Partager la publication "Etude Données Hospitalières Covid-19 – II"
Cet article est la suite de l’article https://www.anakeyn.com/2020/05/26/etude-donnees-hospitalieres-covid-19-i/
Comme précédemment, cette étude observationnelle porte sur les données hospitalières fournies par Santé Publique France relatives au Covid-19. Nous en avons profité pour mettre à jour les données, et l’étude porte désormais du 24 février au 7 juin.
Vous pouvez télécharger gratuitement tous les fichiers nécessaires afin de reproduire notre étude à l’adresse : https://www.anakeyn.com/boutique/produit/donnees-etude-covid19-au-06-08-20/
Afin d’augmenter la plage de l’étude nous avons rapproché les données du fichier « donnees-hospitalieres-covid19-2020-06-08-19h00.csv » qui contient les données notamment de décès à partir du 18 mars et du fichier « sursaud-covid19-quotidien-2020-06-08-19h00.xlsx » qui contient des données des urgences à partir du 24 février.
Comme précédemment, quand il y avait des données incohérentes entre les 2 fichiers nous avons privilégié les données du fichier « donnees-hospitalieres-covid19-2020-06-08-19h00.csv » car les données sur les décès semblent les plus robustes.
Cette étude porte sur 101585 hospitalisations et 18718 décès au 7 juin. Pour info : Le taux de décès cumulés vs hospitalisations cumulées au 7 juin est de 18,43 % .
Evolution des hospitalisations et réanimations en France du 28 février au 07 juin 2020.
Rem : Le fichier sur lequel nous avons travaillé est « covid19_2020_06_08_LitsNZEco.xlsx« . Vous pouvez l’uploader dans Dataiku.
Les autres fichiers commençant par « covid19-2020-06-08… » sont des fichiers intermédiaires qui vous permettront de comprendre nos calculs.
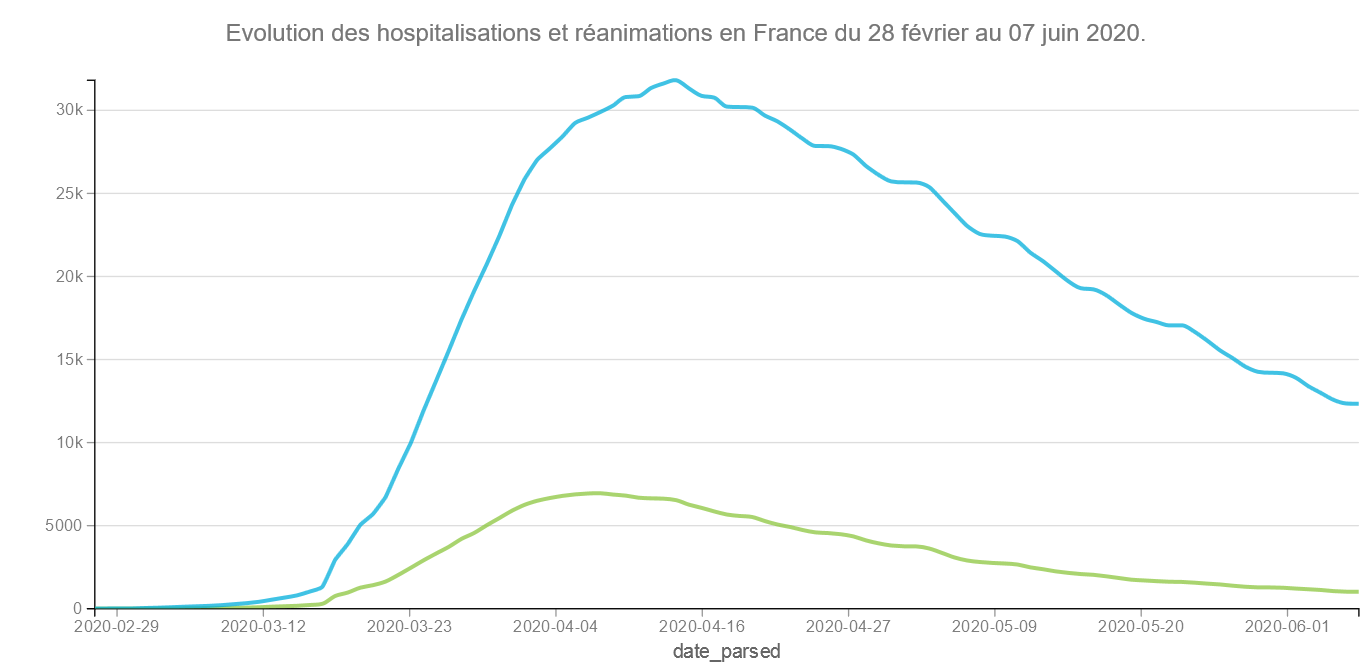
Les courbes d’hospitalisations et de réanimations continuent leurs baisses régulières.
