Partager la publication "Nettoyage du Spam dans Google Analytics avec Python"
Précédemment nous avions vu comment nettoyer le spam avec les segments directement dans Google Analytics et comment nettoyer ce spam avec R.
Cette fois nous allons voir comment le faire avec Python. Pour cela nous reprendrons la méthode d’importation des données de l’API de Google Analytics avec Python, que nous avions décrite précédemment. Démarrons tout de suite le code source.
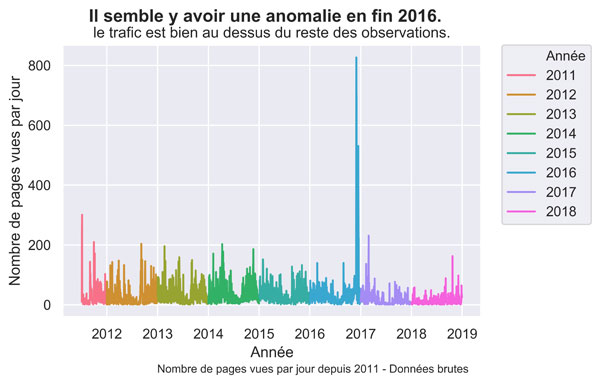
Dans l’article précédent nous avions notamment importé les données de trafic de Networking Morbihan sur 7 ans 1/2 . Les données brutes présentaient des anomalies que nous allons nettoyer ici.
Code Source
N’hésitez pas à copier/coller les codes sources suivants. Comme nous vous l’indiquions précédemment nous faisons tourner le programme dans l’environnement de développement Spyder.
Attention le code source démarre ici à la récupération des données utiles. Pour voir comment se connecter à Google Analytics API reportez vous à notre article précédent sur l’importation.
Récupération des données pour nettoyage :
Afin de pouvoir filtrer le spam il sera nécessaire de récupérer des dimensions : hostname, browser, fullReferrer, sourceMedium, language, landingPagePath, pagePath dans Google Analytics.
##########################################################################
# RECUPERATION DES DONNEES POUR FILTRAGE
##########################################################################
#Pour mémoire Dimensions & Metrics Explorer
#https://developers.google.com/analytics/devguides/reporting/core/dimsmets
#Attention le nombre de dimensions est limité à 9 et de Metrics à 10.
def get_gaPVAllYears(analytics):
# Use the Analytics Service Object to query the Analytics Reporting API V4.
return analytics.reports().batchGet(
body={
'reportRequests': [
{
'viewId': VIEW_ID,
'pageSize': 100000, #pour dépasser la limite de 1000
'dateRanges': [{'startDate': "2011-07-01", 'endDate': "2018-12-31"}],
'metrics': [{'expression': 'ga:pageviews'}],
'dimensions': [{'name': 'ga:date'},
{'name': 'ga:hostname'},
{'name': 'ga:browser'},
{'name': 'ga:fullReferrer'},
{'name': 'ga:sourceMedium'},
{'name': 'ga:language'},
{'name': 'ga:landingPagePath'},
{'name': 'ga:pagePath'},
{'name': 'ga:keyword'}],
}]
}
).execute()
response = get_gaPVAllYears(analytics)
gaPVAllYears = dataframe_response(response)
gaPVAllYears.dtypes
gaPVAllYears.count() #51717 enregistrements
Préparation des données :
Dans cette partie nous allons préparer les données pour être exploitables par la suite. Nous allons notamment créer une observation par page vue..
###############################################################################
#Etape 1 préparation des données
#changement des noms de variables pour manipuler les colonnes.
gaPVAllYears = gaPVAllYears.rename(columns={'ga:browser': 'browser',
'ga:date': 'date',
'ga:fullReferrer': 'fullReferrer',
'ga:hostname': 'hostname',
'ga:keyword': 'keyword',
'ga:landingPagePath': 'landingPagePath',
'ga:language': 'language',
'ga:pagePath': 'pagePath',
'ga:pageviews': 'pageviews',
'ga:sourceMedium': 'sourceMedium'})
#creation de la variable Année à partir de ga:date
gaPVAllYears['Année'] = gaPVAllYears['date'].astype(str).str[:4]
#separation de la variable sourceMedium en source et medium
gaPVAllYears['source'] = gaPVAllYears['sourceMedium'].str.split("/",1, expand = True)[0]
gaPVAllYears['medium'] = gaPVAllYears['sourceMedium'].str.split("/",1, expand = True)[1]
#transformation date string en datetime
gaPVAllYears.date = pd.to_datetime(gaPVAllYears.date, format="%Y%m%d")
#replication des lignes en fonction de la valeur de pageviews (dans R : uncount)
#i.e. : une ligne par page vue
gaPVAllYears = gaPVAllYears.reindex(gaPVAllYears.index.repeat(gaPVAllYears.pageviews))
gaPVAllYears = gaPVAllYears.reset_index(drop=True) #reindexation
gaPVAllYears.pageviews = 1 #tous les pageviews à 1 maintenant
#### Verifs
gaPVAllYears[['date', 'pageviews']]
gaPVAllYears.dtypes
gaPVAllYears.count() #82559 enregistrements !!!! au 31/12/2018 comme dans R
###############################################################################
# Sauvegarde en csv pour éviter de faire des appels à GA
gaPVAllYears.to_csv("gaPVAllYears.csv", sep=";", index=False) #séparateur ;
###############################################################################
Nettoyage des langues suspectes :
Remarque préalable : pour ceux qui n’ont pas réussi à récupérer leurs données avec l’API nous vous proposons de récupérer nos données brutes en .zip ici : https://github.com/Anakeyn/CleanSpamGAwPython/blob/master/gaPVAllYears.zip, afin de tester le reste du programme.
Dans cette partie nous allons vérifier que les langues sont bien au format ISO « langue-pays » : xxx-xxx, par exemple : fr-FR, fr-BE, es ..
#Relecture ############
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
gaPVAllYears = pd.read_csv("gaPVAllYears.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
gaPVAllYears.dtypes
gaPVAllYears.count() #82559 enregistrements
gaPVAllYears.head(20)
##############################################################################
##########################################################################
#Nettoyage des langues suspectes.
