Partager la publication "Recherche de facteurs SEO avec le Machine Learning (partie 1)"
Quels sont les facteurs SEO qui permettent de positionner une page de son site sur la première page de résultats de Google ?
Voici la question à 1 million de US$ que se posent tous les possesseurs de sites depuis maintenant près de 20 ans !!!
Jusqu’à récemment, la réponse se faisait de façon plutôt empirique à partir d’avis et d’expériences d’experts du référencement, d’informations au compte goutte du fameux Matt Cutts de Google ou de fournisseurs de données et d’outils SEO comme MOZ, Majestic SEO, Ahrefs, SEMrush, Yooda …
Aujourd’hui, la communauté SEO commence à s’intéresser à ce que l’on a appelle le « Data SEO » c’est à dire l’utilisation des techniques des Data Sciences au service du SEO.
Dans cet exercice (en 3 parties) nous allons vous proposer de rechercher, à partir de données récoltées sur le Web ou bien crawlées, des facteurs SEO importants à partir d’algorithmes de Machine Learning.
Pour cela il nous faut en premier lieu un fichier comportant des informations de positionnement d’une page en fonction d’un mot-clé. En d’autres termes un fichier qui nous donne :
- La position d’une page pour un mot clé donné dans les résultats de Google
- Le mot clé pour laquelle cette page est positionnée
- L’url de la page
On trouve ces informations par exemple chez SEMrush ou chez Yooda pour les mots clés en Français.
Ensuite, il faut pouvoir enrichir ces informations avec tout ce que l’on pourra récupérer en crawlant les pages ou à partir d’API de fournisseurs de données.
L’idéal serait de pouvoir récupérer des informations concernant la page elle-même (https, mot clé dans les titres), la page dans son site (profondeur, page rank interne…), les liens externes vers la page (avec une notion de qualité) … Mais bon cela vous obligerait à avoir plusieurs abonnements payants
API Yooda Insight