Décès pour 100000 habitants
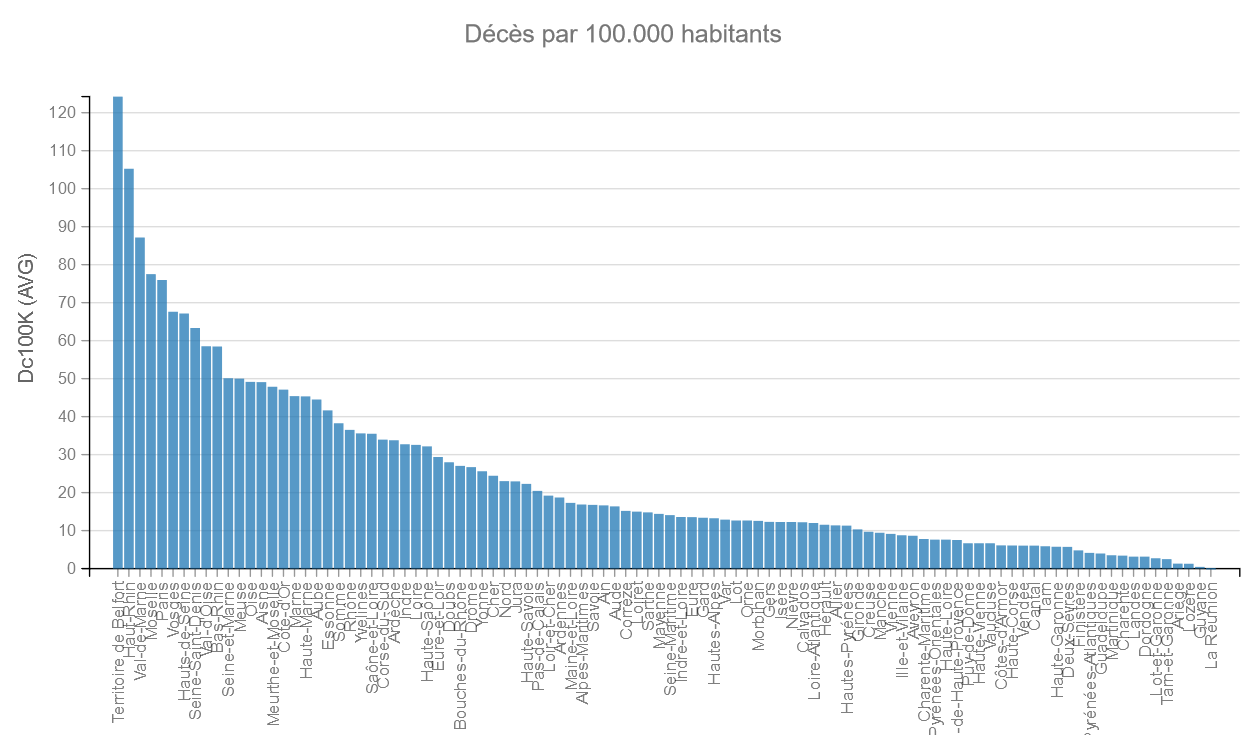
Comme on peut le voir, le taux de décès pour 100.000 habitants est très différent selon les départements sur la période : de 124 pour le Territoire de Belfort à 0.1 pour la Réunion. La dynamique de l’épidémie n’a certainement pas été la même selon les départements.
Décès pour 100000 habitants – Départements les plus peuplés.
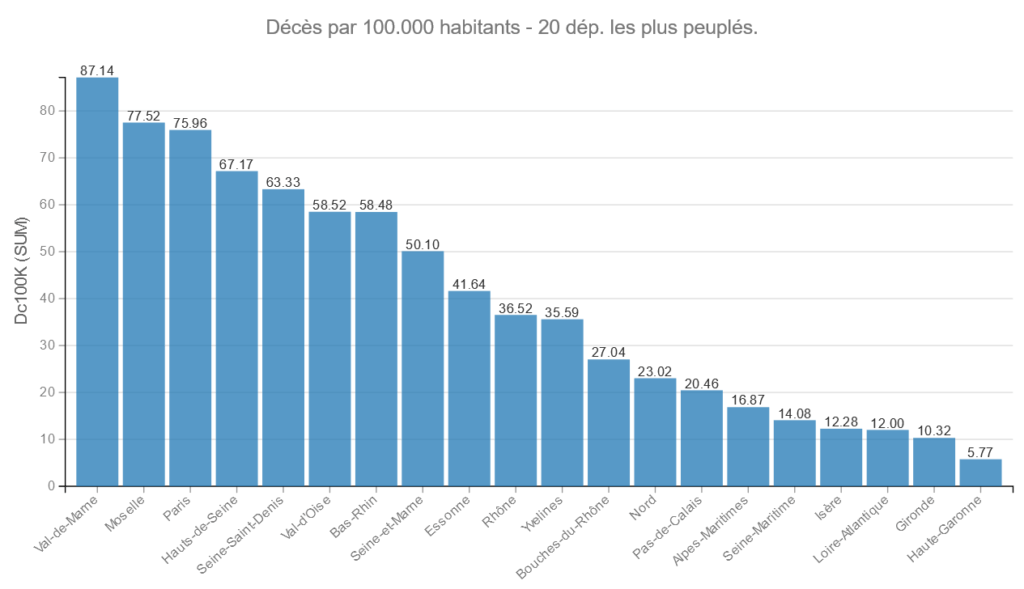
Pour information le taux de décès moyen pour 100.000 habitants était de 39.69 personnes sur la période.
Au contraire de ce qu’ont pu dire certaines personnes : « Le taux de mortalité en Seine -Saint-Denis était de 60 fois supérieur à la moyenne nationale » (Virginie Despentes in Lettres d’Intérieur sur France Inter) 🙂 , le taux de décès pour 100.000 habitants calculé ici est en réalité 1.60 plus élevé.
C’est beaucoup, mais moins que ses voisines riches Paris (1.91) et les Hauts de Seine (1,69) … 🙂
Analyses via Machine Learning dans Dataiku : Mêmes données que précédemment.