##########################################################################
pattern = "^[a-zA-Z]{2,3}([-/][a-zA-Z]{2,3})?$"
indexGoodlang = gaPVAllYears[(gaPVAllYears.language.str.contains(pat=pattern,regex=True)==True)].index
gaPVAllYearsCleanLanguage=gaPVAllYears.iloc[indexGoodlang]
gaPVAllYearsCleanLanguage.reset_index(inplace=True, drop=True) #reindexation.
gaPVAllYearsCleanLanguage.dtypes
gaPVAllYearsCleanLanguage.count() #76733
gaPVAllYearsCleanLanguage[['date', 'pageviews']]
#creation de la dataframe daily_data par jour
dfDatePV = gaPVAllYearsCleanLanguage[['date', 'pageviews']].copy() #nouveau dataframe avec que la date et le nombre de pages vues
daily_data = dfDatePV.groupby(dfDatePV['date']).count() #
#dans l'opération précédente la date est partie dans l'index et pageviews a pris le décompte
daily_data['date'] = daily_data.index #
daily_data['cnt_ma30'] = daily_data['pageviews'].rolling(window=30).mean()
daily_data['Année'] = daily_data['date'].astype(str).str[:4]
#Graphique pages vues par jour
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='pageviews', hue='Année', data= daily_data,
palette=sns.color_palette("husl",n_colors=8))
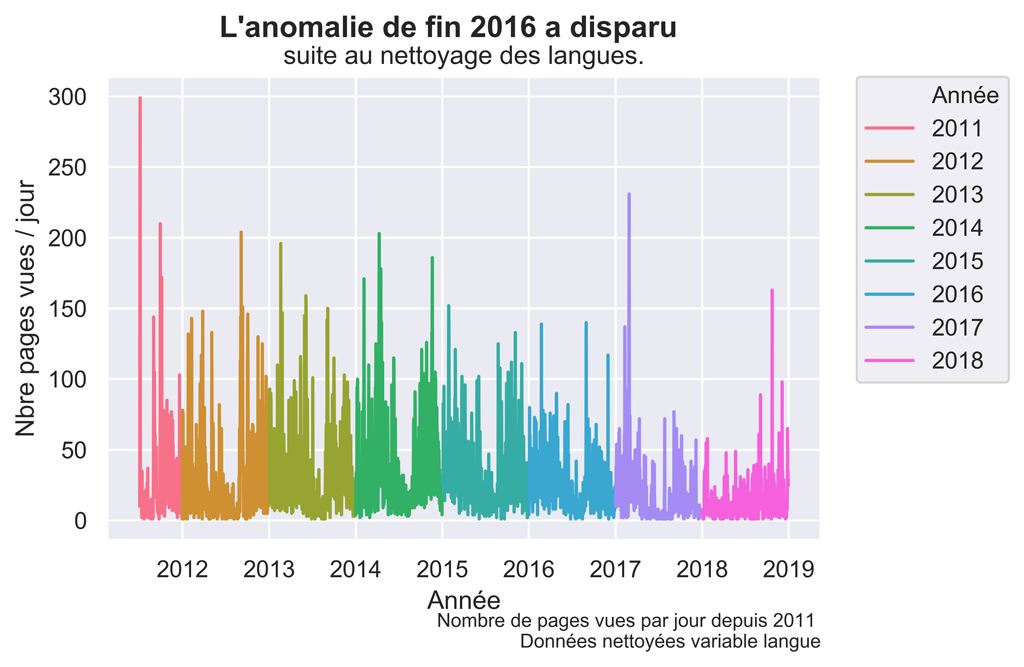
fig.suptitle("L'anomalie de fin 2016 a disparu ", fontsize=14, fontweight='bold')
ax.set(xlabel='Année', ylabel='Nbre pages vues / jour',
title='suite au nettoyage des langues.')
fig.text(.9,-.05,"Nombre de pages vues par jour depuis 2011 \n Données nettoyées variable langue",
fontsize=9, ha="right")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#plt.show()
fig.savefig("PV-s2011-Clean-Lang.png", bbox_inches="tight", dpi=600)
#Graphique Moyenne Mobile 30 jours.
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='cnt_ma30', hue='Année', data= daily_data,
palette=sns.color_palette("husl",n_colors=8))
fig.suptitle("L'anomalie de fin 2016 a disparu ", fontsize=14, fontweight='bold')
ax.set(xlabel='Année', ylabel='Nbre pages vues / jour en moyenne mobile',
title='suite au nettoyage des langues.')
fig.text(.9,-.05,"Nombre de pages vues par jour depuis 2011 en moy. mob. 30 j. \n Données nettoyées variable langue",
fontsize=9, ha="right")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#plt.show()
fig.savefig("PV-s2011-Clean-Lang-mm30.png", bbox_inches="tight", dpi=600)
###############################################################################
# Sauvegarde en csv
gaPVAllYearsCleanLanguage.to_csv("gaPVAllYearsCL.csv", sep=";", index=False) #séparateur ;
###############################################################################
Graphique Pages VUES après nettoyage des langues suspectes
Nettoyage des Ghostnames :
Les Ghostnames sont des noms de domaine qui hébergent votre code de suivi de Google Analytics (sans votre consentement en général :-(). Ici nous n’allons conserver que les sites qui sont légitimes comme monsite.com ou encore des sites de cache comme celui de Google, par exemple :
webcache.googleusercontent.com.
On enlève aussi les sous-domaines que l’on ne veut pas garder, ici pour nous loc.networking-morbihan.com .
#Relecture ############
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
gaPVAllYearsCleanLanguage = pd.read_csv("gaPVAllYearsCL.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
gaPVAllYearsCleanLanguage.dtypes
gaPVAllYearsCleanLanguage.count() #76733 enregistrements
gaPVAllYearsCleanLanguage.head(20)
##############################################################################
##########################################################################
#nettoyage des hostnames.
##########################################################################
#Pour faciliter la lecture on va créer une liste de patterns
#on garde ceux qui nous intéressent
patternGoodHostname = ["networking-morbihan\.com", "translate\.googleusercontent\.com",
"webcache\.googleusercontent\.com",
"networking-morbihan\.com\.googleweblight\.com",
"web\.archive\.org"]
#on regroupe en une seule pattern
pattern = '|'.join(patternGoodHostname)
indexGoodHostname = gaPVAllYearsCleanLanguage[(gaPVAllYearsCleanLanguage.hostname.str.contains(pat=pattern,regex=True)==True)].index
gaPVAllYearsCleanHost1 = gaPVAllYearsCleanLanguage.iloc[indexGoodHostname]
gaPVAllYearsCleanHost1.reset_index(inplace=True, drop=True) #reindexation.
gaPVAllYearsCleanHost1.dtypes
gaPVAllYearsCleanHost1.count() #76170
#on vire loc.networking-morbihan.com qui restait
patternBadHostname = "loc\.networking-morbihan\.com"
#on garde ceux qui ne correspondent pas à la pattern attention ici ==False
indexGoodHostname = gaPVAllYearsCleanHost1[(gaPVAllYearsCleanHost1.hostname.str.contains(pat=patternBadHostname,regex=True)==False)].index
gaPVAllYearsCleanHost = gaPVAllYearsCleanHost1.iloc[indexGoodHostname]
gaPVAllYearsCleanHost.reset_index(inplace=True, drop=True) #reindexation.