Pour cette exercice nous utiliserons comme source de positionnements l’API de Yooda actuellement en bêta test et que nous avions présentée dans un article précédent : Test de l’API Insight de Yooda avec le logiciel R
Si vous souhaitez aussi tester l’API Insight, et reproduire entièrement ce test, demandez un accès à Yooda sur cette page : Accès API en Bêta Gratuite.
Logiciel R
Comme dans nos articles précédents nous vous invitons à téléchargez Le Logiciel R sur ce site https://cran.r-project.org/, ainsi que l’environnement de développement RStudio ici : https://www.rstudio.com/products/rstudio/download/, afin de pouvoir tester vous même le code source.
Test avec R
Ce test sera divisé en 3 parties. Dans cet article nous testerons les informations que nous pouvons créer à partir des urls et des noms de domaines. Dans un prochain article nous utiliserons un crawler pour récupérer des données « techniques » sur les pages, et enfin dans un dernier article nous créerons des données mots-clés vs pages en fonction du contenu des pages.
Pour illustrer le propos nous avons décidé de nous intéresser au secteur des « cosmétiques bio ». Il nous fallait donc des pages de sites qui étaient dans la base de Yooda. Comme l’API ne fournit pas pour l’instant de liste de sites à partir de mots-clés, nous avons été directement rechercher les « Leaders » de la thématique « cosmétiques bio » sur l’interface Web.
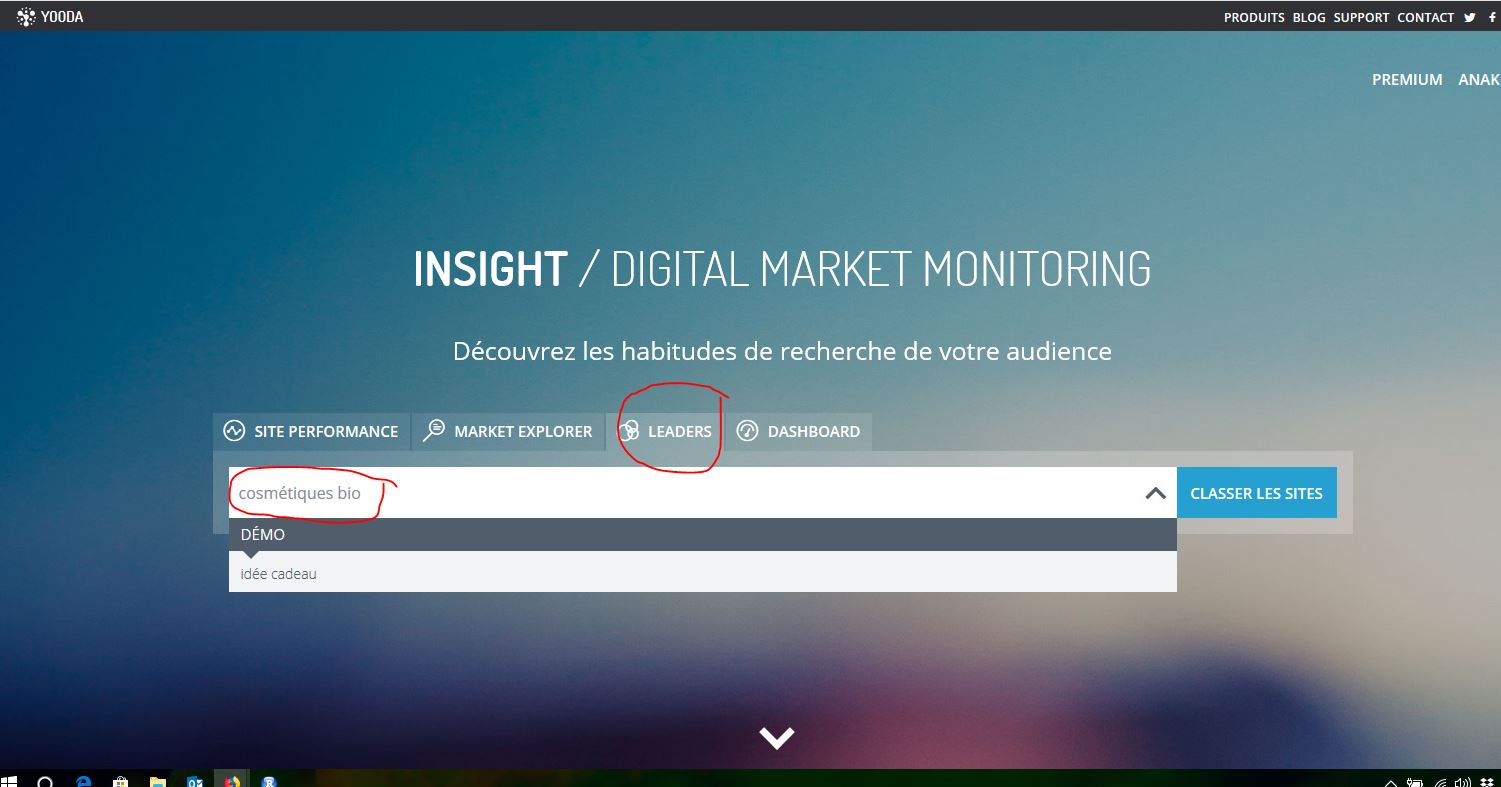
Yooda vous fournit une liste de site leaders dans la thématique dont vous pouvez recopier les domaines :
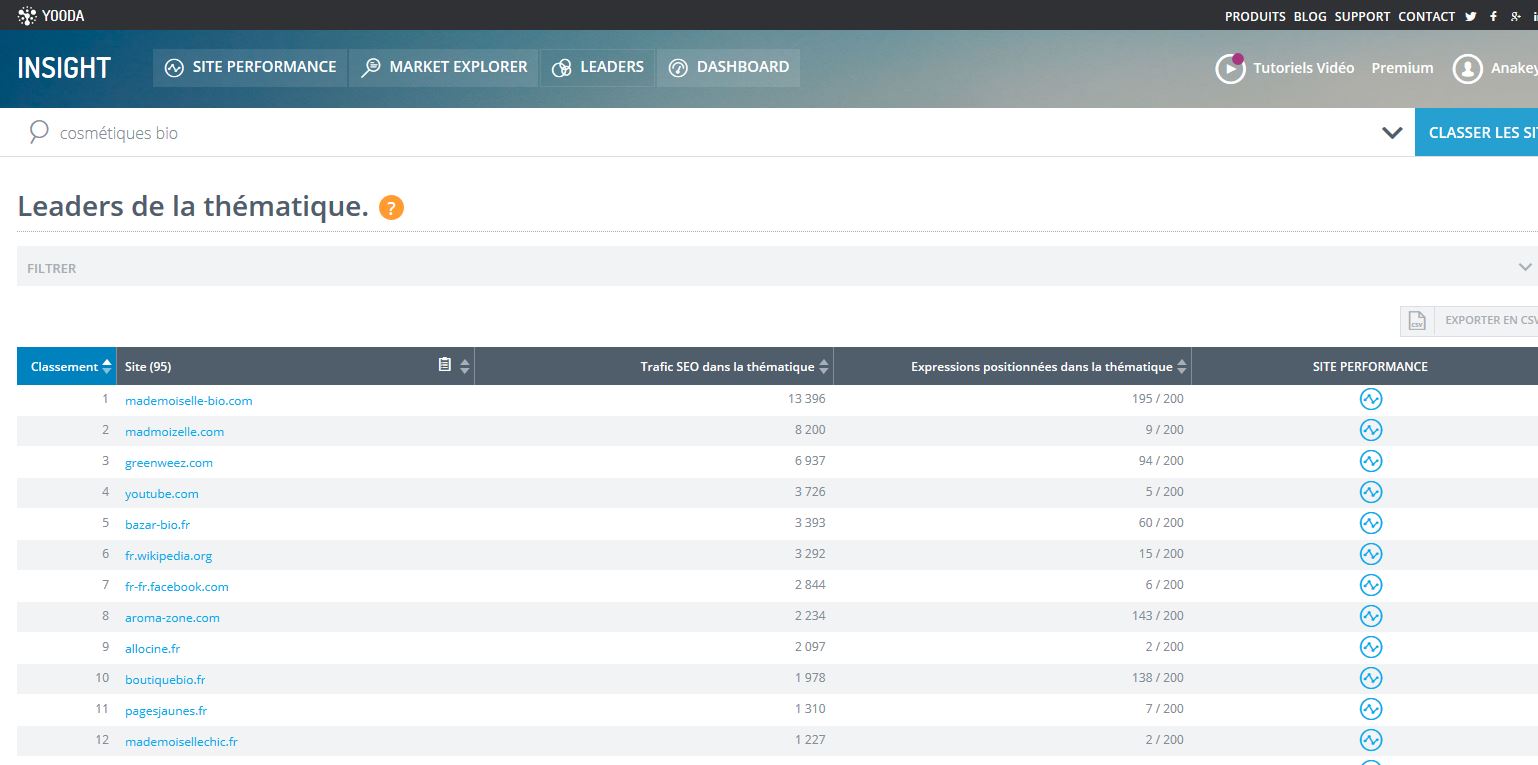
Même si vous n’avez pas de compte Premium, vous pouvez rapidement récupérer une liste de sites, par exemple en faisant varier les mots clés (mais toujours dans la thématique). Je suggère d’éviter de garder des sites généralistes comme Youtube, FaceBook ou encore Wikipedia et qui ne nous intéressent pas dans cet exercice.
