Partager la publication "Classification de pages Web via Deep Learning – Réseau de Neurones Convolutif"
Cet article fait partie d’une série d’articles sur la classification de pages Web dans Google via le Deep Learning.
Cette série a démarré par un article sur l’utilisation d’un réseau de neurones à propagation avant ou perceptron multicouches simple.
Nous allons cette fois utiliser un Réseau de Neurones Convolutif pour résoudre notre problème.
Traditionnellement les réseaux de neurones convolutifs sont utilisés pour la reconnaissance d’images.
Nous verrons comment utiliser la bibliothèque Keras pour adapter la forme d’un réseau pour traiter des données numériques représentant des caractéristiques de pages Web et de sites.
Comment fonctionne un réseau de neurones convolutif ?
Les réseaux de neurones convolutifs s’inspirent de la vision des êtres humains et des animaux et notamment de notre capacité à reconnaître des motifs dans des images.
Par exemple nous sommes capables de voir en un instant qu’un chat à des oreilles pointues et de longues moustaches :

Un réseau de neurones convolutif peut être divisés en 2 grandes parties : la partie de convolution à proprement parlée et la partie classification qui est en fait un réseau Feed Forward classique. En anglais cette partie s’appelle aussi Fully Connected :
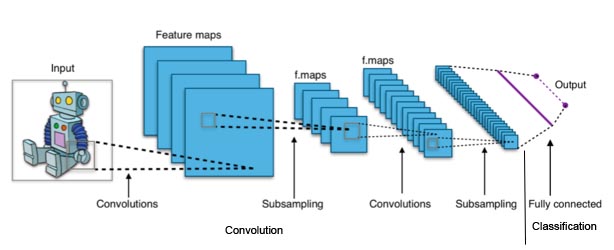
Partie Convolution
Dans la partie convolution on distingue 3 types de couches :
- Les couches de convolutions
- Les couches de pooling
- les couches de correction ReLU
Source: http://cs231n.github.io/assets/cnn/convnet.jpeg
Couche de convolution
La couche de convolution a pour objectif de trouver des caractéristiques (ou features, ou éléments, ou patterns) dans les images.
Pour cela, on va filtrer les images en faisant glisser un masque (ou fenêtre, ou kernel/noyau) pour repérer une caractéristique (par exemple un arc, ou une pointe d’oreille, ou un museau etc) dans l’image.
On utilisera plusieurs masques pour repérer différentes structures. Toutefois ce qu’il faut comprendre, c’est que ce n’est pas nous qui choisissons la forme des caractéristiques mais le réseau lui même, lors de la phase d’entrainement ou d’apprentissage.
Ils sont initialisés puis mis à jour par rétropropagation du gradient.
On déterminera cependant 3 hyper paramètres :
- Le nombre de noyaux (ou Kernels K/fenêtres/masques/filtres)de convolutions
- le pas de déplacement (Stride S) des noyaux sur l’image
- la marge à zéro ou zéro Padding P : le zéro Padding sert à contrôler la taille du volume en sortie. On peut vouloir conserver par exemple la même taille du volume en sortie que celui en entrée, auquel cas on remplira les zones de 0 :
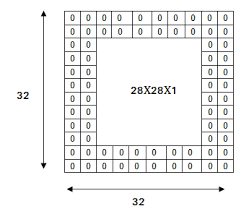
Notez bien qu’à la sortie de la convolution, le volume de sortie est plus petit qu’en entrée et dépend de la taille du noyau et du zéro Padding.