gaPVAllYearsCleanHost.dtypes
gaPVAllYearsCleanHost.count() #76159
#creation de la dataframe daily_data par jour
dfDatePV = gaPVAllYearsCleanHost[['date', 'pageviews']].copy() #nouveau dataframe avec que la date et le nombre de pages vues
daily_data = dfDatePV.groupby(dfDatePV['date']).count() #
#dans l'opération précédente la date est partie dans l'index
daily_data['date'] = daily_data.index #
daily_data['cnt_ma30'] = daily_data['pageviews'].rolling(window=30).mean()
daily_data['Année'] = daily_data['date'].astype(str).str[:4]
#Graphique pages vues par jour
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='pageviews', hue='Année', data= daily_data,
palette=sns.color_palette("husl",n_colors=8))
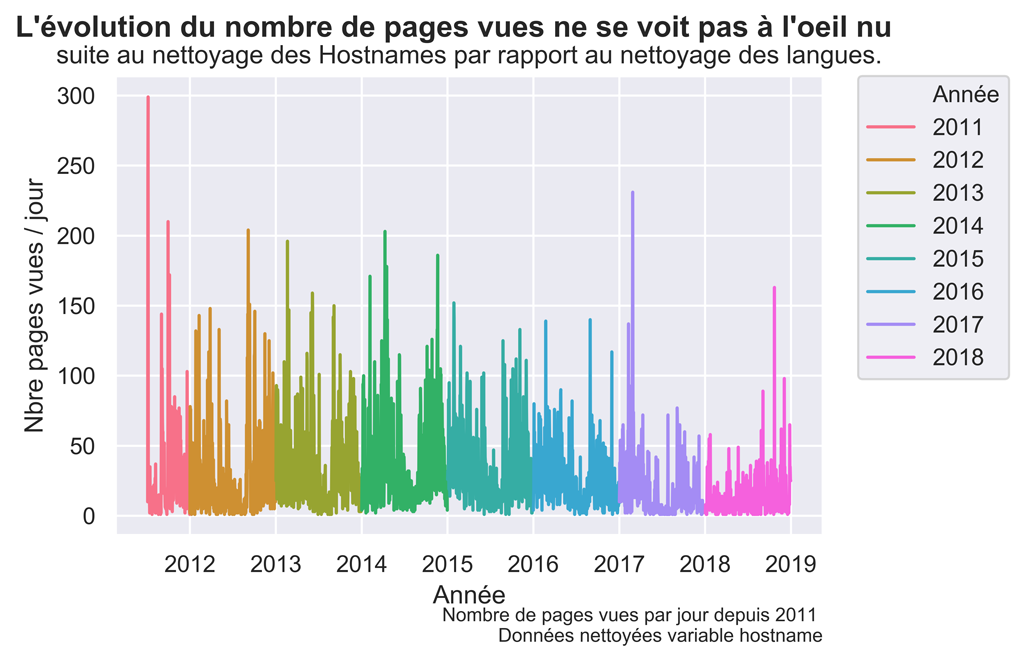
fig.suptitle("L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ", fontsize=14, fontweight='bold')
ax.set(xlabel='Année', ylabel='Nbre pages vues / jour',
title='suite au nettoyage des Hostnames par rapport au nettoyage des langues.')
fig.text(.9,-.05,"Nombre de pages vues par jour depuis 2011 \n Données nettoyées variable hostname",
fontsize=9, ha="right")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#plt.show()
fig.savefig("PV-s2011-Clean-Host.png", bbox_inches="tight", dpi=600)
#Graphique Moyenne Mobile 30 jours.
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='cnt_ma30', hue='Année', data= daily_data,
palette=sns.color_palette("husl",n_colors=8))
fig.suptitle("L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ", fontsize=14, fontweight='bold')
ax.set(xlabel='Année', ylabel='Nbre pages vues / jour en moyenne mobile',
title='suite au nettoyage des Hostnames par rapport au nettoyage des langues.')
fig.text(.9,-.05,"Nombre de pages vues par jour depuis 2011 en moy. mob. 30 j. \n Données nettoyées variable hostname",
fontsize=9, ha="right")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#plt.show()
fig.savefig("PV-s2011-Clean-Host-mm30.png", bbox_inches="tight", dpi=600)
###############################################################################
# Sauvegarde en csv
gaPVAllYearsCleanHost.to_csv("gaPVAllYearsCH.csv", sep=";", index=False) #séparateur ;
###############################################################################
Graphique Pages VUES après nettoyage des GHOSTNAMES
Nettoyage des browsers suspects
Avant de virer les browsers suspects il est nécessaire de vérifier à la main ce que vous avez dans la variable browser. Cela peut changer par rapport à nous .
#Relecture ############
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
gaPVAllYearsCleanHost = pd.read_csv("gaPVAllYearsCH.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
gaPVAllYearsCleanHost.dtypes
gaPVAllYearsCleanHost.count() #76159 enregistrements
gaPVAllYearsCleanHost.head(20)
##############################################################################
##########################################################################
#nettoyage des browser suspects - peut contenir des robots crawlers
##########################################################################
#voyons ce qu'il y a dedans
gaPVAllYearsCleanHost['browser'].value_counts()
#on vire les "curiosités" et les bots
patternBadBrowser = ["not set","Google\\.com", "en-us",
"GOOG", "PagePeeker\\.com",
"bot"]
#on regroupe en une seule pattern
pattern = '|'.join(patternBadBrowser)
#on garde ceux qui ne correspondent pas à la pattern attention ici ==False
indexGoodBrowser = gaPVAllYearsCleanHost[(gaPVAllYearsCleanHost.browser.str.contains(pat=pattern,regex=True)==False)].index
gaPVAllYearsCleanBrowser = gaPVAllYearsCleanHost.iloc[indexGoodBrowser]
gaPVAllYearsCleanBrowser.reset_index(inplace=True, drop=True) #reindexation.
gaPVAllYearsCleanBrowser.dtypes
gaPVAllYearsCleanBrowser.count() #76126
#creation de la dataframe daily_data par jour
dfDatePV = gaPVAllYearsCleanBrowser[['date', 'pageviews']].copy() #nouveau dataframe avec que la date et le nombre de pages vues
daily_data = dfDatePV.groupby(dfDatePV['date']).count() #
#dans l'opération précédente la date est partie dans l'index
daily_data['date'] = daily_data.index #
daily_data['cnt_ma30'] = daily_data['pageviews'].rolling(window=30).mean()
daily_data['Année'] = daily_data['date'].astype(str).str[:4]
#Graphique pages vues par jour
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='pageviews', hue='Année', data= daily_data,
palette=sns.color_palette("husl",n_colors=8))
fig.suptitle("L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ", fontsize=14, fontweight='bold')
ax.set(xlabel='Année', ylabel='Nbre pages vues / jour',
title='suite au nettoyage des browsers suspects par rapport aux nettoyages précédents.')
fig.text(.9,-.05,"Nombre de pages vues par jour depuis 2011 \n Données net. variable browser",
fontsize=9, ha="right")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#plt.show()
fig.savefig("PV-s2011-Clean-Browser.png", bbox_inches="tight", dpi=600)
#Graphique Moyenne Mobile 30 jours.
