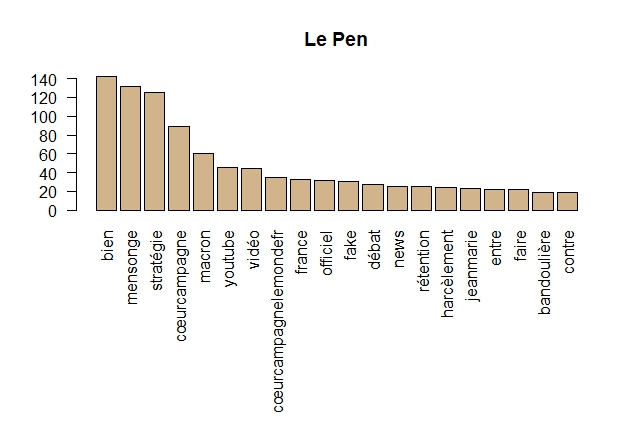
Graphiques en barre
Graphiques en barre pour les 20 premiers termes de chaque personnalité
#' #' Graphiques en barre pour les 20 premiers termes. par(mar = c(10,4,4,2)) #pour recadrer le graphiques suite à des labels trop grands (ex : notredamedeslandes) barplot(macron.term_frequency[1:20], col = "tan", las = 2, main="Macron") barplot(wauquiez.term_frequency[1:20], col = "tan", las = 2, main="Wauquiez") barplot(melenchon.term_frequency[1:20], col = "tan", las = 2, main="Mélenchon") barplot(lepen.term_frequency[1:20], col = "tan", las = 2, main="Le Pen")
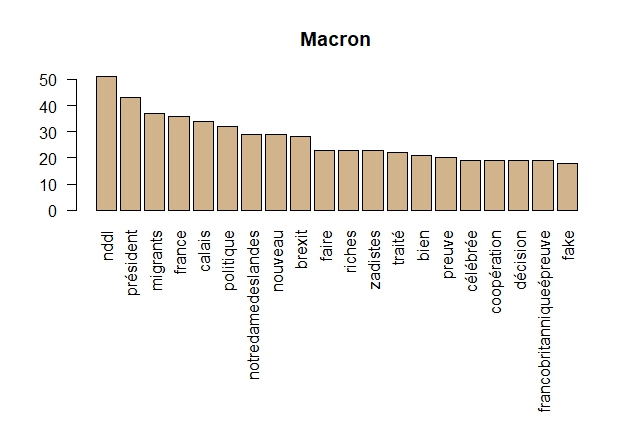
Il n’aura échappé à personne que Notre Dame des Landes était le Thème d’hier et la visite de Theresa May celui d’aujourdhui 🙂 !
On s’intéresse plus à Jean-Jacques Bourdin qu’à ce que dit Wauquiez ?
Mélenchon répond quand même un peu à Macron sur NDDL :
Marine Le Pen toujours empêtrée dans la Présidentielle ??
Nuages de Mots clés
Nuage Mots clés pour chacune des personnalités
#'
#'
#WordCloud pour Macron
par(mfrow=c(1,1)) #Raz Layout
#Jeu de données des mots et des occurences.
macron.word_freqs <- data.frame(term = names(macron.term_frequency), num = macron.term_frequency)
# Nuage de Mots Clés
wordcloud(macron.word_freqs$term, macron.word_freqs$num, max.words = 100, colors = c("grey80", "darkgoldenrod1", "tomato"), title = "Macron")
#WordCloud pour Wauquiez
#Jeu de données des mots et des occurences.
wauquiez.word_freqs <- data.frame(term = names(wauquiez.term_frequency), num = wauquiez.term_frequency)
# Nuage de Mots Clés
wordcloud(wauquiez.word_freqs$term, wauquiez.word_freqs$num, max.words = 100, colors = c("grey80", "darkgoldenrod1", "tomato"))
#WordCloud pour Mélenchon
#Jeu de données des mots et des occurences.
melenchon.word_freqs <- data.frame(term = names(melenchon.term_frequency), num = melenchon.term_frequency)
# Nuage de Mots Clés
wordcloud(melenchon.word_freqs$term, melenchon.word_freqs$num, max.words = 100, colors = c("grey80", "darkgoldenrod1", "tomato"))
#WordCloud pour Le Pen
#Jeu de données des mots et des occurences.
lepen.word_freqs <- data.frame(term = names(lepen.term_frequency), num = lepen.term_frequency)
# Nuage de Mots Clés
wordcloud(lepen.word_freqs$term, lepen.word_freqs$num, max.words = 100, colors = c("grey80", "darkgoldenrod1", "tomato"))
Macron :