Comme précédemment et afin de voir s’il y avait des évolutions nous avons effectué de nouvelles analyses avec les mêmes variables que précédemment. L’analyse porte sur une période plus grande de données que précédemment (dans les faits du 28 février au 7 juin 2020)
Les données utiles se trouvent dans le fichier « covid19_2020_06_08_LitsNZEco.xlsx«
L’analyse donne les résultats globaux suivants :
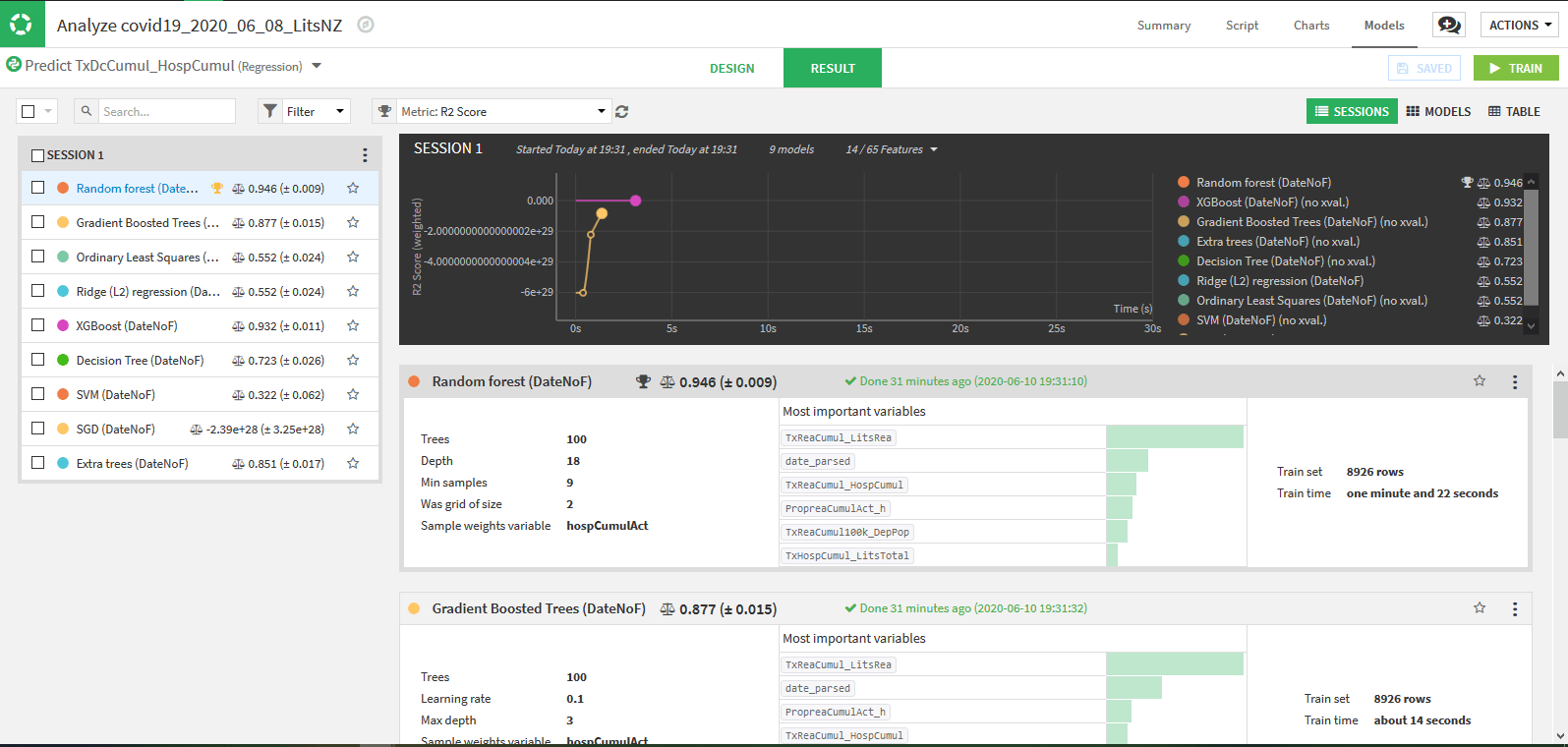
Cette fois encore, Random Forest donne les meilleurs résultats.
Résultats par Modèles
Random Forest
Ce modèle obtient le meilleur R2 Score : 0.946
Importance des variables :
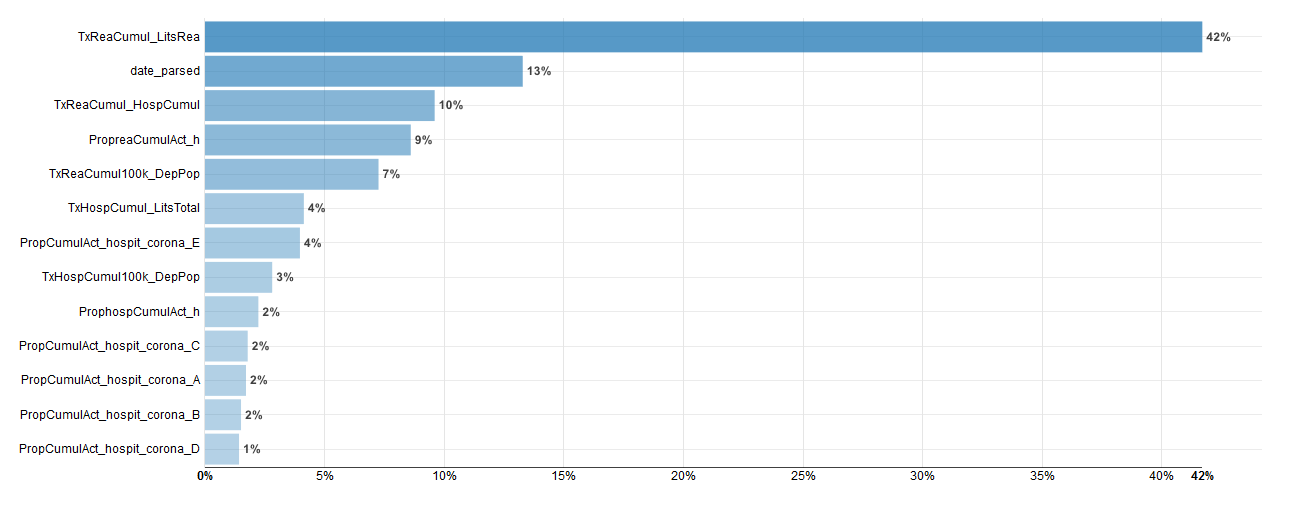
Mis à part la date (ce qui est une évidence) les variables qui expliquent le mieux le modèle sont les variables de saturations de lits de réanimations et de lits au total.
Départements :
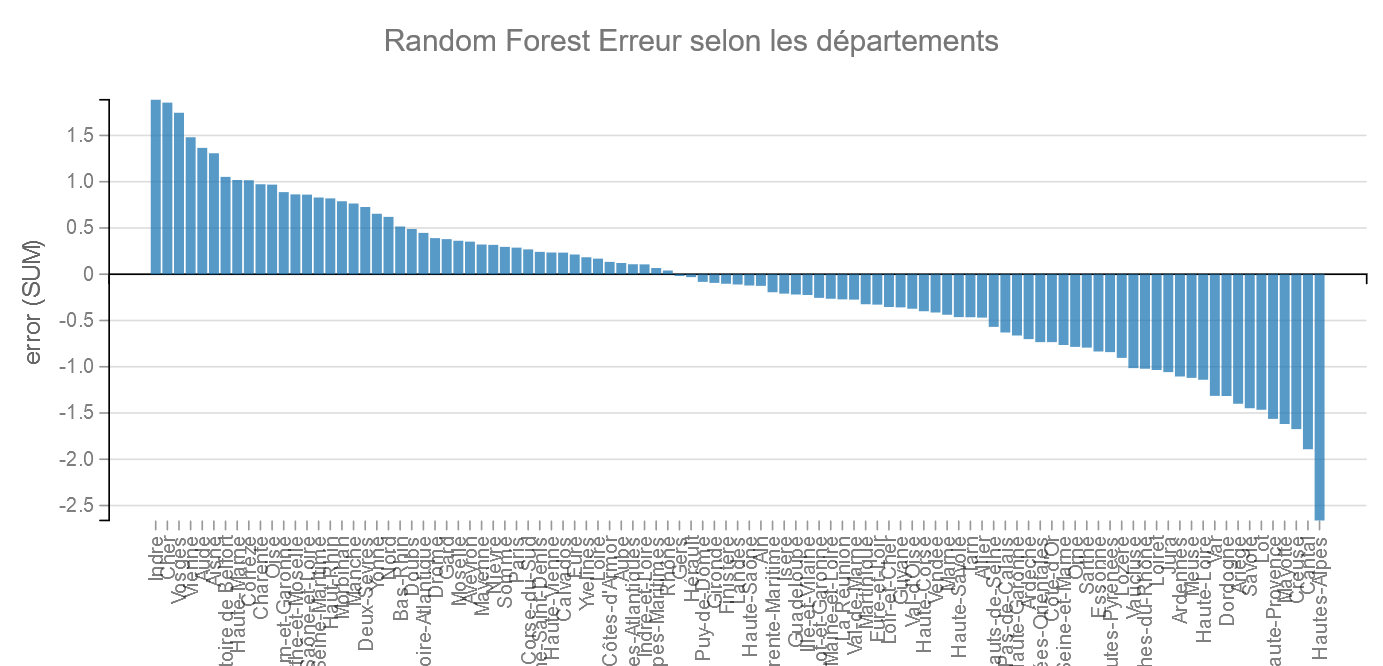
Cette fois ce sont les Hautes-Alpes et le Cantal les bons élèves et l’Indre et le Cher les mauvais (sous réserve de la validité des proportions).