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='cnt_ma30', hue='Année', data= daily_data,
palette=sns.color_palette("husl",n_colors=8))
fig.suptitle("L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ", fontsize=14, fontweight='bold')
ax.set(xlabel='Année', ylabel='Nbre pages vues / jour en moyenne mobile',
title='suite au nettoyage des browsers suspects par rapport aux nettoyages précédents.')
fig.text(.9,-.05,"Nombre de pages vues par jour depuis 2011 en moy. mob. 30 j. \n Données net. variable browser",
fontsize=9, ha="right")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#plt.show()
fig.savefig("PV-s2011-Clean-Host-mm30.png", bbox_inches="tight", dpi=600)
###############################################################################
# Sauvegarde en csv
gaPVAllYearsCleanBrowser.to_csv("gaPVAllYearsCB.csv", sep=";", index=False) #séparateur ;
###############################################################################
Graphique Pages VUES après nettoyage de la variable Browser
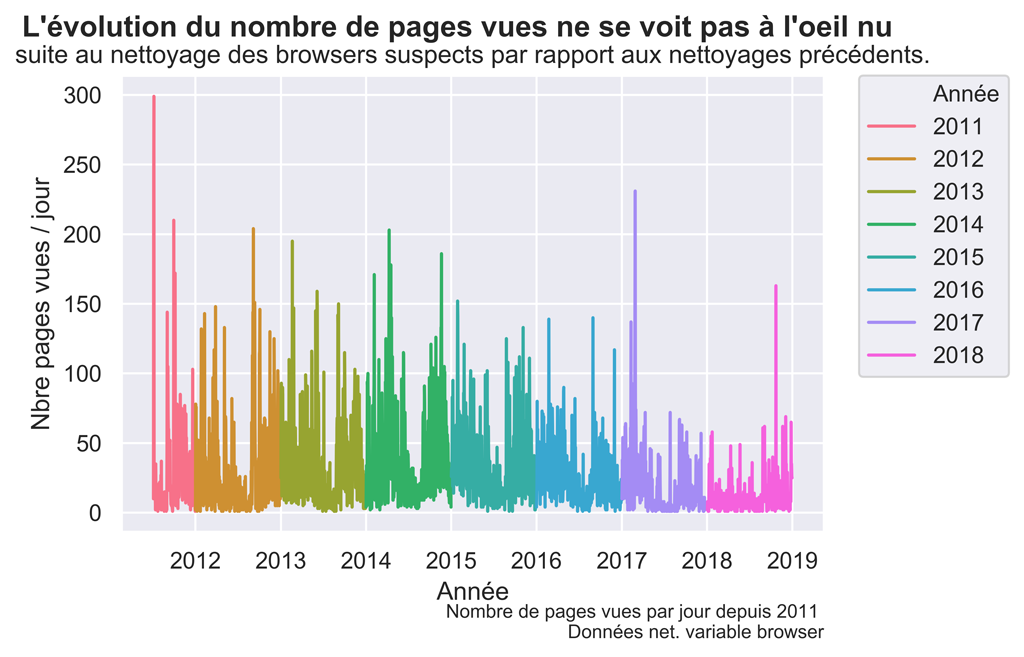
Nettoyage des Crawlers Spammers et sources de trafic non désirées dans la variable source.
Afin de réaliser cette opération nous aurons besoin de récupérer un fichier de sites blacklistés. Nous en avons créé un que vous pouvez récupérer dans cette archive sur notre Github. Toutefois il est possible que vous soyez obligé de le compléter au vu de ce que vous avez dans vos données.
#Relecture ############
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
gaPVAllYearsCleanBrowser = pd.read_csv("gaPVAllYearsCB.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
gaPVAllYearsCleanBrowser.dtypes
gaPVAllYearsCleanBrowser.count() #76126 enregistrements
gaPVAllYearsCleanBrowser.head(20)
##############################################################################
##########################################################################
#nettoyage des Crawlers Spammers et autres sources de trafic non désirées
#dans source
##########################################################################
gaPVAllYearsCleanBrowser['source'].value_counts()
gaPVAllYearsCleanSource = gaPVAllYearsCleanBrowser.copy() #=on fait une copie ici
#la liste des sites et mots clés non désirés est dans un fichier que
#nous avons créé.
dfBlacklistSites = pd.read_csv("blacklist-source-sites.csv", sep=";")
patternBadSource = dfBlacklistSites["blacksites"].tolist()
#ça plante si on le fait en une fois, on va devoir diviser en paquets
len(patternBadSource)
step = 500
steps = list(range(0, len(patternBadSource), step))
j=0
for i in steps:
if (i+step < len(patternBadSource) ) :
imax=i+step
else :
imax = len(patternBadSource)
print("i=",i)
print("imax=",imax)
patternBadSourcePack = '|'.join(patternBadSource[i:imax])
indexGoodSource = gaPVAllYearsCleanSource[(gaPVAllYearsCleanSource.source.str.contains(pat=patternBadSourcePack,regex=True)==False)].index
print("indexGoodSource size =", indexGoodSource.size)
gaPVAllYearsCleanSource = gaPVAllYearsCleanSource.iloc[indexGoodSource]
gaPVAllYearsCleanSource.reset_index(inplace=True, drop=True) #on reindexe
gaPVAllYearsCleanSource.reset_index(inplace=True, drop=True) #reindexation. pas sur que cela serve beaucoup ici
###################!!!!!!!!!!!!!!!!!!!!!!!!!
gaPVAllYearsCleanSource.dtypes
gaPVAllYearsCleanSource.count() #74275 #même chose qu'avec R !!!!!! 74275
#pour vérifier ce que l'on a dans la variable
gaPVAllYearsCleanSource['source'].value_counts()
# Sauvegarde en csv
gaPVAllYearsCleanSource['source'].value_counts().to_csv("gaPVAllYearsCSSC.csv", sep=";") #séparateur ;
#########
#creation de la dataframe daily_data par jour
dfDatePV = gaPVAllYearsCleanSource[['date', 'pageviews']].copy() #nouveau dataframe avec que la date et le nombre de pages vues
daily_data = dfDatePV.groupby(dfDatePV['date']).count() #
#dans l'opération précédente la date est partie dans l'index
daily_data['date'] = daily_data.index #
daily_data['cnt_ma30'] = daily_data['pageviews'].rolling(window=30).mean()
daily_data['Année'] = daily_data['date'].astype(str).str[:4]
#Graphique pages vues par jour
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='pageviews', hue='Année', data= daily_data,
palette=sns.color_palette("husl",n_colors=8))
fig.suptitle("L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ", fontsize=14, fontweight='bold')
ax.set(xlabel='Année', ylabel='Nbre pages vues / jour',
title='suite au nettoyage des referrers suspects par rapport aux nettoyages précédents.')
fig.text(.9,-.05,"Nombre de pages vues par jour depuis 2011 \n Données net. variable source",
fontsize=9, ha="right")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#plt.show()
fig.savefig("PV-s2011-Clean-Source.png", bbox_inches="tight", dpi=600)
#Graphique Moyenne Mobile 30 jours.