Voici un exemple de convolution :
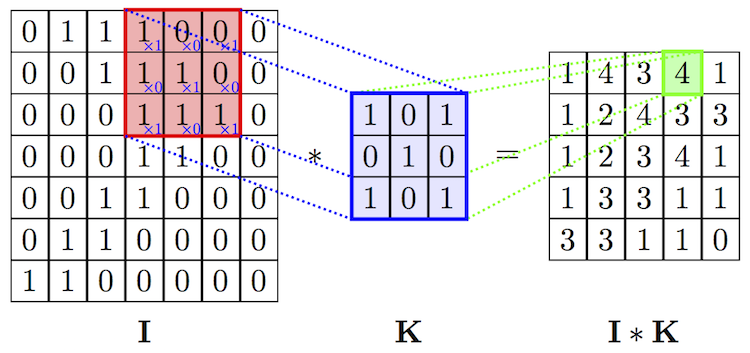
I est la matrice d’entrée (Input), K est le noyau (Kernel). la valeur 4 est obtenue en faisant la somme des produits des valeurs de la fenêtre dans la matrice d’entrée par les valeurs du noyau :
1*1+0*0+0*1+0*1+1*1+0*0+1*1+1*0+1*1=4
La taille du volume de sortie « W output » est donnée par la formule (pour chaque dimension)
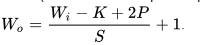
Ici le pas de déplacement ou « stride » S est de 1, la taille en entrée W input est 7, la taille du noyau K est 3, la taille du zéro Padding P est 0.
Ceci qui nous donne ((7-3)/1)+1 = 5. Comme c’est une matrice carrée en entrée (7×7) avec un noyau carré (3×3) le volume en sortie est de 5×5
Couche de pooling
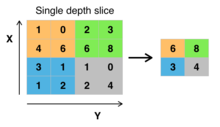
Le pooling (« mise en commun ») est une une forme de sous-échantillonnage (sub sampling) de l’image. L’image d’entrée est découpée en une série de rectangles de n pixels de côté ne se chevauchant pas.
Le pooling réduit la taille d’une image intermédiaire, réduisant ainsi la quantité de paramètres et de calcul dans le réseau
En général on utilise la fonction max pour calculer le pooling mais il est possible d’utiliser d’autres fonctions comme la moyenne ou une valeur au hasard du filtre.
Fonctionnement du max-pooling :
Couche de correction (ReLU)
Nous avions vu dans notre article précédent utilisant les réseaux feed forward que la fonction ReLU était utilisée comme fonction d’activation.
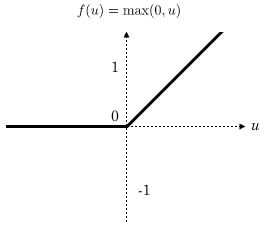
En intercalant entre les couches de traitement une couche qui va opérer une fonction mathématique sur les signaux de sortie on peut améliorer l’efficacité du réseau.
En général on choisit ici la fonction ReLU (Rectifier Linear Unit) .
Remarque : dans Keras la fonction ReLU est directement programmée dans la couche de convolution.
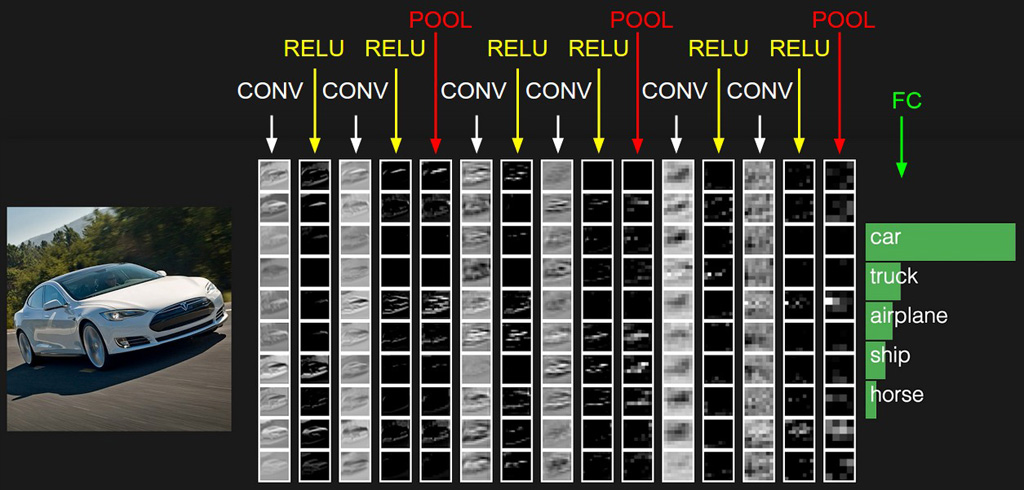
Partie Entièrement connectée (Fully Connected)
Après les phases de convolution/pooling on remet à plat toutes les données (qui se trouve dans plusieurs matrices) dans un vecteur (opération flatten)
On les passe ensuite dans une couche de neurones classique ou une couche de sortie avec par exemple une fonction sigmoïde, pour une classification binaire ou un softmax pour une classification multi classes.