Pour plus de lisibilité regardons les 20 départements les plus peuplés :
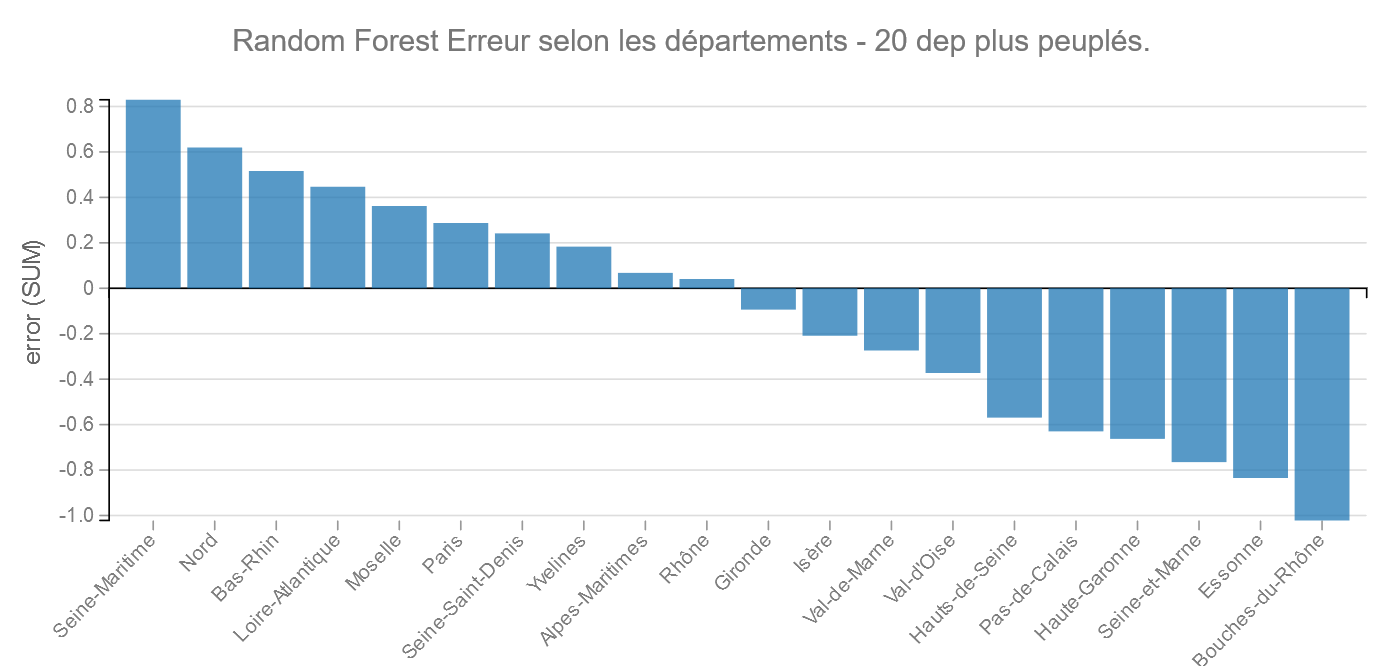
Comme précédemment, les Bouches-du-Rhône est dans les bons élèves.
XGBoost
R2 Score : 0.932
Importance des variables :
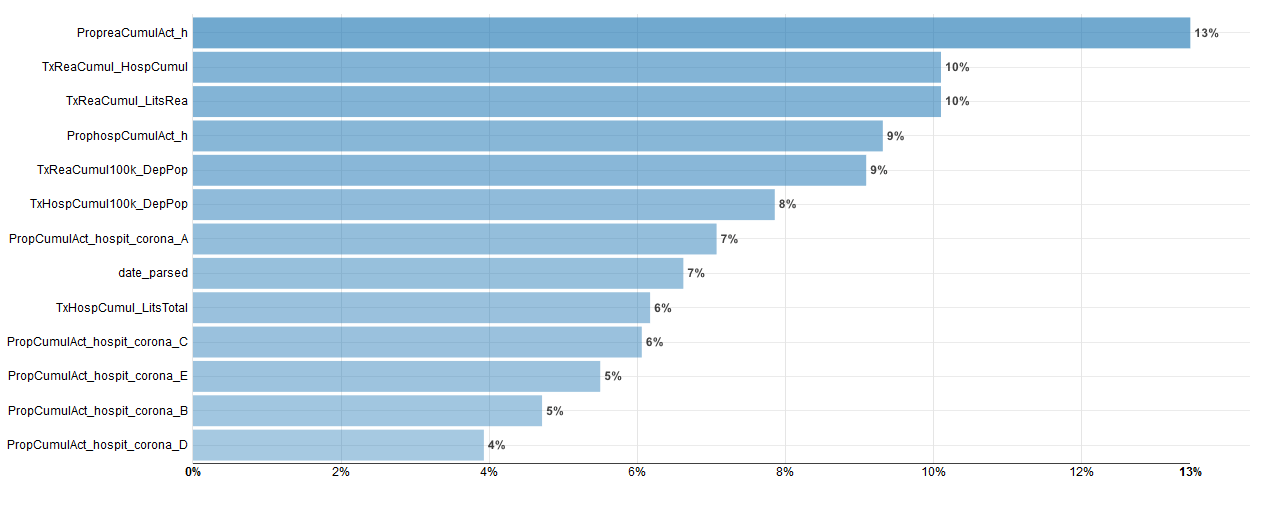
Ici les variables importantes diffèrent un peu du modèle précédent, le facteur sexe apparait important, toutefois les facteurs liés à l’occupation des lits de Réanimation sont aussi importants.