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='cnt_ma30', hue='Année', data= daily_data,
palette=sns.color_palette("husl",n_colors=8))
fig.suptitle("L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ", fontsize=14, fontweight='bold')
ax.set(xlabel='Année', ylabel='Nbre pages vues / jour en moyenne mobile',
title='suite au nettoyage des referrers suspects par rapport aux nettoyages précédents.')
fig.text(.9,-.05,"Nombre de pages vues par jour depuis 2011 en moy. mob. 30 j. \n Données net. variable source",
fontsize=9, ha="right")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#plt.show()
fig.savefig("PV-s2011-Clean-Source-mm30.png", bbox_inches="tight", dpi=600)
###############################################################################
# Sauvegarde en csv
gaPVAllYearsCleanSource.to_csv("gaPVAllYearsCS.csv", sep=";", index=False) #séparateur ;
###############################################################################
Graphique Pages VUES après nettoyage de la variable SOURCE
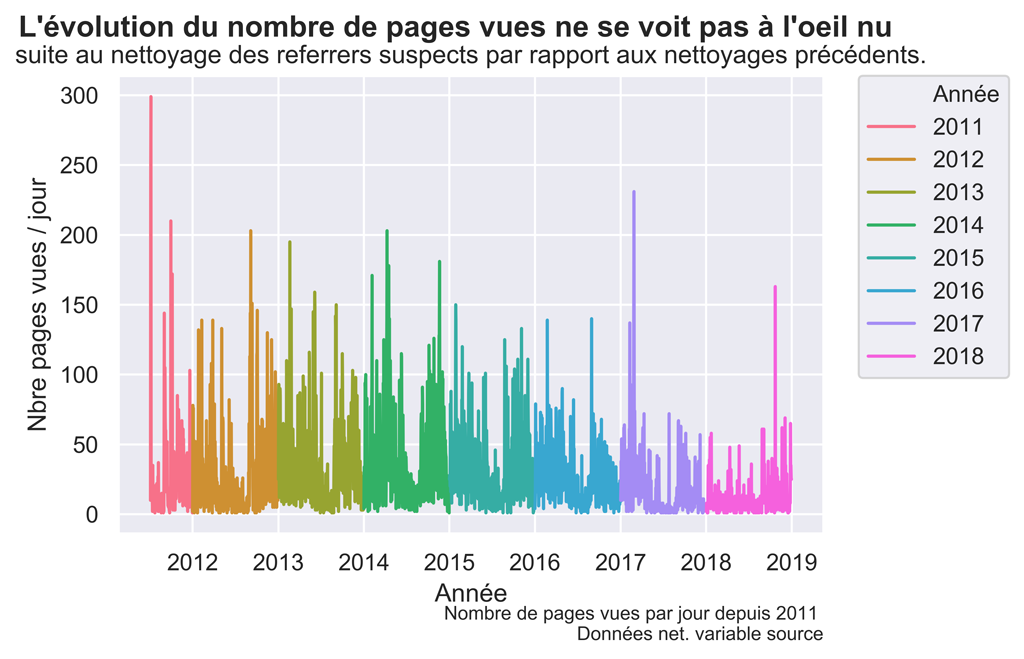
Nettoyage des fausses pages référentes dans la variable fullReferrer
Il s’agit ici de fausses pages référentes mais sur des sites légitimes. Nous avons aussi créé un fichier blacklist-fullReferrer-Page.csv que vous pouvez récupérer sur notre Github.
#Relecture ############
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
gaPVAllYearsCleanSource = pd.read_csv("gaPVAllYearsCS.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
gaPVAllYearsCleanSource.dtypes
gaPVAllYearsCleanSource.count() #74275 enregistrements
gaPVAllYearsCleanSource.head(20)
##############################################################################
##########################################################################
#nettoyage des fausses pages référentes dans fullReferrer
##########################################################################
gaPVAllYearsCleanFullReferrer = gaPVAllYearsCleanSource.copy() #=on fait une copie ici
#la liste des pages non désirées est dans un fichier que
#nous avons créé.
dfBlacklistFullReferrers = pd.read_csv("blacklist-fullRefferer-Page.csv", sep=";")
patternBadFullReferrer = dfBlacklistFullReferrers["Blackpages"].tolist()
pattern = '|'.join(patternBadFullReferrer)
indexGoodFullReferrer = gaPVAllYearsCleanFullReferrer[(gaPVAllYearsCleanFullReferrer.fullReferrer.str.contains(pat=pattern,regex=True)==False)].index
gaPVAllYearsCleanFullReferrer = gaPVAllYearsCleanFullReferrer.iloc[indexGoodFullReferrer]
gaPVAllYearsCleanFullReferrer.reset_index(inplace=True, drop=True) #on reindexe
gaPVAllYearsCleanFullReferrer.count() #73829 #même chose qu'avec R !!!!!!
#creation de la dataframe daily_data par jour
dfDatePV = gaPVAllYearsCleanFullReferrer[['date', 'pageviews']].copy() #nouveau dataframe avec que la date et le nombre de pages vues
daily_data = dfDatePV.groupby(dfDatePV['date']).count() #
#dans l'opération précédente la date est partie dans l'index
daily_data['date'] = daily_data.index #
daily_data['cnt_ma30'] = daily_data['pageviews'].rolling(window=30).mean()
daily_data['Année'] = daily_data['date'].astype(str).str[:4]
#Graphique pages vues par jour
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='pageviews', hue='Année', data= daily_data,
palette=sns.color_palette("husl",n_colors=8))
fig.suptitle("L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ", fontsize=14, fontweight='bold')
ax.set(xlabel='Année', ylabel='Nbre pages vues / jour',
title='suite au nettoyage des pages référentes suspectes par rapport aux nettoyages précédents.')
fig.text(.9,-.05,"Nombre de pages vues par jour depuis 2011 \n Données net. variable fullReferrer",
fontsize=9, ha="right")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#plt.show()
fig.savefig("PV-s2011-Clean-FullReferrer.png", bbox_inches="tight", dpi=600)
#Graphique Moyenne Mobile 30 jours.