Voici le fichier d’une cinquantaine de domaines que j’ai créé dans cette thématique : domains.csv
Code Source R
Vous pouvez copier/coller les morceaux de code source dans un script R pour les tester.
Vous pouvez aussi récupérer gratuitement le source en entier dans notre boutique : https://www.anakeyn.com/boutique/produit/script-r-facteurs-seo-et-ml-1/
Bibliothèques utiles
Chargement des bibliothèques utilisées dans cette première partie. Si c’est la première fois que vous chargez ces bibliothèques vous devez au préalable installer les « packages ».
#
#
#########################################################################################################
#Premiere partie - détermination de facteur SEO à partir des données Yooda et quelques enrichissements
#########################################################################################################
#### Chargement des bibliothèques utiles ##########################################
#Installer une fois
#install.packages("httr") #à éxecuter une fois - déjà installé chez moi
#install.packages("jsonlite") #une fois
#install.packages("urltools") #une fois
#install.packages("dplyr") #une fois
#install.packages("openssl")#une fois
#install.packages("stringr") #une fois
#install.packages("stringi") #une fois
#install.packages("pROC") #une fois
#install.packages("caret") #une fois
#install.packages("naivebayes") #une fois
#install.packages("randomforest") #une fois
#install.packages("ranger") #une fois
#install.packages("vtreat") #une fois
#install.packages("magrittr") #une fois
#install.packages("xgboost") #une fois
#Charger les bibliothèques
library(httr) #package utile pour récupérer des données sur le Web. #pour GET, content ...
library(jsonlite) #pcakage pour travailler avec les données au format JSON
library(urltools) #pour url_parse
library(dplyr) #pour mutate
library(openssl) #pour downloadd_ssl_cert
library(stringr) #pour str_sub
library(stringi) #pour stri_count_coll
library(pROC) #pour ROC et AUC
library(caret) #pour varImp dans glm
library(naivebayes) #métode naive bayes
library(randomForest) #méthode Random Forest 1 avec randomForest
library(ranger) #méthode Random Forest 2 avec ranger
library(vtreat) #pour retraitement préalable pour XGBoost
library(magrittr) #pour le "pipe" %>%
library(xgboost) #pour XGBoost
###################################################################################
API Yooda Insight
Vous devez indiquer ici votre clé d’API. on en profite pour vérifier nos crédits. De mémoire au départ nous en avons 10 millions il me semble.
#
#
##### Votre Clé d'API
MyAPIKey <- "xxxxxxxxxxxxxxxxxxxxxxxxxxx" #ICI indiquer votre clé d'API fournie par Yooda.
#Verification de mes crédits
MyApiYoodaURLCredits <- paste("https://api.yooda.com/subscriptions/credits?apikey=", MyAPIKey, sep ="")
MyApiYoodaURLCredits
responseCredits <- GET(url = MyApiYoodaURLCredits) #Attention le test de crédits mange 1 crédit 🙁
httr::content(responseCredits)$content #Affiche les crédits restants
Récupération des données de positionnement avec l’API Yooda Insight
Attention l’application mange beaucoup de crédits : 2 millions pour 200.000 enregistrements récupérés sur un total de 10 millions qui vous sont alloués au départ. Il faudra donc éviter de lancer le processus complet plusieurs fois.
Le processus se fait à partir du fichier de domaines que nous avions préalablement établi. Celui-ci doit se trouver dans le répertoire courant de votre script R. Pour éviter de tout perdre en cas de plantage nous sauvegardons au fur et à mesure les fichiers de positionnements par domaine dans un sous répertoires « Yooda ».
#
#
MyDomains <- read.csv2(file="domains.csv", stringsAsFactors=FALSE)
#str(MyDomains) #verif
#nrow(MyDomains) #verif
#MyDomains[1,1] #verif
###########################################################################################
###### Recuperation des pages/mots-clés/position dans Yooda - max 5000 pages par Site.
###########################################################################################
#Sauvegarde dans un sous répertoire Yooda au fur et à mesure si plantage. Création du répertoire
DIR<-getwd() #Répertoire courant
foldername<-"Yooda"
path<-paste(DIR,"/", foldername ,sep = "")
if (!file.exists(path)) dir.create(path, recursive = TRUE, mode = "0777")
YoodaErrors <- c(400, 401, 402, 403, 404, 429, 500) #pour repérer les erreurs Yooda
for (i in 1:nrow(MyDomains)) {
###########################################################################################
###### Recuperation du domaine / sous domaine
###########################################################################################
MyDomain <- MyDomains[i,1] #Domaine étudié
print(MyDomain)
###############################################
#Récupération de l'id du site
MyApiYoodaURLId <- paste("https://api.yooda.com/insight/domains/", MyDomain, "?apikey=", MyAPIKey, sep ="")
MyApiYoodaURLId #Vérification de l'url
responseURL <- GET(url = MyApiYoodaURLId) #Appel API Yooda.