Comme le cas exemple ici, où on demande au système de différencier les voitures, les camions, les avions les bateaux et les chevaux.
Dans notre cas, comment allons nous procéder ?
Effectivement, en ce qui concerne notre problématique nous ne fonctionnons pas avec des images, mais avec des observations de positionnement dans Google en fonction de critères (en l’occurrence 61 critères).
En fait, nous allons traiter le problème en considérant nos observations comme des images en 1 dimension au lieu de 2.
Par exemple, au lieu d’avoir des images de 32×32 pixels, nous allons avoir des images de 1×61 pixels.
De quoi aurons nous besoin ?
Reportez-vous à notre article précédent sur l’utilisation d’un réseau de neurones Feed Forward pour installer Python Anaconda 3.6, Tensorflow 1.5 et Keras 2.0.
Jeu de données
Téléchargez le jeu de données Mots-clés/Pages/Positions/Caractéristiques sur notre GitHub à l’adresse : https://raw.githubusercontent.com/Anakeyn/GSCCompetitorsDeepLearning2/master/dfQPPS7.csv
Code Source
Vous pouvez copier/coller les morceaux de code source suivants ou télécharger le tout gratuitement dans notre boutique à l’adresse : https://www.anakeyn.com/boutique/produit/script-python-classification-via-reseau-de-neurones-convolutif/
Chargement des bibliothèques utiles
Attention il faut installer les bibliothèques manquantes à partir du prompt d’Anaconda avec la commande conda install ou pip.
# -*- coding: utf-8 -*- """ Created on Mon Jan 13 10:29:18 2020 @author: Pierre """ ########################################################################## # GSCCompetitorsDL2 - réseau de neurones convolutif # Auteur : Pierre Rouarch - Licence GPL 3 # Classification des pages Web dans Google sur un mot clé en fonctions de caractérisitiques # Deep Learning sur un univers de concurrence # Utilisation d'un réseau de neurones convolutif simple pour une classification binaire # Données enrichiees via Scraping précédemment. ##################################################################################### ################################################################### # On démarre ici ################################################################### #Chargement des bibliothèques générales utiles #Remarque installer les bibliothèques manquantes via conda install #import numpy as np #pour les vecteurs et tableaux notamment import matplotlib.pyplot as plt #pour les graphiques #import scipy as sp #pour l'analyse statistique - non utilisé. import pandas as pd #pour les Dataframes ou tableaux de données import os #scaler from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split #for Deep Learning from keras import models from keras import layers print(os.getcwd()) #verif my path #mon répertoire sur ma machine - nécessaire quand on fait tourner le programme #par morceaux dans Spyder. #myPath = "C:/Users/Pierre/MyPath" #os.chdir(myPath) #modification du path #print(os.getcwd()) #verif
Récupération du jeu de données
Comme précédemment, on charge le jeu de données pour le Machine Learning et on crée un set d’entrainement et un set de test.
#############################################################
# Deep Learning sur les données enrichies après scraping
#############################################################
#Lecture des données suite à scraping ############
dfQPPS8 = pd.read_csv("dfQPPS7.csv")
dfQPPS8.info(verbose=True) # 12194 enregistrements.
