Partager la publication "Recherche de facteurs SEO avec le Machine Learning (partie 3)"
Dans cet article nous allons nous consacrer au contenu et au contenu vs les mots clés ou expressions cibles.
Remarque : cet article est le troisième consacré à la recherche de facteurs SEO à partir du Machine Learning.
Dans un premier article nous avions récupéré des données de positionnement de Pages dans les SERPs de Google au moyen de l’API de Yooda Insight.
Puis ensuite, dans un second article, nous avions enrichi ces données avec des données techniques propres aux pages.
A chaque fois, nous avions utilisé ces données pour rechercher des facteurs SEO potentiels au moyen d’algorithme de marchine learning comme par exemple glm, naïve Bayes, random Forest ou XGBoost.
Cette fois nous allons enrichir les données avec des facteurs en rapport avec le contenu et le contenu des pages vs les mots clés sur lesquels se positionnent les pages.
De quoi aurons nous besoin ?
Logiciel R
Comme précédemment, merci de télécharger Le Logiciel R sur ce site https://cran.r-project.org/, ainsi que l’environnement de développement RStudio ici : https://www.rstudio.com/products/rstudio/download/, afin de pouvoir tester vous même le code source.
Fichiers précédents
Vous aurez aussi besoin du fichier de positionnement avec données techniques .csv sauvegardé précédemment. il contient 149355 observations. Vous pouvez le récupérer sous forme compressé .zip ici : YoodaTechDataKeywords.zip.
Ainsi que les répertoires et les fichiers de pages html créé précédemment et qui sont disponibles dans notre boutique à cette adresse : https://www.anakeyn.com/boutique/produit/script-r-facteurs-seo-et-ml-3/ téléchargez les fichiers sources et les fichiers au format .7z (Seven-Zip) et installez-les dans le même répertoire que votre projet R.
Récupération du contenu HTML
Dans cette partie nous allons récupérer le contenu des pages html pour créer des variables en rapport avec les balises (title, description, keywords, H1…, H6, strong, b, p, body) et le contenu ou non des mots clés cibles dans ces balises. par exemple voici quelques variables :
- title.size : taille de la balise titre en caractères.
- title.keyword.count : nombre de fois ou l’expression recherchée est trouvé titre.
- title.clean.keywordsSplit.count : nombre de fois ou les mots clés contenu dans l’expression recherchée sont trouvés dans le titre.
- allBody.clean.keyword.frequency : fréquence d’apparition de l’expression recherchée dans la page.
- …
Code Source
Vous pouvez copier/coller les morceaux de code source dans un script R pour les tester.
Vous pouvez aussi récupérer le code source gratuitement dans notre boutique à l’adresse : https://www.anakeyn.com/boutique/produit/script-r-facteurs-seo-et-ml-3/
Chargement des bibliothèques
Attention ! si vous n’avez pas installé certains packages dans votre environnement RStudio, vous devez dé-commenter ceux qui vous intéressent.
#
#
#load(".RData")
########################################################################
#### Recherche de facteurs SEO au moyen du machine Learning partie 3
########################################################################
#Dans cette 3 eme partie nous allons enrichir notre jeu de données avec des informations en rapport avec le contenu des
#pages html et des informations en fonction des Mots clés vs contenus.
#le contenu des pages est récupéré à partir des fichiers de pages html créées précédemment et qui se trouvent dans des
#répertoires par domaines
#### Chargement des bibliothèques utiles ##########################################
#Installer une fois
#install.packages("plyr") #une fois
#install.packages("XML") #une fois
#install.packages("xml2")
#install.packages("textclean")
#install.packages("stringr")
#install.packages("RCurl")
#install.packages("rvest")
#install.packages("stringr") #une fois
#install.packages("vtreat") #une fois
#install.packages("magrittr") #une fois
#install.packages("xgboost") #une fois
#install.packages("dplyr") #une fois
#install.packages("pROC") #une fois
#install.packages("qdap") #une fois
#install.packages("qdapTools") #une fois
#install.packages("tm") #une fois
#install.packages("ggplot2") #une fois
#install.packages("caret") #une fois
#install.packages("installr") #une fois
#Charger les bibliothèques
library(plyr) #pour join
library(XML)
library(xml2) #Notamment pour read_htm
library(textclean) #Notamment pour replace_html
library(stringr) #Notamment pour str_replace
library(RCurl) #notamment pour getURL
library(rvest) #pour html_nodes
library(stringi) #pour stri_trans_tolower (tolower de base génère une erreur)
library(vtreat) #pour retraitement préalable pour XGBoost
library(magrittr) #pour use_series
library(xgboost) #pour XGBoost
library(dplyr) #pour %>%
library(pROC) #pour ROC et AUC
library(qdap) #Replace_abbreviation
library(qdapTools) #rm_nchar_words
library(tm) #removePunctuation
library(ggplot2) #pour graphiques ggplot
library(caret) #notamment pour varImp glm
library(installr) #pour is.empty
###########################################################################################
Fonctions de récupération des pages HTML
Les fonctions suivantes permettent de récupérer et de nettoyer les données issues des pages html précédemment créées, et d’enrichir notre jeu de données « AllDataKeywords » avec les nouvelles variables.