if (!(responseURL$status_code %in% YoodaErrors)) {
#str(responseURL) #verif
MyDomainId <- httr::content(responseURL)$content$id # Recupération de l'Id de domaine ou sous domaine
MyDomainId #Verification
#Récupération des mots clés: #GET /insight/domains/{domain_id}/keywords
MyApiYoodaURLKeywords <- paste("https://api.yooda.com/insight/domains/", MyDomainId, "/keywords?apikey=", MyAPIKey, sep ="")
MyApiYoodaURLKeywords #Vérification de l'URL de l'API
responseKeywords <- GET(url = MyApiYoodaURLKeywords) #Appel API Yooda
#httr::content(responseKeywords) #Verif .
http_type(responseKeywords) #Verif type reçu
#Récupération des données à partir du format JSON de la réponse de l'API
DataKeywords <- fromJSON(httr::content(responseKeywords, as = "text"), flatten=TRUE)$content$items_list
#on complète par le nom de domaine (sera utile quand on regroupera tous les fichiers et pour tester le ssl)
DataKeywords$domain <- MyDomain
#str(DataKeywords) #Vérifions que l'on a bien un Data Frame
##### On sauvegarde au fur et à mesure au cas ou il y ait un plantage
MyFileName <- paste("Domain-", MyDomain, ".csv", sep="") #on ajoute un préfixe pour faciliter la lecture par la suite
filepath<-paste(path,"/",MyFileName, sep = "")
write.csv2(DataKeywords, file = filepath) #Ecriture du fichier .csv avec séparateur ";"
} #/pas d'erreur YOODA
} #/for fin de la récupération des données dans l'API De YOODA
Regroupement des fichiers de domaines
Dans cette partie nous regroupons tous les fichiers de positionnements par domaine dans un seul jeu de données.
#
#
###############################################################################
### Je regroupe tous les fichiers dans un seul data.frame et un seul fichier
###############################################################################
#lecture des fichiers de positionnements par domaine
domainFiles <- paste0(path,"/",list.files(path = path, pattern = "Domain-.*\\.csv$"))
AllDomainFiles <- lapply(domainFiles,function(i){
read.csv(i, check.names=FALSE, header=TRUE, sep=";", quote="\"")
})
#class(AllDomainFiles) #C'est une liste
#str(AllDomainFiles) #verif
AllDataKeywords <- do.call(rbind, AllDomainFiles) #transformation en data.frame
rm(AllDomainFiles) #pour faire de la place mémoire
str(AllDataKeywords) #verif
names(AllDataKeywords)[1] <- "obs_domain_id" #il n'y avait pas de nom à l'id : attention il s'agit de l'id d'une observation pour un domaine (peut servir par la suite)
Variables à expliquer
Normalement la variable « position » est la variable à expliquer en fonction des autres données. Ici les données ne nous donnent que des positions de 1 à 13 dans les résultats de Google. Il aurait été intéressant d’avoir des observations de pages / mots clés moins bien positionnées pour mesurer des « mauvaises » pages.
Comme il nous semble très optimiste de déterminer un modèle permettant de classer les pages sur 13 positions, nous créons 2 variables booléennes, une indiquant la première place ou non, l’autre les 3 premières places ou non.
# # ######## Variables à expliquer levels(as.factor(AllDataKeywords$position)) #combien de niveau de position ? ici 13 #Variable à tester #est-ce Position 1 ?? AllDataKeywords <- mutate(AllDataKeywords, istop1pos = ifelse(position==1, TRUE, FALSE) ) #est-ce dans le Top 3 des positions ? AllDataKeywords <- mutate(AllDataKeywords, istop3pos = ifelse(position<=3, TRUE, FALSE) )
Ajouts de variables explicatives – facteurs SEO
Nous allons ajouter des variables potentiellement explicatives à notre jeu de données :
- kwindomain : compte l’occurence du mot clé dans le domaine.
- kwinurl : compte l’occurence du mot clé dans le reste de l’url.
- ishttps : est-ce une url en https ?
- isSSLEV : le SSL est-il de type Extended Value ?
- urlnchar : nombre de caractères dans l’url.
- urlslashcount : nombre de / dans l’url (pseudo « level »)
Ce sont parmi ces variables explicatives potentielles que l’on doit trouver nos facteurs SEO.
#
#
######## création de Variables explicatives facteurs SEO ??? ici en fonction de l'URL et du domaine
#Ajout Keyword in Domain et Keyword in URL
AllDataKeywords <- mutate(AllDataKeywords, kwindomain = stringi::stri_count_coll(domain, keyword.keyword))
AllDataKeywords <- mutate(AllDataKeywords, kwinurl = stringi::stri_count_coll(url, keyword.keyword)-kwindomain)
#Ajout ishttps
AllDataKeywords$ishttps <- 0
AllDataKeywords$ishttps[which(grepl("https",AllDataKeywords$url))] <- 1
#str(AllDataKeywords) #Verif
#Test certificat https/ssl à validation étendue (EV)
#on va lire uniquement une fois par domaine :
#création d'une dataframe avec les noms de domaines uniques
indexHttps <- data.frame(domain = unique(AllDataKeywords$domain) , isSSLEV = 0 )
#####################################################################
# Detection d'Extended Validation dans SSL
# based on http://giantdorks.org/alain/shell-script-to-check-ssl-certificate-info-like-expiration-date-and-subject/
# et ovh https://github.com/ovh/summit2016-RankingPredict/blob/master/step9_getInfoSSL.R
detectEV <- function(domain) {
try({
chain <- download_ssl_cert(domain, 443)
issuer <- as.list(chain[[1]])$issuer
#print(issuer)
if (grepl("EV", issuer) || grepl("Extended Validation", issuer) )
return(TRUE)
})
return(FALSE)
}
for (i in 1:nrow(indexHttps)) {
#host <- parse_url(indexHttps[i, "domain"])$path
#print(host)
indexHttps[i, "isSSLEV"] <- detectEV(as.character(indexHttps[i, "domain"]))
}
#on récupere isSSLEV dans AllDatakeywords par un merge.