dfQPPS8.reset_index(inplace=True, drop=True)
#Variables explicatives
X = dfQPPS8[['isHttps', 'level',
'lenWebSite', 'lenTokensWebSite', 'lenTokensQueryInWebSiteFrequency', 'sumTFIDFWebSiteFrequency',
'lenPath', 'lenTokensPath', 'lenTokensQueryInPathFrequency' , 'sumTFIDFPathFrequency',
'lenTitle', 'lenTokensTitle', 'lenTokensQueryInTitleFrequency', 'sumTFIDFTitleFrequency',
'lenDescription', 'lenTokensDescription', 'lenTokensQueryInDescriptionFrequency', 'sumTFIDFDescriptionFrequency',
'lenH1', 'lenTokensH1', 'lenTokensQueryInH1Frequency' , 'sumTFIDFH1Frequency',
'lenH2', 'lenTokensH2', 'lenTokensQueryInH2Frequency' , 'sumTFIDFH2Frequency',
'lenH3', 'lenTokensH3', 'lenTokensQueryInH3Frequency' , 'sumTFIDFH3Frequency',
'lenH4', 'lenTokensH4','lenTokensQueryInH4Frequency', 'sumTFIDFH4Frequency',
'lenH5', 'lenTokensH5', 'lenTokensQueryInH5Frequency', 'sumTFIDFH5Frequency',
'lenH6', 'lenTokensH6', 'lenTokensQueryInH6Frequency', 'sumTFIDFH6Frequency',
'lenB', 'lenTokensB', 'lenTokensQueryInBFrequency', 'sumTFIDFBFrequency',
'lenEM', 'lenTokensEM', 'lenTokensQueryInEMFrequency', 'sumTFIDFEMFrequency',
'lenStrong', 'lenTokensStrong', 'lenTokensQueryInStrongFrequency', 'sumTFIDFStrongFrequency',
'lenBody', 'lenTokensBody', 'lenTokensQueryInBodyFrequency', 'sumTFIDFBodyFrequency',
'elapsedTime', 'nbrInternalLinks', 'nbrExternalLinks' ]] #variables explicatives
X.info()
y = dfQPPS8['group'] #variable à expliquer,
##Sciikit Learn Scaler
scaler = StandardScaler() # Standard Scaler
scaler.fit(X)
X_Scaled = pd.DataFrame(scaler.transform(X.values), columns=X.columns, index=X.index)
X_Scaled.info()
#check values
plt.hist( X_Scaled['isHttps'])
plt.hist( X_Scaled['lenTokensWebSite'])
#Manual Scaled - same as StandardScaler
#X_Mean = X
#X_Mean -= X_Mean.mean(axis=0)
#X_ManualScaled = X_Mean
#X_ManualScaled /= X_Mean.std(axis=0)
#plt.hist( X_ManualScaled['isHttps'])
#plt.hist( X_ManualScaled['lenTokensWebSite'])
#X_Scaled = X_ManualScaled
########################################################
#on choisit random_state = 42 en hommage à La grande question sur la vie, l'univers et le reste
#dans "Le Guide du voyageur galactique" par Douglas Adams. Ceci afin d'avoir le même split
#tout au long de notre étude.
X_train, X_test, y_train, y_test = train_test_split(X_Scaled,y, random_state=42)
X_train.shape #format des données au départ
#(9145, 61)
Paramétrage du réseau de Neurones convolutif
Pour pouvoir utiliser le réseau de neurones convolutif en dimension 1 on doit au préalable reformater nos données.
Le réseau choisi est relativement simple, il comporte :
- Une couche de convolution
- Un zero padding
- Une deuxième couche de convolution
- Une couche de max pooling
- Une couche Fully Connected
- Enfin, une couche de sortie avec une sigmoïde.