#
#
#######################################################
### Fonctions pour récupération des données HTML
getFilepath <- function(domain, domain_id, obs_domain_id) {
######Adresse et lecture du fichier
DIR<-getwd() #Répertoire courant
foldername<-paste(domain,"-",domain_id ,sep = "")
path<-paste(DIR,"/", foldername ,sep = "")
filename<-paste(domain,"-",obs_domain_id,".html")
filepath<-paste(path,"/",filename, sep = "")
return(filepath)
}
removeAccents <- function(text) {
TheAccents = list( 'Š'='S', 'š'='s', 'Ž'='Z', 'ž'='z', 'À'='A', 'Á'='A', 'Â'='A', 'Ã'='A', 'Ä'='A', 'Å'='A', 'Æ'='A', 'Ç'='C', 'È'='E', 'É'='E',
'Ê'='E', 'Ë'='E', 'Ì'='I', 'Í'='I', 'Î'='I', 'Ï'='I', 'Ñ'='N', 'Ò'='O', 'Ó'='O', 'Ô'='O', 'Õ'='O', 'Ö'='O', 'Ø'='O', 'Ù'='U',
'Ú'='U', 'Û'='U', 'Ü'='U', 'Ý'='Y', 'Þ'='B', 'ß'='Ss', 'à'='a', 'á'='a', 'â'='a', 'ã'='a', 'ä'='a', 'å'='a', 'æ'='a', 'ç'='c',
'è'='e', 'é'='e', 'ê'='e', 'ë'='e', 'ì'='i', 'í'='i', 'î'='i', 'ï'='i', 'ð'='o', 'ñ'='n', 'ò'='o', 'ó'='o', 'ô'='o', 'õ'='o',
'ö'='o', 'ø'='o', 'ù'='u', 'ú'='u', 'û'='u', 'ý'='y', 'ý'='y', 'þ'='b', 'ÿ'='y' )
text <- chartr(paste(names(TheAccents), collapse=''),
paste(TheAccents, collapse=''),
text)
return(text)
}
# text <- iconv(text, to="ASCII//TRANSLIT//IGNORE") #cette méthode de conversion d'accents donne des erreurs.
myCleanText <- function(text) {
#on enlève les URLs
#text <- gsub("(f|ht)tp(s?)://\\S+", "", text)
#On remplace les caractères spéciaux par des blancs
#text <- gsub("[][!#$%()*,.:;<=>@^_|~.{}]", " ", text)
#On remplace les caractères spéciaux par des blancs (autre méthode)
text <- gsub("[[:punct:]]", " ", text)
#Replace abbreviations
#text <- replace_abbreviation(text)
# Replace contractions
#text <- replace_contraction(text)
# Replace symbols with words
#text <- replace_symbol(text)
#Enlève la ponctuation
text <- removePunctuation(text)
#Enlève les accents
text <- removeAccents(text)
#Enlève les nombres
text <- removeNumbers(text)
#Enlève les mots de 1 caractère #dans qdapTools
text <- rm_nchar_words(text, "1")
#bas de casse : en minuscule
text <- tolower(text)
#Premier nettoyage mots non significatifs avec stopwords("french") #si vous le souhaitez.
#text <- removeWords(text, stopwords("french") )
#Nettoyage mots non significatifs 2 : #si vous le souhaitez.
#Ici on récupère un fichier de stopwords sur le Net. "http://members.unine.ch/jacques.savoy/clef/frenchST.txt"
#stopwords_fr <- scan(file = "frenchST.txt", what = character()) #je l'ai sauvegardé sur mon dd
#text <- removeWords(text, stopwords_fr )
#Nettoyage mots non significatifs 3 : liste spécifique fournie par nos soins. #si vous le souhaitez.
#specificWords <- c("cest", "faut", "être", "comme", "non", "alors", "depuis", "fait", "quil")
#text <- removeWords(text, specificWords )
#Nettoyage des blancs
text <- stripWhitespace(text)
#/Nettoyage
} # /fin clean text
getHTMLContentData <- function(AllDataKeywords, Nmax) {
#Fichier au format AllDataKeyWords en entrée avec au moins :
#AllDataKeywords$domain[i] :
#AllDataKeywords$domain_id[i]
#AllDataKeywords$obs_domain_id[i]
#initialisation des nouvelles variables
AllDataKeywords$file_info.size <- 0
#Title
AllDataKeywords$title.size <- 0
AllDataKeywords$title.keyword.count <- 0
AllDataKeywords$title.clean.keyword.count <- 0
AllDataKeywords$title.clean.keywordsSplit.count <- 0
#description
AllDataKeywords$description.size <- 0
AllDataKeywords$description.keyword.count <- 0
AllDataKeywords$description.clean.keyword.count <- 0
AllDataKeywords$description.clean.keywordsSplit.count <- 0
#keywords
AllDataKeywords$keywords.size <- 0
AllDataKeywords$keywords.keyword.count <- 0
AllDataKeywords$keywords.clean.keyword.count <- 0
AllDataKeywords$keywords.clean.keywordsSplit.count <- 0
#allH1
AllDataKeywords$allH1.size <- 0
AllDataKeywords$allH1.keyword.count <- 0
AllDataKeywords$allH1.clean.keyword.count <- 0
AllDataKeywords$allH1.clean.keywordsSplit.count <- 0
#allH2
AllDataKeywords$allH2.size <- 0
AllDataKeywords$allH2.keyword.count <- 0
AllDataKeywords$allH2.clean.keyword.count <- 0
AllDataKeywords$allH2.clean.keywordsSplit.count <- 0
#allH3
AllDataKeywords$allH3.size <- 0
AllDataKeywords$allH3.keyword.count <- 0
AllDataKeywords$allH3.clean.keyword.count <- 0
AllDataKeywords$allH3.clean.keywordsSplit.count <- 0
#allH4
AllDataKeywords$allH4.size <- 0
AllDataKeywords$allH4.keyword.count <- 0
AllDataKeywords$allH4.clean.keyword.count <- 0
AllDataKeywords$allH4.clean.keywordsSplit.count <- 0
#allH5
AllDataKeywords$allH5.size <- 0
AllDataKeywords$allH5.keyword.count <- 0
AllDataKeywords$allH5.clean.keyword.count <- 0
AllDataKeywords$allH5.clean.keywordsSplit.count <- 0
#allH6
AllDataKeywords$allH6.size <- 0
AllDataKeywords$allH6.keyword.count <- 0
AllDataKeywords$allH6.clean.keyword.count <- 0
AllDataKeywords$allH6.clean.keywordsSplit.count <- 0
#allStrong
AllDataKeywords$allStrong.size <- 0
AllDataKeywords$allStrong.keyword.count <- 0
AllDataKeywords$allStrong.clean.keyword.count <- 0
AllDataKeywords$allStrong.clean.keywordsSplit.count <- 0
#allB
AllDataKeywords$allB.size <- 0
AllDataKeywords$allB.keyword.count <- 0
AllDataKeywords$allB.clean.keyword.count <- 0
AllDataKeywords$allB.clean.keywordsSplit.count <- 0
#allP
AllDataKeywords$allP.size <- 0
AllDataKeywords$allP.keyword.count <- 0
AllDataKeywords$allP.clean.keyword.count <- 0
AllDataKeywords$allP.clean.keywordsSplit.count <- 0
#allBody
AllDataKeywords$allBody.size <- 0
AllDataKeywords$allBody.keyword.count <- 0
AllDataKeywords$allBody.keyword.frequency <- 0
AllDataKeywords$allBody.clean.keyword.count <- 0
AllDataKeywords$allBody.clean.keyword.frequency <- 0
AllDataKeywords$allBody.clean.keywordsSplit.count <- 0
AllDataKeywords$allBody.clean.keywordsSplit.frequency <- 0
N <- nrow(AllDataKeywords) #nombre max d'occurences
#N <- 50 #pour l'instant
if (!is.na(Nmax)) N <- Nmax
#cat("N = ", N, "\n")
for (i in 1:N) {
cat("i = ", i, "\n")
domain <- AllDataKeywords$domain[i]
domain_id <- AllDataKeywords$domain_id[i]
obs_domain_id <- AllDataKeywords$obs_domain_id[i]
filepath <- getFilepath(domain, domain_id, obs_domain_id)
#str(filepath)
#cat(filepath,"\n")
keyword <- as.character(stringi::stri_trans_tolower(as.character(AllDataKeywords$keyword.keyword[i])))
#cat("keyword:", keyword,"\n")
keyword_clean <- myCleanText(keyword) #nettoyage des expressions de mots clés
if (is.empty(keyword_clean)) {
cat("keyword Clean Empty\n")
}
keyword_clean <- keyword_clean[1]
#cat("keyword Clean Class:", class(keyword_clean),"\n")
#cat("keyword Clean nchar:", nchar(keyword_clean),"\n")
keywordsSplit <- unlist(strsplit(keyword_clean, " ")) #séparation des mots clés.