AllDataKeywords <- merge(AllDataKeywords, indexHttps, by = "domain")
#Longueur de l'URL
AllDataKeywords <- mutate(AllDataKeywords, urlnchar = nchar(as.character(url)))
#nombre de slash : peut correspondre à un "niveau" de page dans le site
AllDataKeywords <- mutate(AllDataKeywords, urlslashcount = str_count(as.character(url), "/"))
str(AllDataKeywords) #verif
#on sauvegarde le fichier de positions pour utilisations ultérieures.
write.csv2(AllDataKeywords, file = "AllDataKeywords.csv", row.names = FALSE) #ecriture avec sep ";" sans numéro de ligne.
La structure du jeu de données « AllDataKeywords » est la suivante :
> str(AllDataKeywords)
‘data.frame’: 154979 obs. of 21 variables:
$ domain : Factor w/ 54 levels « 1001pharmacies.com »,..: 1 1 1 1 1 1 1 1 1 1 …
$ obs_domain_id : int 1 2 3 4 5 6 7 8 9 10 …
$ domain_id : int 10053420 10053420 10053420 10053420 10053420 10053420 10053420 10053420 10053420 10053420 …
$ url : Factor w/ 49240 levels « https://www.1001pharmacies.com/ »,..: 1 1 1 160 1 1060 261 1 1398 503 …
$ position : int 1 5 1 2 8 1 3 7 3 1 …
$ score : int 997280 907500 544640 417060 307700 298080 254740 229900 208680 198720 …
$ traffic : int 9973 9075 5446 4171 3077 2981 2547 2299 2087 1987 …
$ keyword.kw_id : int 82195312 1306832 70497009 56197 9276 132043117 3690926 7718477 7726273 3221817 …
$ keyword.keyword : Factor w/ 129660 levels « 100 pharmacie »,..: 12 3527 16 328 3428 641 528 3543 4053 1614 …
$ keyword.search_volume: int 27100 165000 14800 33100 90500 8100 27100 60500 22200 5400 …
$ keyword.competition : num 0.07 0.03 0.07 0.18 0.67 0.65 0.41 0.71 0.99 1 …
$ keyword.cpc : num 0.53 0.34 0.23 0.31 0.56 0.86 0.13 0.41 0.31 0.29 …
$ keyword.results_nb : num 447000 73300000 177000 16500000 9770000 799000 15400000 23300000 1790000 1160000 …
$ istop1pos : logi TRUE FALSE TRUE FALSE FALSE TRUE …
$ istop3pos : logi TRUE FALSE TRUE TRUE FALSE TRUE …
$ kwindomain : int 0 1 1 0 0 0 0 0 0 0 …
$ kwinurl : int 0 0 0 1 0 1 1 0 1 0 …
$ ishttps : num 1 1 1 1 1 1 1 1 1 1 …
$ isSSLEV : num 1 1 1 1 1 1 1 1 1 1 …
$ urlnchar : int 31 31 31 40 31 109 43 31 47 48 …
$ urlslashcount : int 3 3 3 3 3 3 3 3 3 3 …
>
Nous avons aussi sauvegardé le jeu de données dans un fichier .csv. Vous pouvez le récupérer sur notre compte GitHub sous forme de fichier compressé .zip : AllDataKeywords.zip
Machine Learning : Préparation des données.
Dans cette partie nous allons récupérer les données sauvegardées préalablement, sélectionner la variable à expliquer (ici istop3pos) et les variables explicatives (facteurs SEO potentiels ?) puis créer un jeu de données d’entrainement et un jeu de données de test dont nous aurons besoin pour tester les modèles.
#
#
#############################################################################
### Machine Learning sur les données intéressantes
#############################################################################
############################################################################################
####### Pour ceux qui démarrent d'ici on va récupérer les données du ficheir AllDataKeywords.csv
AllDataKeywords <- read.csv2(file = "AllDataKeywords.csv")
#############################################################################
### Creation du fichier de données à tester, de train et de test
#############################################################################
str(AllDataKeywords) #verif des donnnées disponibles.
#Selection des variables.
#on garde les infos en rapport avec l'url
Urlcoltokeep <- c("istop3pos", "kwindomain", "kwinurl", "ishttps", "isSSLEV", "urlnchar", "urlslashcount")
UrlDataKeywords <- AllDataKeywords[, Urlcoltokeep] #Sélection des variables
#str(UrlDataKeywords) #verif
#Decoupage en train et test
## 70% of the sample size
smp_size <- floor(0.70 * nrow(UrlDataKeywords))
## set the seed to make your partition reproductible
set.seed(12345)
train_ind <- sample(seq_len(nrow(UrlDataKeywords)), size = smp_size)
train <- UrlDataKeywords[train_ind, ]
test <- UrlDataKeywords[-train_ind, ]
str(train) #verif
str(test) #verif
Modèle Régression Logistique
Dans ce premier test nous allons tester un algorithme de régression logistique. pour ceux qui souhaitent allez plus loin dans la compréhension du modèle vous pouvez trouver ici : un cours sur la Régression Logistique pour l’apprentissage supervisé de l’université de Lyon.