Wauquiez :

Mélenchon :

Le Pen :

Nuage de Mots Clés communs
Dans ce nuage de mots clés on affiche les mots les plus communs aux différentes personnalités
#'
#'
###############################################
# Nuage de Mots clés en commun !
all_macron <- paste(macron.text , collapse = "")
all_wauquiez <- paste(wauquiez.text , collapse = "")
all_melenchon <- paste(melenchon.text , collapse = "")
all_lepen <- paste(lepen.text , collapse = "")
all_tweets <- c(all_macron, all_wauquiez, all_melenchon, all_lepen)
# transformation
all_source <- VectorSource(all_tweets)
all_corpus <- VCorpus(all_source)
all_tdm <- TermDocumentMatrix(all_corpus)
all_m <- as.matrix(all_tdm)
# Mots clés en commun
commonality.cloud(all_m, colors = "steelblue1",
max.words = 100)

Nuage de Mots Clés disjoints
Dans ce nuage de mots clés on affiche les mots qui différencient les différentes personnalités.
#'
#'
#Mots clés disjoints
# Ajoute des noms de colonnes.
colnames(all_m) = c("Macron", "Wauquiez", "Mélenchon", "Le Pen")
#Plot le graphique.
comparison.cloud(all_m,
random.order=FALSE,
colors = c("orange", "blue", "red", "black"),
title.size=1.5,
max.words = 500)
Couleurs : Macron : jaune-orangé, Wauquiez : bleu-violet, Mélenchon : rouge, Le Pen : Noir