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='cnt_ma30', hue='Année', data= daily_data,
palette=sns.color_palette("husl",n_colors=8))
fig.suptitle("L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ", fontsize=14, fontweight='bold')
ax.set(xlabel='Année', ylabel='Nbre pages vues / jour en moyenne mobile',
title='suite au nettoyage des pages référentes suspectes par rapport aux nettoyages précédents.')
fig.text(.9,-.05,"Nombre de pages vues par jour depuis 2011 en moy. mob. 30 j. \n Données net. variable fullReferrer",
fontsize=9, ha="right")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#plt.show()
fig.savefig("PV-s2011-Clean-FullReferrer-mm30.png", bbox_inches="tight", dpi=600)
###############################################################################
# Sauvegarde en csv
gaPVAllYearsCleanFullReferrer.to_csv("gaPVAllYearsCFR.csv", sep=";", index=False) #séparateur ;
###############################################################################
Graphique Pages VUES après nettoyage de la variable fullReFERRER
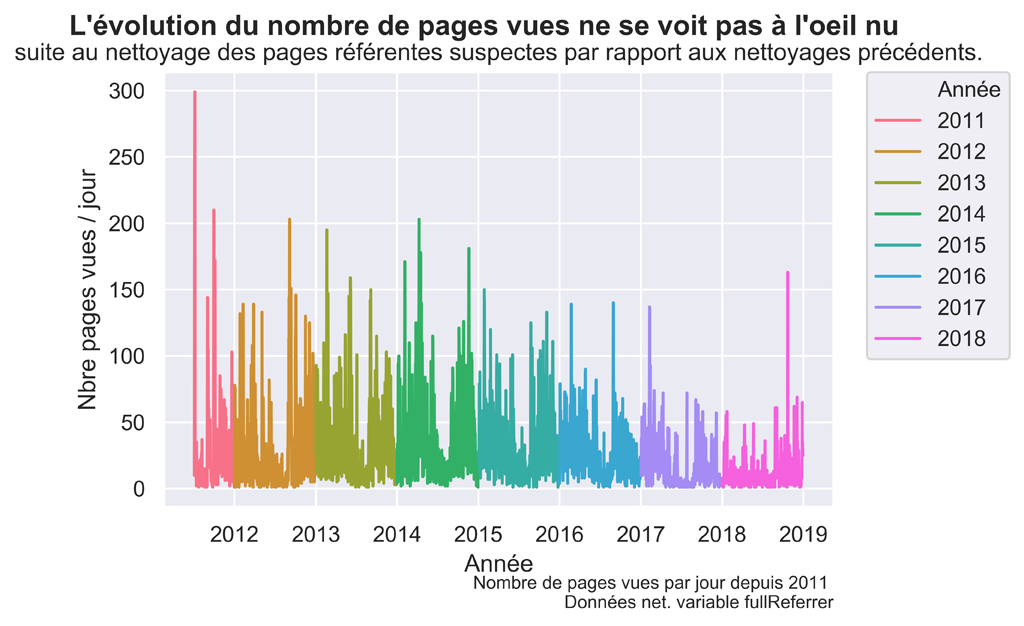
Nettoyage des pages d’administration
Il s’agit ici des pages d’administration de votre site Web et qui dépendent de votre CMS. Donc vous serez obligé de l’adapter. Pour nous il s’agit de WordPress.
#Relecture ############
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
gaPVAllYearsFullReferrer = pd.read_csv("gaPVAllYearsCFR.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
gaPVAllYearsCleanFullReferrer.dtypes
gaPVAllYearsCleanFullReferrer.count() #73829 enregistrements
gaPVAllYearsCleanFullReferrer.head(20)
##############################################################################
##########################################################################
#nettoyage des pages d'administration dans pagePath
##########################################################################
gaPVAllYearsCleanPagePath = gaPVAllYearsCleanFullReferrer.copy() #=on fait une copie ici
#on vire les accès à l'administration et les pages vues depuis l'administration
patternBadPagePath = ["/wp-login\\.php", "/wp-admin/", "/cron/", "/?p=\\d"]
pattern = '|'.join(patternBadPagePath)
indexGoodPagePath = gaPVAllYearsCleanPagePath[(gaPVAllYearsCleanPagePath.pagePath.str.contains(pat=pattern,regex=True)==False)].index
gaPVAllYearsCleanPagePath = gaPVAllYearsCleanPagePath.iloc[indexGoodPagePath]
gaPVAllYearsCleanPagePath.reset_index(inplace=True, drop=True) #on reindexe
gaPVAllYearsCleanPagePath.count() #73301 #même chose qu'avec R !!!!!!
#creation de la dataframe daily_data par jour
dfDatePV = gaPVAllYearsCleanPagePath[['date', 'pageviews']].copy() #nouveau dataframe avec que la date et le nombre de pages vues
daily_data = dfDatePV.groupby(dfDatePV['date']).count() #
#dans l'opération précédente la date est partie dans l'index
daily_data['date'] = daily_data.index #
daily_data['cnt_ma30'] = daily_data['pageviews'].rolling(window=30).mean()
daily_data['Année'] = daily_data['date'].astype(str).str[:4]
#Graphique pages vues par jour
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='pageviews', hue='Année', data= daily_data,
palette=sns.color_palette("husl",n_colors=8))
fig.suptitle("L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ", fontsize=14, fontweight='bold')
ax.set(xlabel='Année', ylabel='Nbre pages vues / jour',
title="suite au nettoyage des pages d'administration par rapport aux nettoyages précédents.")
fig.text(.9,-.05,"Nombre de pages vues par jour depuis 2011 \n Données net. variable pagePath",
fontsize=9, ha="right")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#plt.show()
fig.savefig("PV-s2011-Clean-PagePath.png", bbox_inches="tight", dpi=600)
#Graphique Moyenne Mobile 30 jours.
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='cnt_ma30', hue='Année', data= daily_data,
palette=sns.color_palette("husl",n_colors=8))
fig.suptitle("L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ", fontsize=14, fontweight='bold')
ax.set(xlabel='Année', ylabel='Nbre pages vues / jour en moyenne mobile',
title="suite au nettoyage des pages d'administration par rapport aux nettoyages précédents.")