Bon, pour ceux qui ne souhaitent pas entrer dans les détails, ne vous inquiétez pas, le processus est toujours plus ou moins le même :
- Je divise mon jeu de données de base en 2 paquets : les données d’entrainement et les données de test.
- Je crée un modèle à partir d’un algorithme et de données d’entrainement.
- je crée des prédictions à partir du modèle et des données de test.
- Je compare les prédictions aux vraies données contenues dans le jeu de test.
#
#
#######################################################################################
# Logistic Regression Model
########################################################################################
#Entrainement du Modèle
glmmod <- glm(I(istop3pos==TRUE)~., data=train, family="binomial")
#Predictions
pred.glmmod <- predict(object = glmmod, newdata=test, type="response" )
pred.glmmod.logi <- ifelse(pred.glmmod <0.5, 0,1) #transformation en 0 ou 1 pour matrice de confusion.
(Confusion <- table(pred.glmmod.logi , as.numeric(test$istop3pos))) #matrice de confusion
# En pourcentages:
(ConfusionPerCent <- round(prop.table(Confusion), 4))
#soit un taux de bien classé de 0.5667
ConfusionPerCent[1,1]+ConfusionPerCent[2,2]
#ou bien
mean(pred.glmmod.logi == as.numeric(test$istop3pos)) #0.5666968 mouais pas terrible
#ROC AUC
ROC <- roc(test$istop3pos, pred.glmmod) #
AUC <- auc(ROC) #ici Area under the curve: 0.5876
# Plot the ROC curve
#courbe ROC : Receiver Operating Characteristic (caractéristique de fonctionnement du récepteur)
#teste la qualité du modèle.
plot(ROC, col = "blue")
text(0.5,0.5,paste("AUC = ",format(AUC, digits=5, scientific=FALSE)))
text(0.6, 1, "ROC-AUC Modèle Régression Logistique", col="red")
#importance des variables avec logistic regression model
varImp(glmmod)
La matrice de confusion et le calcul de la moyenne des « bonnes » prédictions permet de déterminer la qualité du modèle :
> (ConfusionPerCent <- round(prop.table(Confusion), 4))
pred.glmmod.logi 0 1
0 0.2280 0.2001
1 0.2540 0.3180
> mean(pred.glmmod.logi == as.numeric(test$istop3pos))
[1] 0.5459414
Le modèle est parfait si la moyenne trouvée est de 1 et il ne fait pas mieux que le hasard si celle-ci est proche de 0.5. ici nous trouvons 0.5459414 ce qui n’est pas terrible.
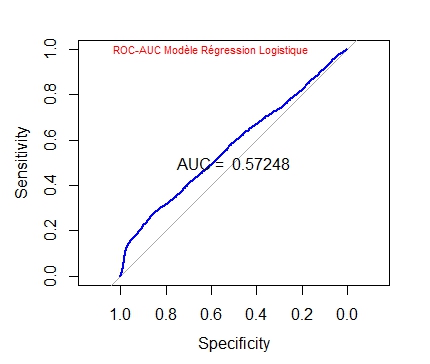
La courbe ROC (Receiver Operating Characteristic = caractéristique de fonctionnement du récepteur) et le calcul de l’AUC (Area Under the curve) permettent aussi d’évaluer le modèle :
AUC = 0.5725 … bon ce n’est pas terrible.
Importance des variables :
> varImp(glmmod)
Overall
kwindomain 4.370518
kwinurl 11.435329
ishttps 22.949776
isSSLEV 31.505129
urlnchar 18.391328
urlslashcount 30.126572
>
Ici, La variable « isSSLEV » indiquant les SSL en Extended Value est celle qui contribue le plus au modèle, la variable « urlsslashcount », qui représente un pseudo « niveau de page interne » dans un site, arrive en second. Toutefois comme le modèle est relativement proche de 0.5 on ne peut pas dire qu’il soit franchement valide.
Modèle Naïve Bayes
Essayons un autre modèle. Le modèle Naïf Bayésien est un classifieur basé sur le théorème de Bayes :
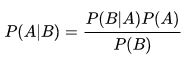
Pour en savoir plus, reportez vous à la notice Wikipedia : Classification Naïve Bayésienne.
#
#
#######################################################################################
# Naive Bayes Model
########################################################################################
#Modèle naive Bayes
nbmod <- naive_bayes(istop3pos~., data = train)
#Predictions
pred.nbmod <- predict(object = nbmod, newdata = test)
#Matrice de confusion
table(pred.nbmod , test$istop3pos)
mean(pred.nbmod == test$istop3pos) #0.5494257 presque équivalent à glm
#ROC et AUC
ROC <- roc(test$istop3pos, as.numeric(pred.nbmod))
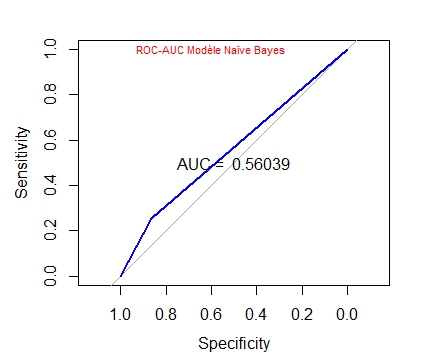
AUC <- auc(ROC) #ici auc Area under the curve: 0.5604 pas terrible < glm
# Plot the ROC curve
plot(ROC, col = "blue")
text(0.5,0.5,paste("AUC = ",format(AUC, digits=5, scientific=FALSE)))
text(0.6, 1, "ROC-AUC Modèle Naïve Bayes", col="red", cex=0.7)
Le Modèle Naïve Bayes ne nous apporte pas grand chose dans notre cas. Il fonctionne même moins bien que le Modèle par Régression Logistique précédent.