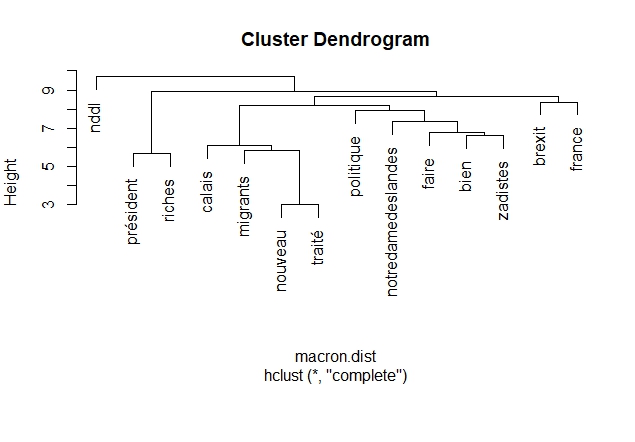
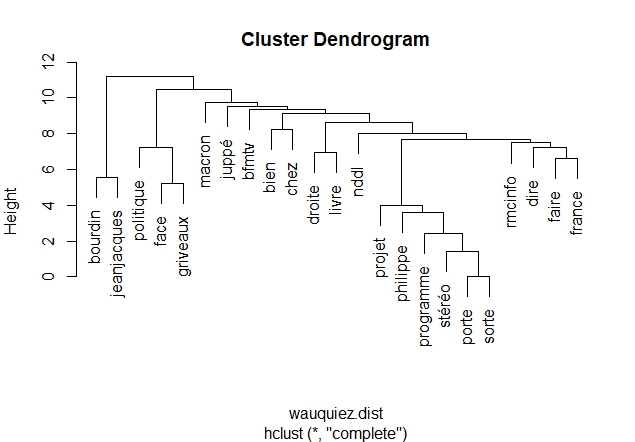
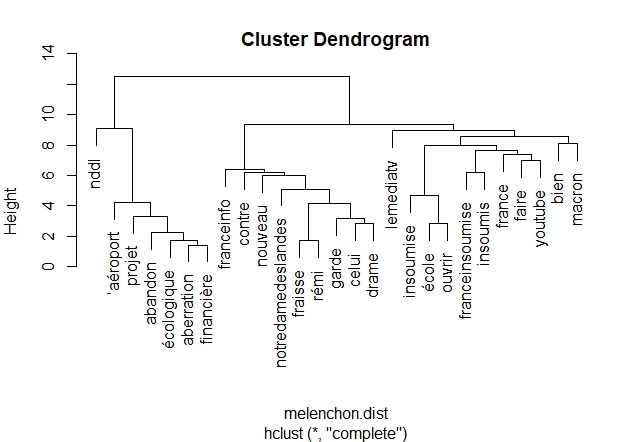
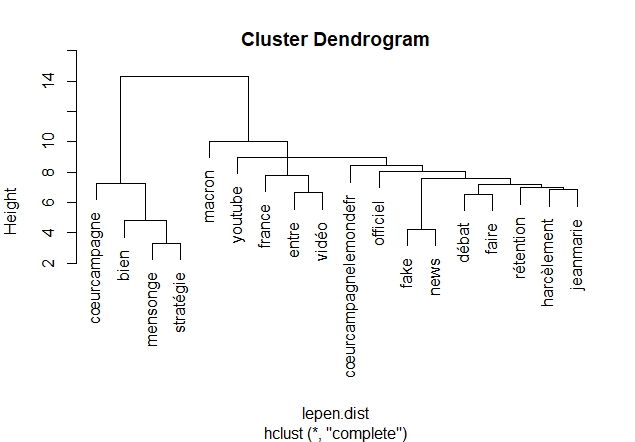
Dendrogrammes
Un dendrogramme est un diagramme que l’on utilise pour présenter une classification hiérarchique. Dans notre cas nous allons classifier les mots pour voir ceux qui sont proches les uns des autres.
#' #' #Dendrogramme pour Macron par(mfrow=c(1,1)) #Raz Layout # On supprime les termes clairsemées de la Term Document Matrix macron.tdm2 <- removeSparseTerms(macron.tdm , sparse = 0.98) # Transformation en matrice macron.m2 <- as.matrix(macron.tdm2) # Transformation en Data Frame macron.df2 <- as.data.frame(macron.m2) str(macron.df2) # Calcul de la distance entre les termes macron.dist <- dist(macron.df2) # Création de la classification hiérarchique (Hierarchical clustering:hc) macron.hc <- hclust(macron.dist) # Plot le dendrogram par(mar = c(8,4,4,2)) #pour cadrage du diagramme plot(macron.hc) #Dendrogramme pour Wauquiez par(mfrow=c(1,1)) #Raz Layout # On supprime les termes clairsemées de la Term Document Matrix wauquiez.tdm2 <- removeSparseTerms(wauquiez.tdm , sparse = 0.98) # Transformation en matrice wauquiez.m2 <- as.matrix(wauquiez.tdm2) # Transformation en Data Frame wauquiez.df2 <- as.data.frame(wauquiez.m2) # Calcul de la distance entre les termes wauquiez.dist <- dist(wauquiez.df2) # Création de la classification hiérarchique (Hierarchical clustering:hc) wauquiez.hc <- hclust(wauquiez.dist) # Plot le dendrogram par(mar = c(5,4,4,2)) #pour cadrage du diagramme plot(wauquiez.hc) #Dendrogramme pour Mélenchon par(mfrow=c(1,1)) #Raz Layout # On supprime les termes clairsemées de la Term Document Matrix melenchon.tdm2 <- removeSparseTerms(melenchon.tdm , sparse = 0.98) # Transformation en matrice melenchon.m2 <- as.matrix(melenchon.tdm2) # Transformation en Data Frame melenchon.df2 <- as.data.frame(melenchon.m2) # Calcul de la distance entre les termes melenchon.dist <- dist(melenchon.df2) # Création de la classification hiérarchique (Hierarchical clustering:hc) melenchon.hc <- hclust(melenchon.dist) # Plot le dendrogram par(mar = c(5,4,4,2)) #pour cadrage du diagramme plot(melenchon.hc) #Dendrogramme pour Le Pen par(mfrow=c(1,1)) #Raz Layout # On supprime les termes clairsemées de la Term Document Matrix lepen.tdm2 <- removeSparseTerms(lepen.tdm , sparse = 0.98) # Transformation en matrice lepen.m2 <- as.matrix(lepen.tdm2) # Transformation en Data Frame lepen.df2 <- as.data.frame(lepen.m2) # Calcul de la distance entre les termes lepen.dist <- dist(lepen.df2) # Création de la classification hiérarchique (Hierarchical clustering:hc) lepen.hc <- hclust(lepen.dist) # Plot le dendrogram par(mar = c(5,4,4,2)) #pour cadrage du diagramme plot(lepen.hc)
Dendrogramme Macron :
Dendrogramme Wauquiez :
Dendrogramme Mélenchon :
Dendrogramme Le Pen :
Merci pour votre attention, n’hésitez pas à faire vos remarques et suggestions en commentaires.
A Bientôt,
Pierre