#cat("keywordsSplit:", keywordsSplit,"\n")
#####On vérifie que le fichier existe :
if (file.exists(filepath)) {
#cat("File exists\n")
#infomation sur le fichier
#taille du fichier
AllDataKeywords$file_info.size[i] <- file.info(filepath)$size
#cat("File size",AllDataKeywords$file_info.size[i], "\n")
#AllDataKeywords$content_length[i] #a comparer avec la longueur quand on a récuopérée avec GET
#lecture du fichier dans une chaine de caractere
myHtml <- readChar(filepath, nchars=AllDataKeywords$file_info.size[i] )
#lecture du fichier dans un document xml
myReadHTML <- read_html(filepath) #pour meta descritpion et met keywords.
#str(myHtml)
nchar(myHtml) # pareil que AllDataKeywords$file_info.size[i]
myHtml <- gsub("[\r\n]", "", myHtml) #vire les retours à la ligne
myHtml <- gsub("[\t]", "", myHtml) #vire les tabulations
class(myHtml)
#Encoding(myHtml) <- as.character(AllDataKeywords$headers.content_type.encoding[i])
#nchar(myHtml) #voir si a diminué
#transformation de la chaine en HTMLInternalDocument #sert pour les extractions de balises
doc.html = htmlTreeParse(myHtml, useInternal = TRUE)
class(doc.html)
#######
#### Title (uniquement le premier)
title <- as.character(stringi::stri_trans_tolower(unlist(xpathApply(doc.html, "//title", xmlValue)[1]))) #on prend que le premier
title_clean <- myCleanText(title) #nettoyage titre.
if (length(title) > 0) {
AllDataKeywords$title.size[i] <- nchar(title) #taille brute du titre (tel qu'il apparait)
AllDataKeywords$title.keyword.count[i] <- stri_count_fixed(title, keyword) #décompte brute avant nettoyage
if (!is.empty(title_clean)) {
if (!is.empty(keyword_clean)) {
AllDataKeywords$title.clean.keyword.count[i] <- sum(str_count(title_clean, keyword_clean))
} # Fin (!is.empty(keyword_clean))
#Décompte mot à mot
AllDataKeywords$title.clean.keywordsSplit.count[i] <- sum(unlist(lapply(title_clean , str_count, keywordsSplit )))
} #Fin if (!is.empty(title_clean))
} #Fin (length(title) > 0)
#### Meta description
description <- myReadHTML %>% html_nodes(xpath = '//meta[@name="description"]') %>%
html_attr('content') %>% stringi::stri_trans_tolower()
description_clean <- myCleanText(description) #nettoyage description.