fig.text(.9,-.05,"Nombre de pages vues par jour depuis 2011 en moy. mob. 30 j. \n Données net. variable pagePath",
fontsize=9, ha="right")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#plt.show()
fig.savefig("PV-s2011-Clean-PagePath-mm30.png", bbox_inches="tight", dpi=600)
###############################################################################
# Sauvegarde en csv
gaPVAllYearsCleanPagePath.to_csv("gaPVAllYearsCPP.csv", sep=";", index=False) #séparateur ;
###############################################################################
PAGE VUES APRES SUPPRESSION DES PAGES D’ADMINISTRATION
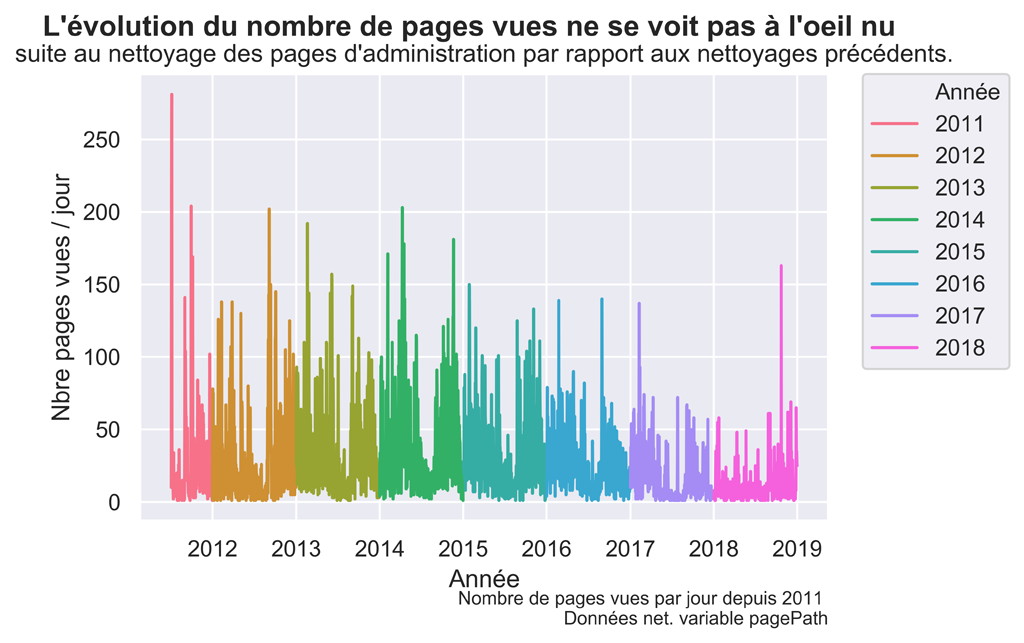
Nettoyage des pages dont l’entrée sur le site s’est faite via l’administration : variable landingPagePath.
Comme précédemment, la liste des pages dépend de votre CMS. pour nous il s’agit de WordPress.
#Relecture ############
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
gaPVAllYearsCleanPagePath = pd.read_csv("gaPVAllYearsCPP.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
gaPVAllYearsCleanPagePath.dtypes
gaPVAllYearsCleanPagePath.count() #73301 enregistrements
gaPVAllYearsCleanPagePath.head(20)
##############################################################################
##########################################################################
#nettoyage des pages dont l'entrée sur le site s'est faite
#via l'administration, variable landingPagePath
##########################################################################
gaPVAllYearsCleanLandingPagePath = gaPVAllYearsCleanPagePath.copy() #=on fait une copie ici
patternBadLandingPagePath = ["/wp-login\\.php", "/wp-admin/", "/cron/", "/?p=\\d"]
pattern = '|'.join(patternBadLandingPagePath)
indexGoodLandingPagePath = gaPVAllYearsCleanLandingPagePath[(gaPVAllYearsCleanLandingPagePath.landingPagePath.str.contains(pat=pattern,regex=True)==False)].index
gaPVAllYearsCleanLandingPagePath = gaPVAllYearsCleanLandingPagePath.iloc[indexGoodLandingPagePath]
gaPVAllYearsCleanLandingPagePath.reset_index(inplace=True, drop=True) #on reindexe
gaPVAllYearsCleanLandingPagePath.count() #72822 #même chose qu'avec R !!!!!!
#creation de la dataframe daily_data par jour
dfDatePV = gaPVAllYearsCleanLandingPagePath[['date', 'pageviews']].copy() #nouveau dataframe avec que la date et le nombre de pages vues
daily_data = dfDatePV.groupby(dfDatePV['date']).count() #
#dans l'opération précédente la date est partie dans l'index
daily_data['date'] = daily_data.index #recrée la colonne date.
daily_data['cnt_ma30'] = daily_data['pageviews'].rolling(window=30).mean()
daily_data['Année'] = daily_data['date'].astype(str).str[:4]
#Graphique pages vues par jour
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='pageviews', hue='Année', data= daily_data,
palette=sns.color_palette("husl",n_colors=8))
fig.suptitle("L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ", fontsize=14, fontweight='bold')
ax.set(xlabel='Année', ylabel='Nbre pages vues / jour',
title="suite au nettoyage des pages d'administration référentes par rapport aux nettoyages précédents.")
fig.text(.9,-.05,"Nombre de pages vues par jour depuis 2011 \n Données net. variable landingPagePath",
fontsize=9, ha="right")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#plt.show()
fig.savefig("PV-s2011-Clean-LandingPagePath.png", bbox_inches="tight", dpi=600)
#Graphique Moyenne Mobile 30 jours.
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='date', y='cnt_ma30', hue='Année', data= daily_data,
palette=sns.color_palette("husl",n_colors=8))
fig.suptitle("L'évolution du nombre de pages vues ne se voit pas à l'oeil nu ", fontsize=14, fontweight='bold')
ax.set(xlabel='Année', ylabel='Nbre pages vues / jour en moyenne mobile',
title="suite au nettoyage des pages d'administration référentes par rapport aux nettoyages précédents.")
fig.text(.9,-.05,"Nombre de pages vues par jour depuis 2011 en moy. mob. 30 j. \n Données net. variable landingPagePath",
fontsize=9, ha="right")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#plt.show()
fig.savefig("PV-s2011-Clean-LandingPagePath-mm30.png", bbox_inches="tight", dpi=600)
###############################################################################
# Sauvegarde en csv
gaPVAllYearsCleanLandingPagePath.to_csv("gaPVAllYearsCLPP.csv", sep=";", index=False) #séparateur ;
###############################################################################
PAGES VUES APRES NETTOYAGE DE la variable landingPAGEPATH
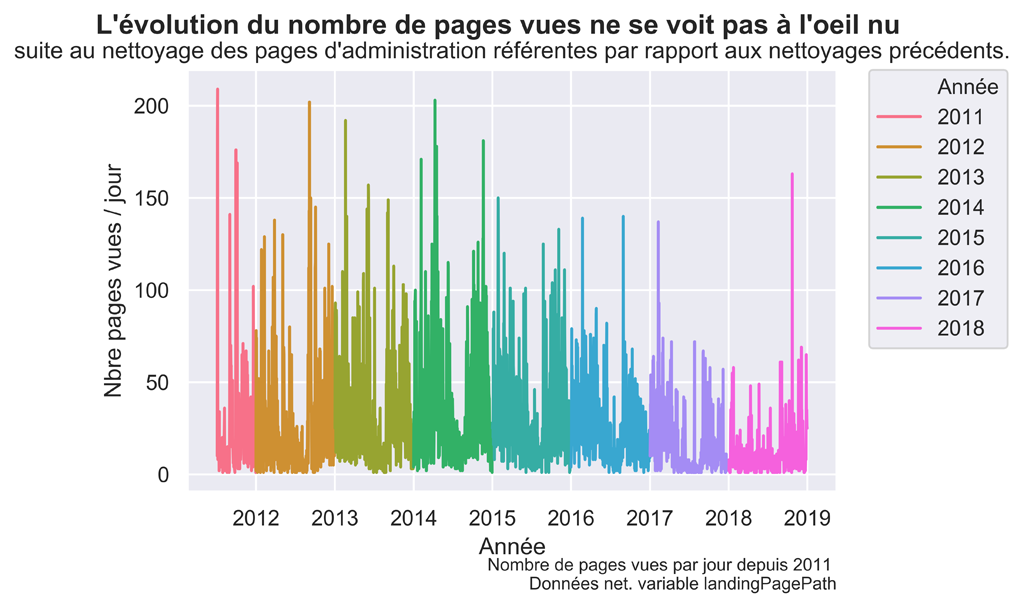
Il s’agissait de la dernière étape. Au début nous avions 82559 observations et à la fin nous trouvons 72821 enregistrements soit près de 10000 ou 15% de spam ce qui n’est pas négligeable.