######################################################### # Réseau de Neurones convolutif simple ######################################################### #on considère que l'on a une image de 61x1 pixels sur 1 couleur => conv1D #on va reformater les données #Reshape des données pour être utilisables dans le réseau de neurones convolutif X_train_values = X_train.values y_train_values = y_train.values X_train_values = X_train_values.reshape((X_train_values.shape[0],X_train_values.shape[1],1)) X_train_values.shape #X_train_values = np.expand_dims(X_train_values, axis=2) #autre méthode de reshape X_test_values = X_test.values y_test_values = y_test.values X_test_values = X_test_values.reshape((X_test_values.shape[0],X_test_values.shape[1],1)) #X_test_values = np.expand_dims(X_test_values, axis=2) #autre méthode de reshape unitsNumber = 40 #(~2/3*( 61+1)) #Reseau simple avec 1 couche de convolution, 1 zero padding, 1 couche de convolution, 1 couche de pooling #une couche standard FC et une couche de sortie sigmoide car on cherche top10 ou non. model = models.Sequential() model.add(layers.Conv1D(filters=unitsNumber, kernel_size=3, activation='relu', input_shape=(61,1))) model.add(layers.ZeroPadding1D(padding=1)) model.add(layers.Conv1D(filters=unitsNumber, kernel_size=3, activation='relu')) model.add(layers.MaxPooling1D(pool_size=2)) model.add(layers.Flatten()) # now output shape == (None, 1160) model.add(layers.Dense(unitsNumber, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) #sortie binaire #my CNN model.summary()
Le résumé du modèle indique les paramètres suivants :

Compilation et entrainement du modèle
#Compile and train the model model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy']) #you could check #model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc']) #model.compile(optimizer='sgd',loss='binary_crossentropy',metrics=['acc']) #model.compile(optimizer='Nadam',loss='binary_crossentropy',metrics=['acc']) #train history = model.fit(X_train_values, y_train_values, epochs=30, batch_size=16, validation_data=(X_test_values, y_test_values))
Graphiques et résultats
############################################################
#Graphiques et résultats
history_dict = history.history
history_dict.keys()
# dict_keys(['val_loss', 'val_acc', 'loss', 'acc'])
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
acc = history_dict['acc']
val_acc = history_dict['val_acc'] #ce qui nous intéresse
epochs = range(1, len(acc) + 1)
plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.savefig("QPPS8-CNN-Loss.png", bbox_inches="tight", dpi=600)
plt.show()
#Evaluate the model
plt.clf()
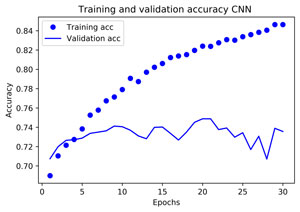
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy CNN ')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.savefig("QPPS8-CNN-Accuracy.png", bbox_inches="tight", dpi=600)
plt.show() #!!!! affiche et remet à zéro => sauvegarder avant
max(acc) #meilleure valeur de la précision sur le train set 0.8337889557265401
acc.index(max(acc)) #28
max(val_acc) #meilleure valeur de la précision de validation sur le test set 0.7487700886122709
#mieux que xgBoost non optimisé : 0.734 et que FNN 0.7448 mais en dessous de KNN 0.7553
val_acc.index(max(val_acc)) #indice correspondant # 19
##########################################################################
# MERCI pour votre attention !
##########################################################################
#on reste dans l'IDE
#if __name__ == '__main__':
# main()
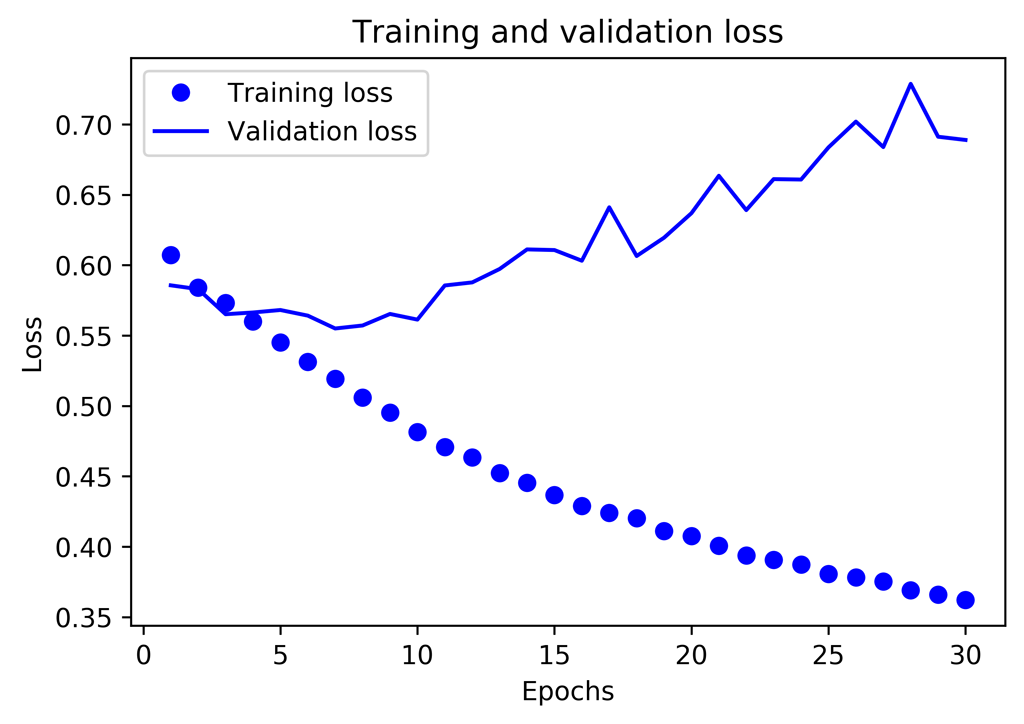
La fonction de perte indique une sur optimisation du modèle.