20 départements les plus peuplés :
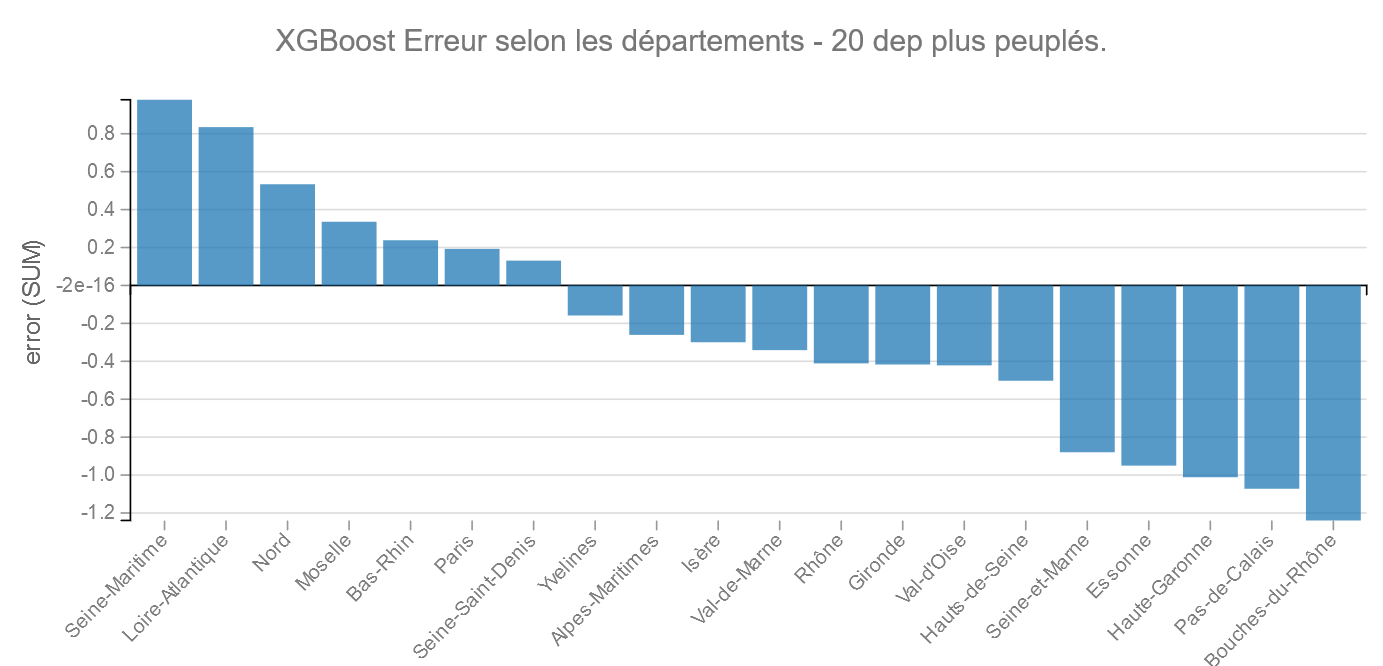
On retrouve encore une fois les Bouches-du-Rhône comme bon élève
Gradient Boosted Trees :
R2 Score : 0.851
Importance des variables :
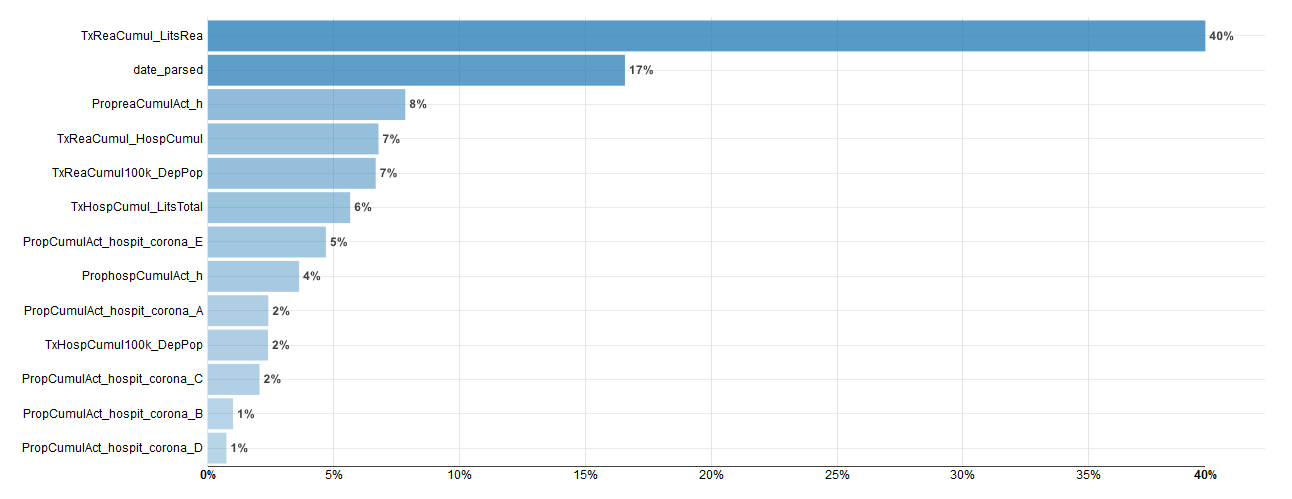
Ici le facteur de saturation des lits de réanimation est largement le plus important.