if (length(description) > 0) {
#str(description)
AllDataKeywords$description.size[i] <- nchar(description)
AllDataKeywords$description.keyword.count[i] <- stri_count_fixed(description, keyword)
if (length(description_clean) > 0) {
if (length(keyword_clean) > 0) AllDataKeywords$description.clean.keyword.count[i] <- sum(str_count(description_clean, keyword_clean)) #décompte après nettoyage
#Décompte mot à mot
AllDataKeywords$description.clean.keywordsSplit.count[i] <- sum(unlist(lapply(description_clean , str_count, keywordsSplit )))
} #Fin if (length(xxxx_clean) > 0)
}
#### Meta Keywords ##### de la page ne pas confondre avec le keyword ciblé sur Yooda
keywords <- myReadHTML %>% html_nodes(xpath = '//meta[@name="keywords"]') %>%
html_attr('content') %>% stringi::stri_trans_tolower()
keywords_clean <- myCleanText(keywords) #nettoyage keywords
if (length(keywords) > 0) {
AllDataKeywords$keywords.size[i] <- nchar(keywords)
AllDataKeywords$keywords.keyword.count[i] <- stri_count_fixed(keywords, keyword)
if (length(keywords_clean) > 0) {
if (length(keyword_clean) > 0) AllDataKeywords$keywords.clean.keyword.count[i] <- sum(str_count(keywords_clean, keyword_clean)) #décompte après nettoyage
#Décompte mot à mot
AllDataKeywords$keywords.clean.keywordsSplit.count[i] <- sum(unlist(lapply(keywords_clean , str_count, keywordsSplit )))
} #Fin if (length(xxxx_clean) > 0)
# cat("keywords =", keywords, "\n")
}
###### H1 #######
h1 <- stringi::stri_trans_tolower(unlist(xpathApply(doc.html, "//h1", xmlValue)))
if (length(h1) > 0) {
allH1 <- trimws(replace_white(x = paste(h1, collapse = " "), " "))
allH1_clean <- myCleanText(allH1)
AllDataKeywords$allH1.size[i] <- nchar(allH1)
AllDataKeywords$allH1.keyword.count[i] <- stri_count_fixed(allH1, keyword)
if (length(allH1_clean) > 0) {
if (length(keyword_clean) > 0) AllDataKeywords$allH1.clean.keyword.count[i] <- sum(str_count(allH1_clean, keyword_clean)) #décompte après nettoyage
#Décompte mot à mot
AllDataKeywords$allH1.clean.keywordsSplit.count[i] <- sum(unlist(lapply(allH1_clean , str_count, keywordsSplit )))
} #Fin if (length(xxxx_clean) > 0)
}
###### H2 #######
h2 <- stringi::stri_trans_tolower(unlist(xpathApply(doc.html, "//h2", xmlValue)))
if (length(h2) > 0) {
allH2 <- trimws(replace_white(x = paste(h2, collapse = " "), " "))
allH2_clean <- myCleanText(allH2)
AllDataKeywords$allH2.size[i] <- nchar(allH2)
AllDataKeywords$allH2.keyword.count[i] <- stri_count_fixed(allH2, keyword)
if (length(allH2_clean) > 0) {
if (length(keyword_clean) > 0) AllDataKeywords$allH2.clean.keyword.count[i] <- sum(str_count(allH2_clean, keyword_clean)) #décompte après nettoyage
#Décompte mot à mot
AllDataKeywords$allH2.clean.keywordsSplit.count[i] <- sum(unlist(lapply(allH2_clean , str_count, keywordsSplit )))
} #Fin if (length(xxxx_clean) > 0)
}
###### H3 #######
h3 <- stringi::stri_trans_tolower(unlist(xpathApply(doc.html, "//h3", xmlValue)))
if (length(h3) > 0) {
allH3 <- trimws(replace_white(x = paste(h3, collapse = " "), " "))
allH3_clean <- myCleanText(allH3)
AllDataKeywords$allH3.size[i] <- nchar(allH3)
AllDataKeywords$allH3.keyword.count[i] <- stri_count_fixed(allH3, keyword)
if (length(allH3_clean) > 0) {
if (length(keyword_clean) > 0) AllDataKeywords$allH3.clean.keyword.count[i] <- sum(str_count(allH3_clean, keyword_clean)) #décompte après nettoyage
#Décompte mot à mot
AllDataKeywords$allH3.clean.keywordsSplit.count[i] <- sum(unlist(lapply(allH3_clean , str_count, keywordsSplit )))
} #Fin if (length(xxxx_clean) > 0)
}
###### H4 #######
h4 <- stringi::stri_trans_tolower(unlist(xpathApply(doc.html, "//h4", xmlValue)))
if (length(h4) > 0) {
allH4 <- trimws(replace_white(x = paste(h4, collapse = " "), " "))
allH4_clean <- myCleanText(allH4)
AllDataKeywords$allH4.size[i] <- nchar(allH4)
AllDataKeywords$allH4.keyword.count[i] <- stri_count_fixed(allH4, keyword)
if (length(allH4_clean) > 0) {
if (length(keyword_clean) > 0) AllDataKeywords$allH4.clean.keyword.count[i] <- sum(str_count(allH4_clean, keyword_clean)) #décompte après nettoyage
#Décompte mot à mot
AllDataKeywords$allH4.clean.keywordsSplit.count[i] <- sum(unlist(lapply(allH4_clean , str_count, keywordsSplit )))
} #Fin if (length(xxxx_clean) > 0)
}
###### H5 #######
h5 <- stringi::stri_trans_tolower(unlist(xpathApply(doc.html, "//h5", xmlValue)))
if (length(h5) > 0) {
allH5 <- trimws(replace_white(x = paste(h5, collapse = " "), " "))
allH5_clean <- myCleanText(allH5)
AllDataKeywords$allH5.size[i] <- nchar(allH5)
AllDataKeywords$allH5.keyword.count[i] <- stri_count_fixed(allH5, keyword)
if (length(allH5_clean) > 0) {
if (length(keyword_clean) > 0) AllDataKeywords$allH5.clean.keyword.count[i] <- sum(str_count(allH5_clean, keyword_clean)) #décompte après nettoyage
#Décompte mot à mot
AllDataKeywords$allH5.clean.keywordsSplit.count[i] <- sum(unlist(lapply(allH5_clean , str_count, keywordsSplit )))
} #Fin if (length(xxxx_clean) > 0)
}
###### H6 #######
h6 <- stringi::stri_trans_tolower(unlist(xpathApply(doc.html, "//h6", xmlValue)))
if (length(h6) > 0) {
allH6 <- trimws(replace_white(x = paste(h6, collapse = " "), " "))
allH6_clean <- myCleanText(allH6)
AllDataKeywords$allH6.size[i] <- nchar(allH6)
AllDataKeywords$allH6.keyword.count[i] <- stri_count_fixed(allH6, keyword)
if (length(allH6_clean) > 0) {
if (length(keyword_clean) > 0) AllDataKeywords$allH6.clean.keyword.count[i] <- sum(str_count(allH6_clean, keyword_clean)) #décompte après nettoyage
#Décompte mot à mot
AllDataKeywords$allH6.clean.keywordsSplit.count[i] <- sum(unlist(lapply(allH6_clean , str_count, keywordsSplit )))
} #Fin if (length(xxxx_clean) > 0)
}
#### strong #####
strong <- stringi::stri_trans_tolower(unlist(xpathApply(doc.html, "//strong", xmlValue)))
if (length(strong) > 0) {