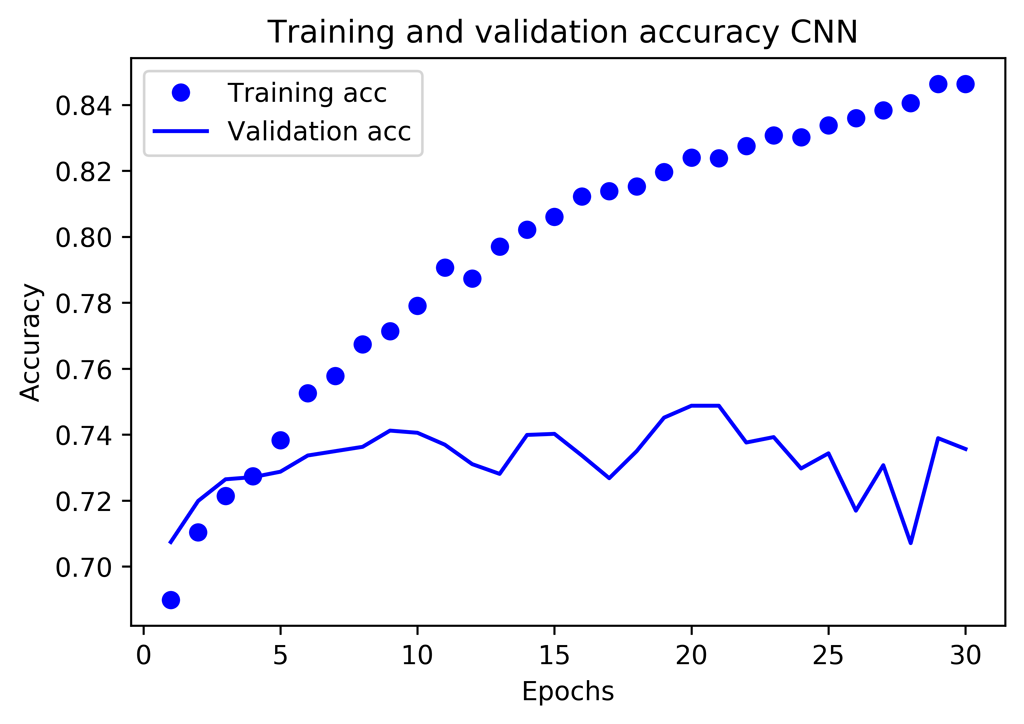
Le graphique de la précision indique aussi une forte sur optimisation.
Malgré cette sur optimisation, la meilleure précision trouvée est de 0.7488 contre 0,7448 pour le réseau Feed Forward et 0,734 pour le modèle XGBoost non optimisé mais toutefois en dessous de KNN : 0,7553.
A bientôt,
Pierre
Jean-Christophe Chouinard
15 janvier 2020 at 15 h 14 minEncore un article super intéressant Pierre. Je suis curieux de voir quel type de pages il y a dans tes données de scraping. Les pages d’un seul site ou de plusieurs sites web?
Pierre • Post Author •
15 janvier 2020 at 15 h 37 minMerci Jean-Christophe il s’agit de pages de plusieurs sites. 12194 enregistrements.