Départements les plus peuplés :
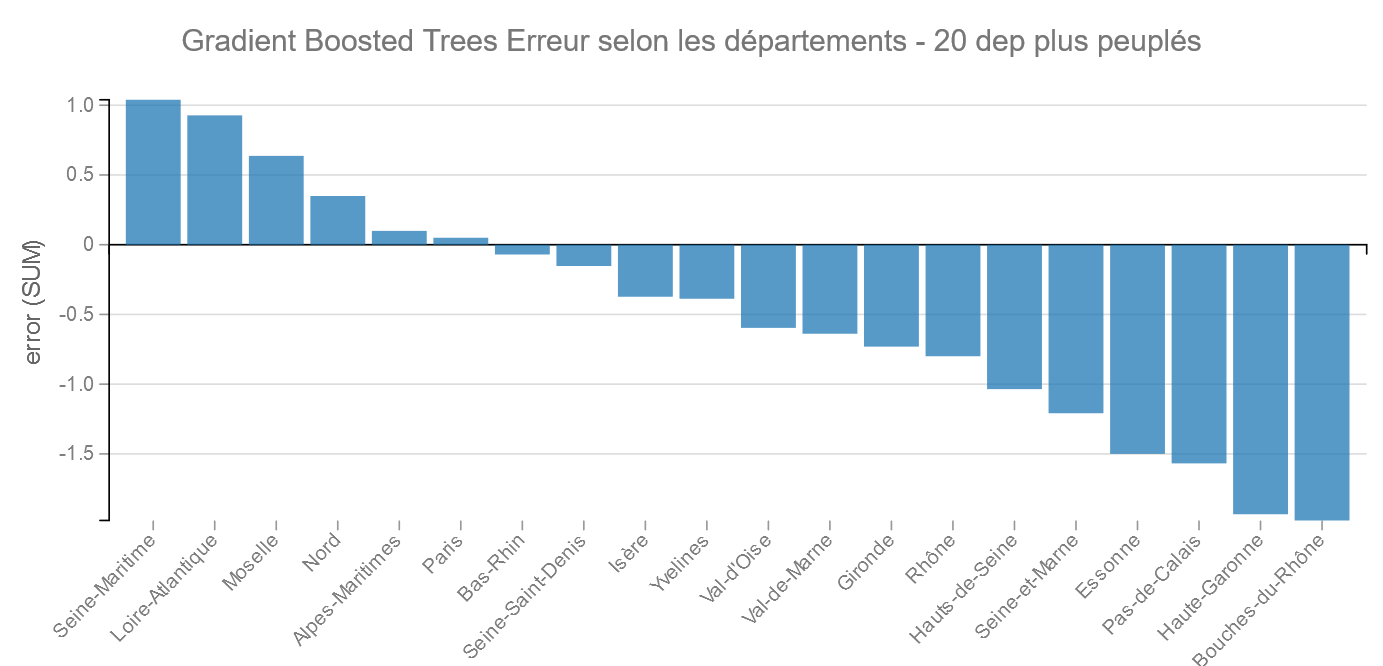
Encore les Bouches-du-Rhône comme bon élève !
Extra Trees
R2 Score : 0.851
Importances des variables :
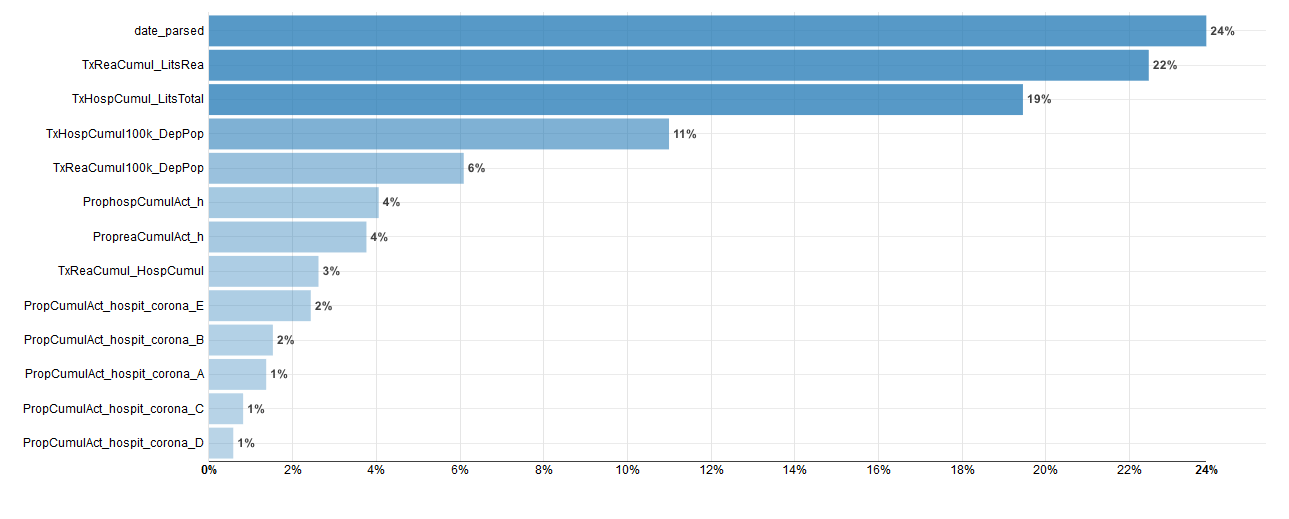
Mis à part la date (ce qui est une évidence compte tenu de notre modèle cumulatif) les facteurs liés à la saturation des hôpitaux sont parmi les plus importants.