allStrong <- trimws(replace_white(x = paste(strong, collapse = " "), " "))
allStrong_clean <- myCleanText(allStrong)
AllDataKeywords$allStrong.size[i] <- nchar(allStrong)
AllDataKeywords$allStrong.keyword.count[i] <- stri_count_fixed(allStrong, keyword)
if (length(allStrong_clean) > 0) {
if (length(keyword_clean) > 0) AllDataKeywords$allStrong.clean.keyword.count[i] <- sum(str_count(allStrong_clean, keyword_clean)) #décompte après nettoyage
#Décompte mot à mot
AllDataKeywords$allStrong.clean.keywordsSplit.count[i] <- sum(unlist(lapply(allStrong_clean , str_count, keywordsSplit )))
} #Fin if (length(xxxx_clean) > 0)
}
#### b : bold #####
b <- stringi::stri_trans_tolower(unlist(xpathApply(doc.html, "//b", xmlValue)))
if (length(b) > 0) {
allB <- trimws(replace_white(x = paste(b, collapse = " "), " "))
allB_clean <- myCleanText(allB)
AllDataKeywords$allB.size[i] <- nchar(allB)
AllDataKeywords$allB.keyword.count[i] <- stri_count_fixed(allB, keyword)
if (length(allB_clean) > 0) {
if (length(keyword_clean) > 0) AllDataKeywords$allB.clean.keyword.count[i] <- sum(str_count(allB_clean, keyword_clean)) #décompte après nettoyage
#Décompte mot à mot
AllDataKeywords$allB.clean.keywordsSplit.count[i] <- sum(unlist(lapply(allB_clean , str_count, keywordsSplit )))
} #Fin if (length(xxxx_clean) > 0)
}
#### p #####
p <- stringi::stri_trans_tolower(unlist(xpathApply(doc.html, "//p", xmlValue)))
if (length(p) > 0) {
allP <- trimws(replace_white(x = paste(p, collapse = " "), " "))
allP_clean <- myCleanText(allP)
AllDataKeywords$allP.size[i] <- nchar(allP)
AllDataKeywords$allP.keyword.count[i] <- stri_count_fixed(allP, keyword)
if (length(allP_clean) > 0) {
if (length(keyword_clean) > 0) AllDataKeywords$allP.clean.keyword.count[i] <- sum(str_count(allP_clean, keyword_clean)) #décompte après nettoyage
#Décompte mot à mot
AllDataKeywords$allP.clean.keywordsSplit.count[i] <- sum(unlist(lapply(allP_clean , str_count, keywordsSplit )))
} #Fin if (length(xxxx_clean) > 0
}
#### body #####
body <- stringi::stri_trans_tolower(unlist(xpathApply(doc.html, "//body", xmlValue)))
if (length(body) > 0) {
allBody <- trimws(replace_white(x = paste(body, collapse = " "), " "))
allBody_clean <- myCleanText(allBody)
AllDataKeywords$allBody.size[i] <- nchar(allBody)
AllDataKeywords$allBody.keyword.count[i] <- stri_count_fixed(allBody, keyword)
wordCount <- lengths(gregexpr("\\W+", allBody)) + 1 #Eviter le 0 : division !!
#cat("Word in Body", wordCount, "\n")
AllDataKeywords$allBody.keyword.frequency[i] <- AllDataKeywords$allBody.keyword.count[i] / wordCount
# cat("Frequence:", AllDataKeywords$allBody.keyword.frequency[i],"\n")
if (length(allBody_clean) > 0) {
if (length(keyword_clean) > 0) AllDataKeywords$allBody.clean.keyword.count[i] <- sum(str_count(allBody_clean, keyword_clean)) #décompte après nettoyage
wordCount_clean <- lengths(gregexpr("\\W+", allBody_clean)) + 1 #Eviter le 0 : division !!
#cat("Word in Body clean", wordCount_clean, "\n")
AllDataKeywords$allBody.clean.keyword.frequency[i] <- AllDataKeywords$allBody.clean.keyword.count[i] / wordCount_clean
#Décompte mot à mot
AllDataKeywords$allBody.clean.keywordsSplit.count[i] <- sum(unlist(lapply(allBody_clean , str_count, keywordsSplit )))
AllDataKeywords$allBody.clean.keywordsSplit.frequency[i] <- AllDataKeywords$allBody.clean.keywordsSplit.count[i] / wordCount_clean
#cat("keywordsSplit frequency", AllDataKeywords$allBody.clean.keywordsSplit.frequency[i], "\n")
#cat("classe keywordsSplit frequency", class(AllDataKeywords$allBody.clean.keywordsSplit.frequency[i]), "\n")
}
}
} #Fin file exists
} #fin for (i in 1:N)
return(AllDataKeywords)
} #Fin getHTMLContentData
Phase de récupération des données
Dans cette partie nous réalisons effectivement l’enrichissement des données. Les données sont récupérées à partir du fichier YoodaTechDataKeywords.csv qui doit se trouver dans le répertoire courant. Les fichiers de pages HTML doivent se trouver dans des sous répertoires (un par site). par exemple le répertoire « bazar-bio.fr-961671 » contient toutes les pages HTML que l’on a récupérées du site bazar-bio.fr.
Cette opération étant lourde en mémoire nous avons éclaté le jeu de données de 149355 enregistrements en plusieurs jeux de données de 5000 enregistrements que nous sauvegardons au fur et à mesure sur le disque dur.
#
#
#######################################################
#### Récupération des données des fichiers HTML des pages
memory.limit()
memory.limit(size=80000) #augmentation de la mémoire j'ai 12 GO donc 8 pour R et 4 pour tout le reste ....
gc()
#Chargement du fichiers des observations précédentes :
AllDataKeywords <- read.csv2( file = "YoodaTechDataKeywords.csv") #données 149355
str(AllDataKeywords, list.len=255) #verif
#on va spliter le dataframe des observations à enrichir s'il est > 5000 obs. (pb de mémoire)
chunk <- 5000
n <- nrow(AllDataKeywords)
r <- rep(1:ceiling(n/chunk),each=chunk)[1:n]
if (n > chunk) {
ListObsToRead <- split(AllDataKeywords,r)
} else {
ListObsToRead <- list(AllDataKeywords)
}
##############
#str(ListObsToRead)
rm(AllDataKeywords) #liberation de memoire
Debut <- 1
Fin <- length(ListObsToRead)
#Fin <- 1
for(numList in Debut:Fin ) {
gc() #vider la mémoire
ObsRed <- getHTMLContentData(AllDataKeywords = ListObsToRead[[numList]], Nmax = nrow( ListObsToRead[[numList]])) #on limite à 5000 pour préserver la mémoire
#on sauvegarde les UrlsCrawled au fur et à mesure sur le disque dur
MyFileName <- paste("ObsRed", "-",numList,".csv", sep="")
write.csv2(ObsRed, file = MyFileName, row.names = FALSE) #Ecriture du fichier .csv avec séparateur ";" sans numéro de ligne.
gc() #vider la mémoire
}
######liberation de memoire
rm(ListObsToRead)
rm(ObsRed)
rm(AllDataKeywords)
#Recupération des données d'URls en une seule data.frame à partir des fichiers.