Modèle Random Forest avec randomForest
A ma connaissance, il existe 2 bibliothèques pour créer un modèle de « Forêt Aléatoire » dans R : randomForest et ranger. Ici nous utilisons randomForest.
Vous trouverez ici une explication claire de ce que sont les forêts aléatoires, sur le blog de Lise Vaudor. Avec un autre exemple en R.
#
#
#######################################################################################
# RanDom Forest avec la library "randomForest"
########################################################################################
gc() #vider la mémoire (ça mange beaucoup)
#Modèle randomForest
rfmod <- randomForest(as.factor(istop3pos)~., data=train, importance=TRUE)
class(rfmod)
#Predictions
pred.rfmod <- predict(object = rfmod, newdata = test, type="response")
#Matrice de confusion
table(pred.rfmod , test$istop3pos)
mean(pred.rfmod == test$istop3pos) #0.5813223 mieux que glm
#ROC et AUC
ROC <- roc(test$istop3pos, as.numeric(pred.rfmod))
AUC <- auc(ROC) #ici auc AArea under the curve: 0.5843 mieux que glm
# Plot the ROC curve
plot(ROC, col = "blue")
text(0.5,0.5,paste("AUC = ",format(AUC, digits=5, scientific=FALSE)))
text(0.6, 1, "ROC-AUC Modèle Random Forest randomForest", col="red", cex=0.7)
#Importance des variables
rfmod$importance
varImpPlot(rfmod)
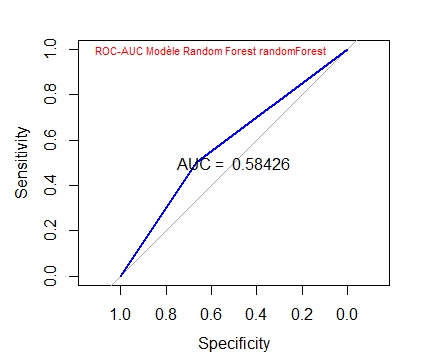
Le modèle est un peu mieux que celui de Régression Linéaire :
Importance des variables :
> rfmod$importance
FALSE TRUE MeanDecreaseAccuracy MeanDecreaseGini
kwindomain 0.0000647654 0.0001903043 0.0001297618 10.13511
kwinurl 0.0046686792 0.0008444315 0.0026880590 67.93826
ishttps 0.0009180974 0.0346657656 0.0183843055 271.63407
isSSLEV 0.0099572023 0.0394399284 0.0252218318 353.54207
urlnchar 0.0088439978 0.0308398632 0.0202375132 659.55647
urlslashcount 0.0311110665 0.0321996717 0.0316769276 1101.59703
>
Ce n’est pas très lisible mais il faut lire les nombres à droite correspondants à la valeur de « MeanDecreaseGini ». Dans ce cas la variable la plus importante est « urlslashcount ».
Modèle Random Forest avec ranger
ranger est une autre bibliothèque permettant de créer un modèle Random Forest.
#
#
#######################################################################################
# Random Forest avec la library "ranger"
########################################################################################
gc() #vider la mémoire (ça mange beaucoup)
#Entrainement du Modèle
rangermod <- ranger(as.factor(istop3pos)~., data=train, importance="impurity")
#Prédictions
pred.rangermod <- predict(object = rangermod, data = test, type="response")$predictions
#Matrice de confusion
table(pred.rangermod , test$istop3pos)
mean(pred.rangermod == test$istop3pos) #0.5830645 ~ randomForest !!!!!
#ROC et AUC
ROC <- roc(test$istop3pos, as.numeric(pred.rangermod ))
AUC <- auc(ROC) #ici auc Area under the curve: 0.5867 ~ randomForest
# Plot the ROC curve
plot(ROC, col = "blue")
text(0.5,0.5,paste("AUC = ",format(AUC, digits=5, scientific=FALSE)))
text(0.6, 1, "ROC-AUC Modèle Random Forest ranger", col="red", cex=0.7)
#Importance des variables
rangermod$variable.importance
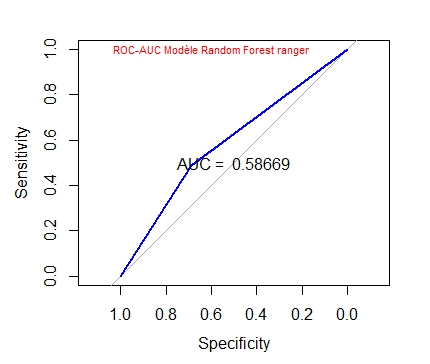
Le modèle créé par ranger est quasi le même que celui créé par randomForest :
Modèle XGBoost
XGBoost pour eXtreme Gradient Boosting. XGBoost est un modèle assez récent (2014) basé sur un algorithme de gradient boosting. Cet outil est devenu rapidement très populaire chez les Data Scientists car il donne des résultats souvent meilleurs que des outils plus anciens comme par exemple le Random Forest.
Pour ceux qui souhaitent approfondir le sujet vous trouverez ici un cours de l’université de Toulouse qui discute des différents modèles et aborde le modèle Gradient Boosting (un peu ardu !).