Départements les plus peuplés :
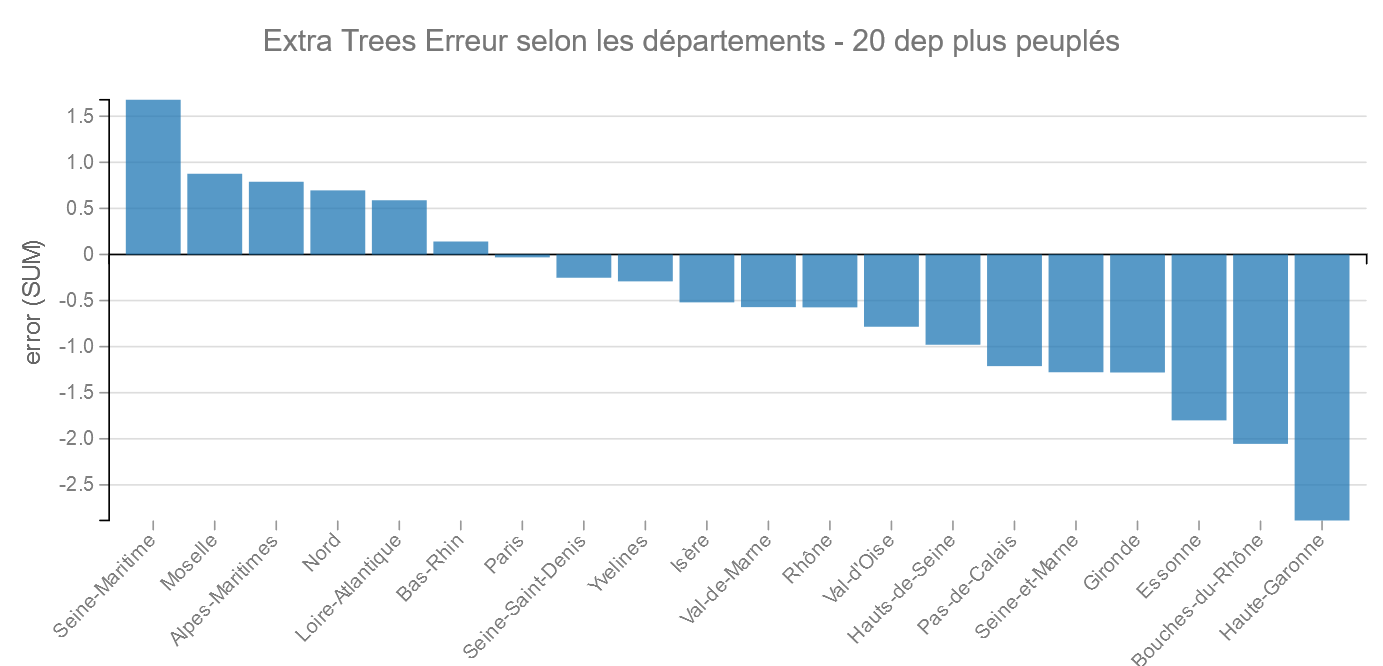
Cette fois c’est la Haute-Garonne qui se place le mieux, juste avant les Bouches-du-Rhône.
Ordinary Least Squares (Moindres Carrés)
R2 Score : 0.552 (bien en dessous des autres modèles)
Comme c’est un modèle linéaire on peut avoir les coefficients de régression des variables :
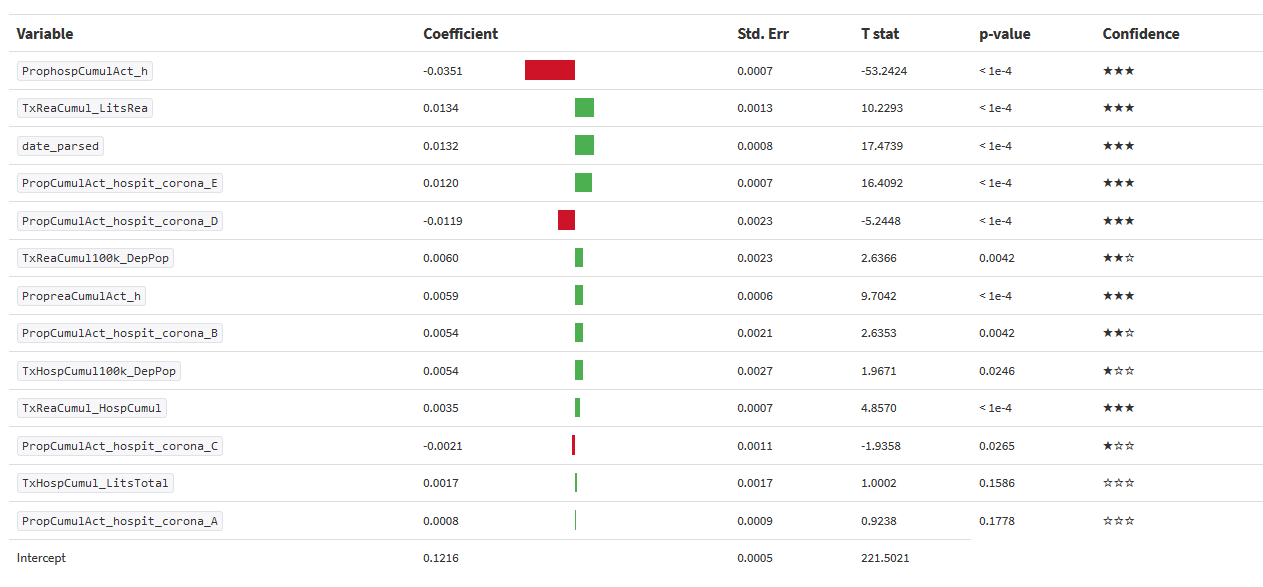
Le coefficient de la variable proportion d’hommes hospitalisés est négatif ce qui peut paraitre curieux, sachant que la proportion de décès chez les hommes est plus importante. Cela voudrait-il dire que l’on hospitalise des cas moins graves pour les hommes que pour les femmes ? Ou en d’autres termes les hommes sont-ils plus douillets 🙂 ???
Sinon, encore une fois, le taux de saturation des lits de réanimation intervient comme facteur important.
Départements les plus peuplés :
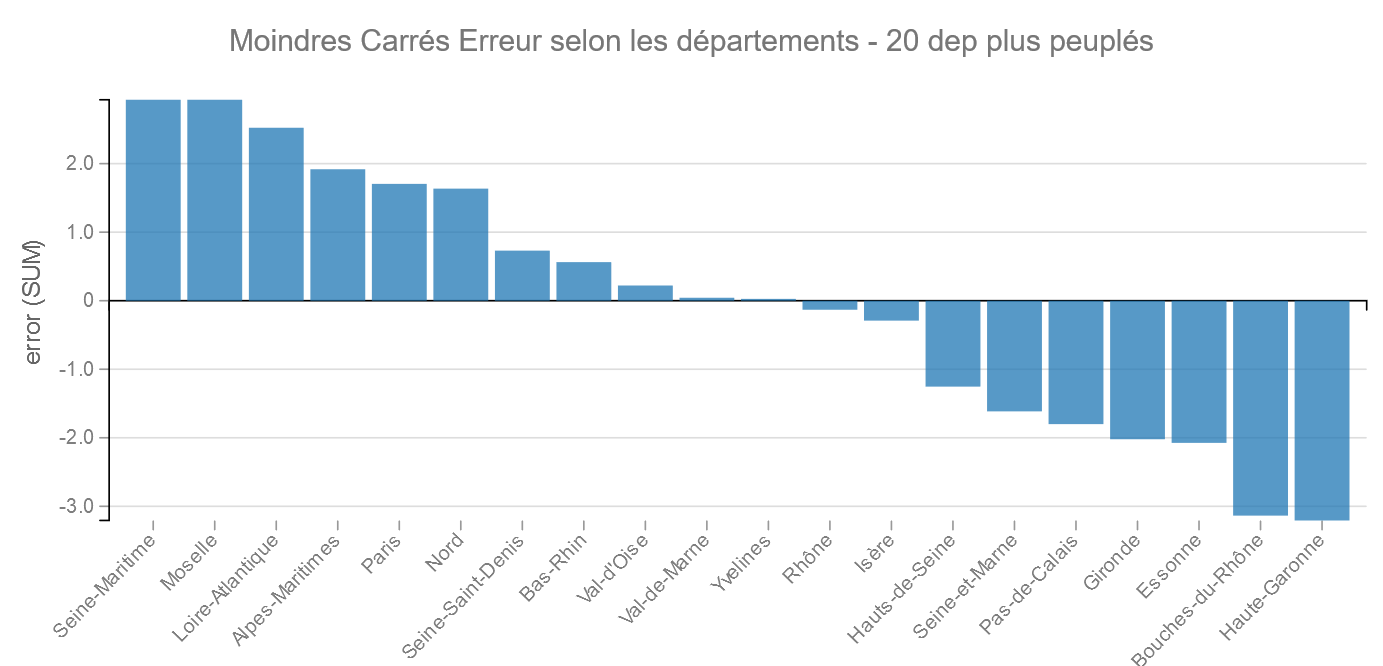
Comme précédemment, c’est la Haute-Garonne qui se place le mieux, juste avant les Bouches-du-Rhône.