#lecture des fichiers de positionnements par domaines
ObsRedFiles <- list.files(path = ".", pattern = "ObsRed-.*\\.csv$")
AllObsRedFiles <- lapply(ObsRedFiles,function(i){
read.csv2(i, check.names=FALSE, header=TRUE, sep=";", quote="\"")
})
class(AllObsRedFiles) #C'est une liste
#str(AllObsRedFiles) #verif
AllDataKeywords <- do.call(rbind, AllObsRedFiles) #transformation en data.frame
str(AllDataKeywords, list.len=255) #verif
rm(AllObsRedFiles) #pour faire de la place mémoire
#Sauvegarde
write.csv2(AllDataKeywords, file = "YoodaTechContentDataKeywords.csv", row.names = FALSE)
Sélection des données
Ici nous allons sélectionner les variables .
Si vous n’avez pas réussi à créer le fichier précédent vous pouvez le récupérer sur notre compte GitHub. et le dézipper dans le répertoire courant.
Cette fois-ci, pour changer, nous allons rechercher les facteurs explicatifs pour les pages positionnées en première place (istop1pos) dans les résultats de Google. Pour cela nous allons sélectionner 96 variables potentielles.
#
#
#############################################################################
### Machine Learning sur les données intéressantes
#############################################################################
#############################################################################
### Creation du fichier de données à tester, de train et de test
#### Sélection des variables
#############################################################################
AllDataKeywords <- read.csv2( file = "YoodaTechContentDataKeywords.csv") #données 149355
AllDataKeywords <- AllDataKeywords[which(AllDataKeywords$file_info.size>0 ),]
str(AllDataKeywords, list.len=255) #forte baisse plus que 46883 observations
#on sauvagarde les données électionnées 46883 lignes.
write.csv2(AllDataKeywords, file = "YoodaTechContentDataKeywordsSelect.csv", row.names = FALSE) #données 46883
########################################################################################################
AllDataKeywords <- read.csv2( file = "YoodaTechContentDataKeywordsSelect.csv") #données 46883
#on prend x enregistrements si 46883 ça plante
#AllDataKeywords <- dplyr::sample_n(AllDataKeywords, size = 25000) #on prend x enregistrements (au lieu de ~ 46883)
######################
str(AllDataKeywords) #verif des donnnées disponibles.
# Variable à expliquer
(outcome <- "istop1pos") #utilisé avec XGBoost
# Variables explicatives #utilisé avec XGBoost
(vars <- c("kwindomain", "kwinurl", "ishttps", "isSSLEV", "urlnchar", "urlslashcount",
"headers.content_type.encoding", "headers.connection", "headers.server.family",
"headers.set.cookie.domain.provided",
"headers.set.cookie.path.provided", "headers.set.cookie.httponly.provided",
"headers.set.cookie.secure.provided", "headers.set.cookie.max_age",
"headers.transfer_encoding.provided", "headers.vary.accept_encoding",
"headers.vary.user_agent", "headers.vary.cookie", "headers.vary.host",
"headers.accept_ranges.bytes", "headers.cache_control.max_age.value",
"all_headers.status", "content_length", "times.redirect", "times.namelookup", "times.connect",
"times.pretransfer", "times.starttransfer", "times.total", "NbIntLinks", "NbExtLinks",
"file_info.size",
"title.size", "title.keyword.count", "title.clean.keyword.count", "title.clean.keywordsSplit.count",
"description.size", "description.keyword.count", "description.clean.keyword.count", "description.clean.keywordsSplit.count",
"keywords.size", "keywords.keyword.count", "keywords.clean.keyword.count", "keywords.clean.keywordsSplit.count",
"allH1.size", "allH1.keyword.count", "allH1.clean.keyword.count", "allH1.clean.keywordsSplit.count",
"allH2.size", "allH2.keyword.count", "allH2.clean.keyword.count", "allH2.clean.keywordsSplit.count",
"allH3.size", "allH3.keyword.count", "allH3.clean.keyword.count", "allH3.clean.keywordsSplit.count",
"allH4.size", "allH4.keyword.count", "allH4.clean.keyword.count", "allH4.clean.keywordsSplit.count",
"allH5.size", "allH5.keyword.count", "allH5.clean.keyword.count", "allH5.clean.keywordsSplit.count",
"allH6.size", "allH6.keyword.count", "allH6.clean.keyword.count", "allH6.clean.keywordsSplit.count",
"allStrong.size", "allStrong.keyword.count", "allStrong.clean.keyword.count", "allStrong.clean.keywordsSplit.count",
"allB.size", "allB.keyword.count", "allB.clean.keyword.count", "allB.clean.keywordsSplit.count",
"allP.size", "allP.keyword.count", "allP.clean.keyword.count", "allP.clean.keywordsSplit.count",
"allBody.size", "allBody.keyword.count", "allBody.keyword.frequency", "allBody.clean.keyword.count",
"allBody.clean.keyword.frequency", "allBody.clean.keywordsSplit.count", "allBody.clean.keywordsSplit.frequency"))
##############################################################################
# Données à étudier
##############################################################################
#Selection des variables.
Urlcoltokeep <- c(outcome, vars)
UrlDataKeywords <- AllDataKeywords[, Urlcoltokeep]
str(AllDataKeywords) #verif
str(UrlDataKeywords) #verif
#Decoupage en train et test
## 70% of the sample size
smp_size <- floor(0.70 * nrow(UrlDataKeywords))
## set the seed to make your partition reproductible
set.seed(12345)
train_ind <- sample(seq_len(nrow(UrlDataKeywords)), size = smp_size)
train <- UrlDataKeywords[train_ind, ]
test <- UrlDataKeywords[-train_ind, ]
str(train) #verif
str(test) #verif
#liberation demémoire
rm(Urlcoltokeep)
rm(UrlDataKeywords)
#rm(AllDataKeywords)
Modèle XGBoost
Ici nous faisons travailler l’algorithme XGBoost à proprement parlé.