Jeu de données nettoyé
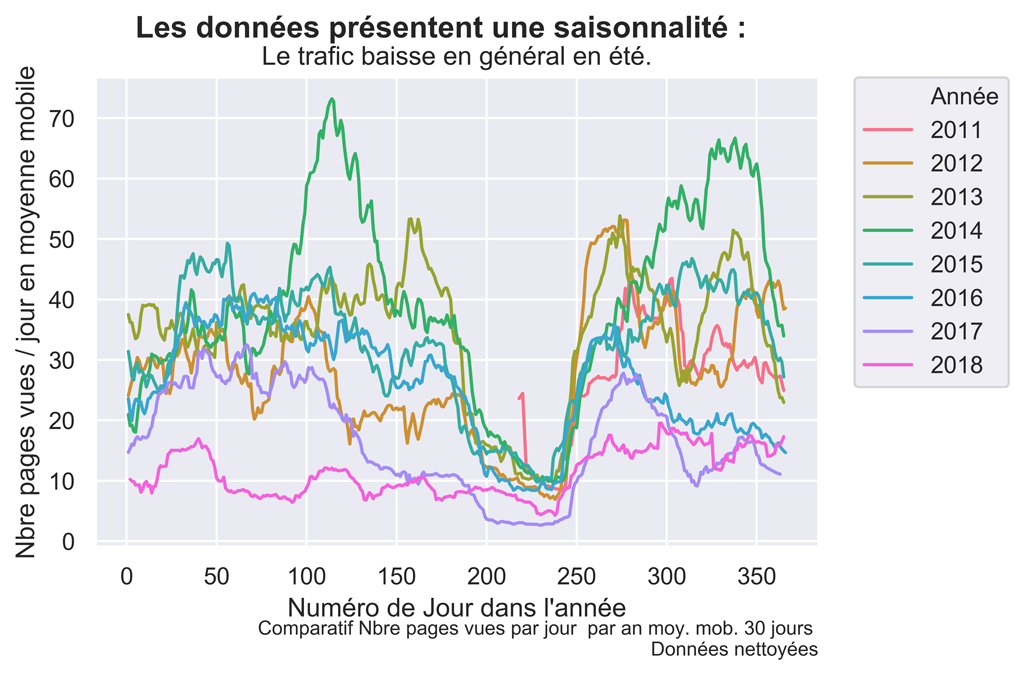
Pour finir, comparons les différentes années sur le jeu de données nettoyé.
#Relecture ############
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
gaPVAllYearsCleanLandingPagePath = pd.read_csv("gaPVAllYearsCLPP.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
gaPVAllYearsCleanLandingPagePath.dtypes
gaPVAllYearsCleanLandingPagePath.count() #72821 enregistrements
gaPVAllYearsCleanLandingPagePath.head(20)
##############################################################################
##########################################################################
# Jeu de données nettoyé
##########################################################################
#nom de sauvegarde plus facile à retenir :
dfPageViews = gaPVAllYearsCleanLandingPagePath.copy() #=on fait une copie ici
###############################################################################
# Sauvegarde en csv
dfPageViews.to_csv("dfPageViews.csv", sep=";", index=False) #séparateur ;
###############################################################################
#Relecture ############
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
dfPageViews = pd.read_csv("dfPageViews.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
dfPageViews.dtypes
dfPageViews.count() #72822 enregistrements
dfPageViews.head(20)
##############################################################################
#creation de la dataframe daily_data par jour
dfDatePV = dfPageViews[['date', 'pageviews']].copy() #nouveau dataframe avec que la date et le nombre de pages vues
daily_data = dfDatePV.groupby(dfDatePV['date']).count() #
#dans l'opération précédente la date est partie dans l'index
daily_data['date'] = daily_data.index #recrée la colonne date.
daily_data['cnt_ma30'] = daily_data['pageviews'].rolling(window=30).mean()
daily_data['Année'] = daily_data['date'].astype(str).str[:4]
daily_data['DayOfYear'] = daily_data['date'].dt.dayofyear #récupère la date du jour
#Graphique Moyenne Mobile 30 jours.
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.lineplot(x='DayOfYear', y='cnt_ma30', hue='Année', data= daily_data,
palette=sns.color_palette("husl",n_colors=8))
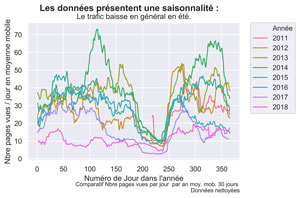
fig.suptitle("Les données présentent une saisonnalité : ", fontsize=14, fontweight='bold')
ax.set(xlabel="Numéro de Jour dans l'année", ylabel='Nbre pages vues / jour en moyenne mobile',
title="Le trafic baisse en général en été.")
fig.text(.9,-.05,"Comparatif Nbre pages vues par jour par an moy. mob. 30 jours \n Données nettoyées",
fontsize=9, ha="right")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#plt.show()
fig.savefig("PV-Comparatif-mm30.png", bbox_inches="tight", dpi=600)
# Sauvegarde en csv
daily_data.to_csv("DailyDataCleanPython.csv", sep=";", index=False) #séparateur ;
##########################################################################
# MERCI pour votre attention !
##########################################################################
#on reste dans l'IDE
#if __name__ == '__main__':
# main()
Graphique Comparatif des PAGES VUES EN MOYENNE MOBILE SUR 30 JOURS PAR ANNEES
Vous pouvez retrouver le code source en entier et les fichiers nécessaires dans notre Github à l’adresse https://github.com/Anakeyn/CleanSpamGAwPython
N’hésitez pas à laisser vos avis, conseils et remarques en commentaires,
A Bientôt,
Pierre