Analyses via Machine Learning dans Dataiku : Ajout de données économiques
Nous nous sommes posé la question de savoir si les aspects économiques des départements pouvait avoir un effet sur le Taux de décès par hospitalisations.
Pour cela nous avons créé plusieurs variables :
- TxRecPrincProprio : la proportion de propriétaires de leur résidence principale dans le département,
- dep_revenufiscalmedianmoyen_2010 : le revenu fiscal moyen par département d’un foyer fiscal.
- RevenusIndividus : Revenus du foyer fiscal divisé par le nombre d’individu dans celui-ci
- TxChomage : Taux de chomage dans le département
- dep_ratio_imposable_2019 : le nombre de foyers fiscaux imposables vs tous les foyers fiscaux
Nous avons ensuite ajouté ces variables à notre modèle précédent. Il semble que l’ajout de ses informations économiques n’ajoute pas grand chose à la compréhension du modèle, voire comporte des informations contradictoires comme on peut le voir ci dessous dans les coefficients de régression pour le modèle des Moindre carrés.
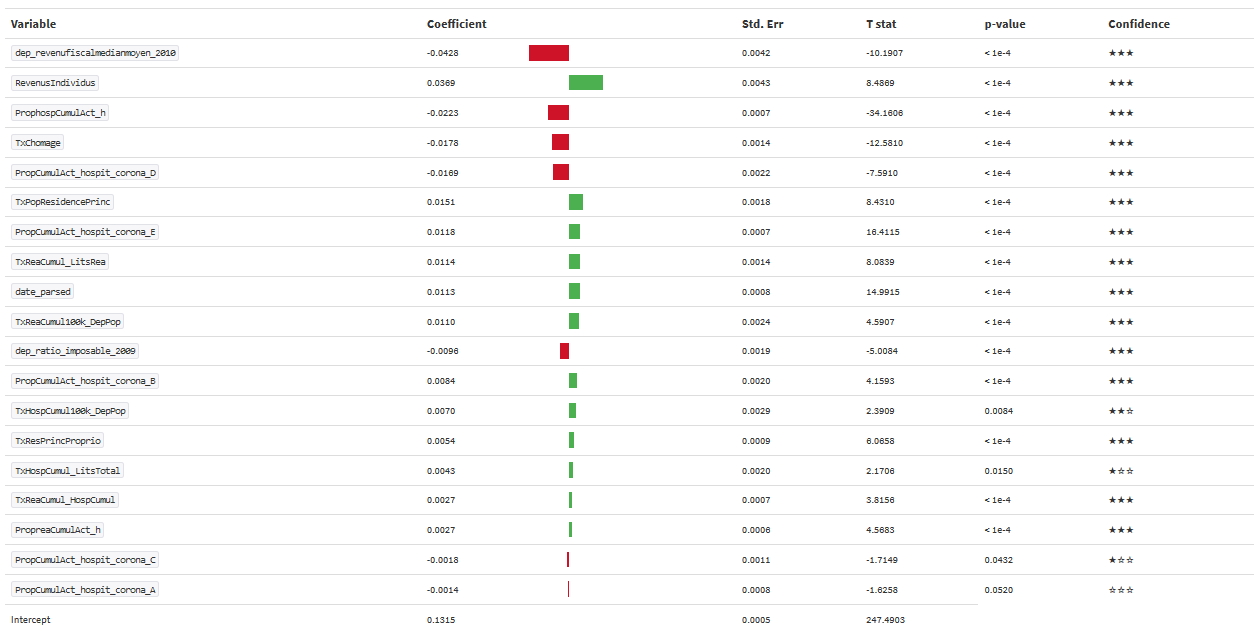
Les variables économiques sont probablement corrélées à d’autres variables comme par exemple l’âge (ou autres ?) ce qui apporte plus de confusion au modèle.
Malheureusement, ici l’information sur les groupes d’âge est très parcellaires.
Conclusion sur cette partie
Le fait de faire démarrer l’étude au 24 février plutôt qu’au 18 mars ne change pas grand chose aux résultats.
Il y a aussi un risque d’apporter des informations erronées, le cadrage entre les 2 fichiers étant construit à partir d’hypothèses pas forcément justes.
Les seules choses que l’on peut dire pour l’instant :
- Il n’y a pas de différence visible entre les départements riches et les département pauvres.
- Les facteurs liés à la saturation des hôpitaux sont ceux qui expliquent le mieux et le plus souvent les modèles
- Les Bouches du Rhône sont souvent bien positionnées par rapport à d’autres départements de tailles équivalentes.
Comme les données sur l’âge provenant des fichiers « sursaud » sont souvent parcellaires nous allons essayer par la suite de nous intéresser aux classes d’âge fournies par les fichiers « données-hospitalieres-classe-age… ». Malheureusement les données sont agrégées par Régions et non par département…
La suite de l’étude : https://www.anakeyn.com/2020/06/18/etude-donnees-hospitalieres-covid-19-iii/