#
#
#######################################################################################
# XGBoost sur istop1pos
########################################################################################
#Traitements préalables des données pour être utilisées par XGBoost
# Création d'un "plan de traitement" à partir de train (données d'entrainement)
# ici le système va créer des variables supplémentaires booléennes pour différents niveaux de facteurs dans les
# variables originales. one hot encoding
treatplan <- designTreatmentsZ(train, vars, verbose = TRUE)
#str(treatplan)
# On récupère les variables "clean" et "lev" du scoreFrame : treatplan$scoreFrame
(newvars <- treatplan %>%
use_series(scoreFrame) %>%
filter(code %in% c("clean","lev")) %>% # get the rows you care about
use_series(varName)) # get the varName column
# Preparation des données d'entrainement à partir du plan de traitement créé précédemment
train.treat <- prepare(treatmentplan = treatplan, dframe = train , varRestriction = newvars)
# Preparation des données de test à partir du plan de traitement créé précédemment
test.treat <- prepare(treatmentplan = treatplan, dframe = test, varRestriction = newvars)
str(train.treat)
str(test.treat)
# on commence par faire tourner xgb.cv pour déterminer le nombre d'arbres optimal.
cv <- xgb.cv(data = as.matrix(train.treat),
label = train$istop1pos,
nrounds = 1000,
nfold = 5,
objective = "binary:logistic",
#booster = "gblinear",
#monotone_constraints = "(0,1,1,0)",
eta = 0.3,
max_depth = 6,
early_stopping_rounds = 100,
verbose = 1 # 0=silent
)
#
#str(cv)
#pour regression linéaire objective = "reg:linear",
#pour binaire objective = "binary:logistic",
# Get the evaluation log
elog <- cv$evaluation_log
str(elog)
# Determinatiion du nombre d'arbres qui minimise l'erreur sur le jeu de train et le jeu de test
(Twotreesvalue <- elog %>%
summarize(ntrees.train = which.min(train_error_mean), # find the index of min(train_rmse_mean)
ntrees.test = which.min(test_error_mean)) ) # find the index of min(test_rmse_mean)
#on prend le plus petit des 2
ntrees = min(Twotreesvalue$ntrees.train, Twotreesvalue$ntrees.test)
# The number of trees to use, as determined by xgb.cv
ntrees #53
# Run xgboost
xgbmod <- xgboost(data = as.matrix(train.treat), # training data as a matrix
label = train$istop1pos, # column of outcomes
nrounds = ntrees, # number of trees to build
objective = "binary:logistic", # objective
#booster = "gblinear",
#monotone_constraints = "(0,1,1,0)",
eta = 0.3,
depth = 6,
verbose = 1 # affichage ou non
)
#Predictions
pred.xgbmod <-predict(xgbmod, as.matrix(test.treat))
#Matrice de Confusion
table(round(pred.xgbmod) , test$istop1pos)
mean(round(pred.xgbmod) == test$istop1pos) ### 0.7829364
#ROC et AUC
ROC <- roc(test$istop1pos, pred.xgbmod)
AUC <- auc(ROC) #0.8081
# Plot the ROC curve
plot(ROC, col = "blue")
text(0.5,0.5,paste("AUC = ",format(AUC, digits=5, scientific=FALSE)))
text(0.6, 1, "ROC-AUC Modèle XGBoost Données Yooda \n Techniques Contenu Pages", col="red", cex=0.7)
#importance #c'est le gain qui nous intéresse !
(importance <- xgb.importance(feature_names = colnames(x = train.treat), model = xgbmod))
#sauvegarde
write.csv2(importance , file = "importance.csv", row.names = FALSE)
#Arbre
(monArbre <- xgb.model.dt.tree(feature_names = colnames(x = train.treat), model = xgbmod))
monArbre$Split <- as.numeric(monArbre$Split)
write.csv2(monArbre , file = "monArbre.csv", row.names = FALSE)
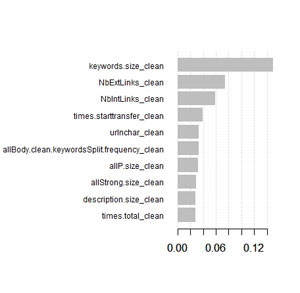
(xgb.plot.importance(importance_matrix = importance, top_n = 10, left_margin=14))
Voici ce que nous donne la courbe ROC-AUC :
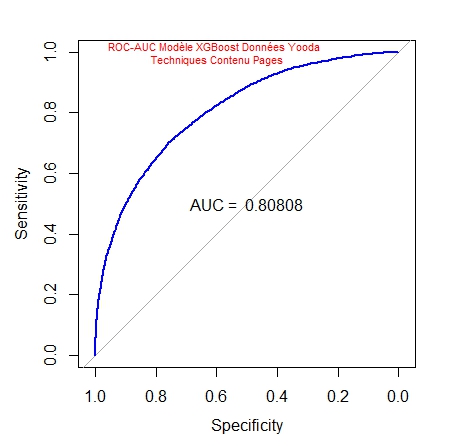
L’AUC (Area under the curve) est ici de 0,80808 par rapport à 0,78442, précédemment. Nous avons encore amélioré la validité du modèle et ce malgré une perte importante d’observations : 46883 au lieu de 149355.
Quelles sont les variables importantes :
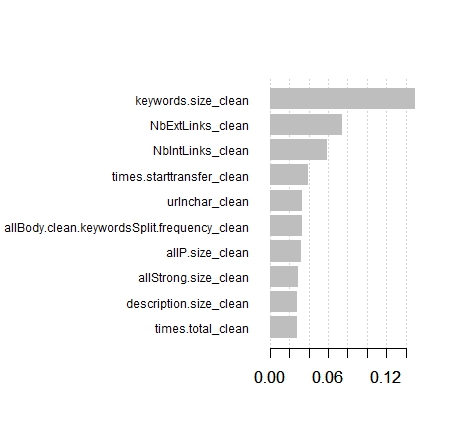
Oups ! la variable qui explique le mieux le modèle est la taille du contenu de la balise Keywords : « keywords.size_clean » . Or cela fait plusieurs années que Google nous dit que cette balise n’est plus utilisée !!!!!