Pour les autres, on se contentera d’utiliser la bibliothèque 🙂 :
#
#
#######################################################################################
# XGBoost sur istop3pos
########################################################################################
# Variable à expliquer
(outcome <- "istop3pos")
# Variables explicatives
(vars <- c("kwindomain", "kwinurl", "ishttps", "isSSLEV", "urlnchar", "urlslashcount"))
#Traitements préalables des données pour être utilisées par XGBoost
# Création d'un "plan de traitement" à partir de train (données d'entrainement)
# "one hot encoding"
treatplan <- designTreatmentsZ(train, vars, verbose = FALSE)
#str(treatplan)
# On récupère les variables "clean" et "lev" du scoreFrame : treatplan$scoreframe
(newvars <- treatplan %>%
use_series(scoreFrame) %>%
filter(code %in% c("clean","lev")) %>% # get the rows you care about
use_series(varName)) # get the varName column
# Preparation des données d'entrainement à partir du plan de traitement créé précédemment
train.treat <- prepare(treatmentplan = treatplan, dframe = train , varRestriction = newvars)
# Preparation des données de test à partir du plan de traitement créé précédemment
test.treat <- prepare(treatmentplan = treatplan, dframe = test, varRestriction = newvars)
# on commence par faire tourner xgb.cv pour déterminer le nombre d'arbres optimal.
cv <- xgb.cv(data = as.matrix(train.treat),
label = train$istop3pos,
nrounds = 100,
nfold = 5,
objective = "binary:logistic",
eta = 0.3,
max_depth = 6,
early_stopping_rounds = 10,
verbose = 1 # silent
)
#str(cv)
#pour regression linéaire objective = "reg:linear",
#pour binaire objective = "binary:logistic",
# Get the evaluation log
elog <- cv$evaluation_log
str(elog)
# Determination du nombre d'arbres qui minimise l'erreur sur le jeu de train et le jeu de test
(Twotreesvalue <- elog %>%
summarize(ntrees.train = which.min(train_error_mean), # find the index of min(train_rmse_mean)
ntrees.test = which.min(test_error_mean)) ) # find the index of min(test_rmse_mean)
#on prend le plus petit des 2
ntrees = min(Twotreesvalue$ntrees.train, Twotreesvalue$ntrees.test)
# The number of trees to use, as determined by xgb.cv
ntrees
# Run xgboost
xgbmod <- xgboost(data = as.matrix(train.treat), # training data as matrix
label = train$istop3pos, # column of outcomes
nrounds = ntrees, # number of trees to build
objective = "binary:logistic", # objective
eta = 0.3,
depth = 6,
verbose = 1 # affichage ou non
)
#Predictions
pred.xgbmod <-predict(xgbmod, as.matrix(test.treat))
#Matrice de Confusion
table(round(pred.xgbmod) , test$istop3pos)
mean(round(pred.xgbmod) == test$istop3pos) ###0.609369 mieux que randomForest, ranger et glm
#ROC et AUC
ROC <- roc(test$istop3pos, pred.xgbmod)
AUC <- auc(ROC) #ici auc Area under the curve: 0.661 mieux mieux que randomForest, ranger et glm !
# Plot the ROC curve
plot(ROC, col = "blue")
text(0.5,0.5,paste("AUC = ",format(AUC, digits=5, scientific=FALSE)))
text(0.6, 1, "ROC-AUC Modèle XGBoost", col="red", cex=0.7)
#importance #c'est le gain qui nous intéresse !
(importance <- xgb.importance(feature_names = colnames(x = train.treat), model = xgbmod))
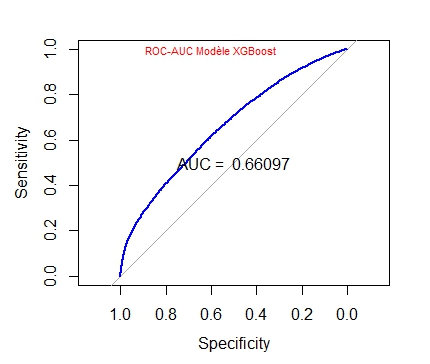
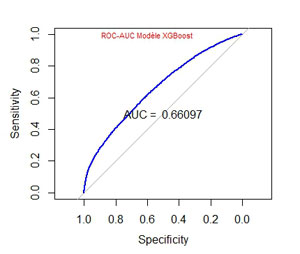
Le modèle XGBoost donne des résultats meilleurs que les modèles précédents avec une AUC de 0.661
La variable la plus importante est ici le nombre de caractères dans l’url « urlnchar_clean » (regardez l’indicateur « Gain ») :
> (importance <- xgb.importance(feature_names = colnames(x = train.treat), model = xgbmod))
Feature Gain Cover Frequency
1: urlnchar_clean 0.410036436 0.73081319 0.581213971
2: urlslashcount_clean 0.366750031 0.12605521 0.216344524
3: ishttps_clean 0.118527197 0.04053112 0.090200068
4: isSSLEV_clean 0.065902531 0.03964566 0.045100034
5: kwinurl_clean 0.035875160 0.03383810 0.061037640
6: kwindomain_clean 0.002908645 0.02911672 0.006103764
>
Conclusion
A ce stade nous n’avons malheureusement pas trouvé un modèle suffisamment valide permettant de trouver des facteurs SEO intéressants.
Dans l’article suivant de cette série, nous enrichissons les données avec des données techniques des pages.
N’hésitez pas à faire vos remarques et suggestions dans les commentaires.
Merci de votre attention,
Pierre