Sens de l’importance des variables
investiguons plus avant pour voir dans quels sens les variables influencent le modèle.
Ici testons plus particulièrement keywords.size_clean.
# # #Dans quel sens ???? train.treat.istop1pos <- cbind(train.treat, istop1pos = train$istop1pos) train.treat.istop1pos.true <- train.treat.istop1pos[which(train.treat.istop1pos$istop1pos == TRUE),] train.treat.istop1pos.false<- train.treat.istop1pos[which(train.treat.istop1pos$istop1pos == FALSE),] summary(train.treat.istop1pos$keywords.size_clean) summary(train.treat.istop1pos.true$keywords.size_clean) summary(train.treat.istop1pos.false$keywords.size_clean) # ggplot(train.treat.istop1pos, aes(x=istop1pos, y=keywords.size_clean)) + geom_boxplot() #la tendance est que #plus la balise keywords est renseignée en moyenne plus la page est dans le top 1 !!! Ce qui va à l'inverse de la littérature #sur le seo #voyons avec test !! Idem que précédent test.treat.istop1pos <- cbind(test.treat, istop1pos = test$istop1pos) test.treat.istop1pos.true <- test.treat.istop1pos[which(test.treat.istop1pos$istop1pos == TRUE),] test.treat.istop1pos.false<- test.treat.istop1pos[which(test.treat.istop1pos$istop1pos == FALSE),] summary(test.treat.istop1pos$keywords.size_clean) summary(test.treat.istop1pos.true$keywords.size_clean) summary(test.treat.istop1pos.false$keywords.size_clean) # ggplot(test.treat.istop1pos, aes(x=istop1pos, y=keywords.size_clean)) + geom_boxplot()
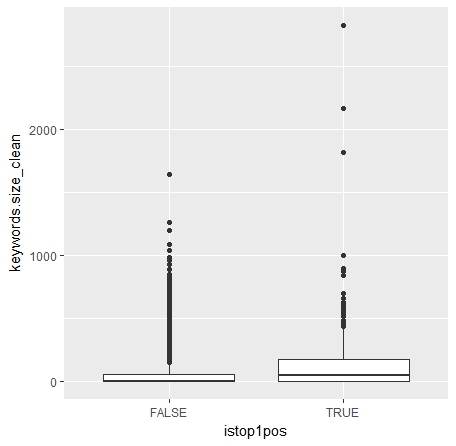
Boites de dispersions :
Sur le jeu d’entrainement :
Sur le jeu de test :
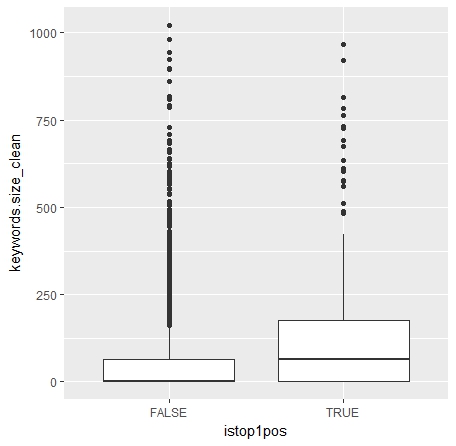
Comme on peut le voir sur les boites de dispersion (et aussi sur les données fournies par summary()) il semble que plus la balise keywords est renseignée plus la probabilité d’être sur une page positionnée en 1 est élevée…
Autre méthode
Cette méthode permet de déterminer les facteurs qui influencent positivement ou négativement une prédiction.
#
#
###################################################################
#Autre méthode de mesure d'importance
###################################################################
###################################################################
#explications : https://amunategui.github.io/actionable-instights/index.html
#Predictions (rappel)
pred.xgbmod <-predict(xgbmod, as.matrix(test.treat))
number_of_factors <- 3 #nombre de facteurs importants positifs ou négatifs pour chaque observation
# strongest factors
feature_names <- names(train.treat)
new_preds <- c()
for (feature in feature_names) {
#cat("feature",feature,"\n")
test.treat_trsf <- test.treat
# neutralize feature to population mean
if (sum(is.na(train.treat[,feature])) > (nrow(train.treat)/2)) {
cat("feature NA",feature,"\n")
test.treat_trsf[,feature] <- NA
} else {
cat("feature OK",feature,"\n")
test.treat_trsf[,feature] <- mean(train.treat[,feature], na.rm = TRUE)
}
predictions <- predict(object=xgbmod, data.matrix(test.treat_trsf), #calcul prédictions "moyennes" sur test.treat_trsf
outputmargin=FALSE, missing=NaN)
new_preds <- cbind(new_preds, pred.xgbmod - predictions) #différence des predictions / moyenne
} #/for (feature in vars)
#affichage de qq new_preds par caractéristiques.
for (i in 1:ncol(new_preds)) {
cat(feature_names[i], ": ")
cat(new_preds[1:10,i], "\n")
}
positive_features <- c()
negative_features <- c()
feature_effect_df <- data.frame(new_preds)
names(feature_effect_df) <- c(feature_names)
for (pred_id in seq(nrow(feature_effect_df))) {
cat("pred_id",pred_id,"\n")
vector_vals <- feature_effect_df[pred_id,]
vector_vals <- vector_vals[,!is.na(vector_vals)]
positive_features <- rbind(positive_features,
c(colnames(vector_vals)[order(vector_vals,
decreasing=TRUE)][1:number_of_factors]))
negative_features <- rbind(negative_features,
c(colnames(vector_vals)[order(vector_vals,
decreasing=FALSE)][1:number_of_factors]))
}
#construction de la dataframe des facteurs pos et neg pour chaque prediction
positive_features <- data.frame(positive_features)
names(positive_features) <- paste0('Pos_', names(positive_features))
negative_features <- data.frame(negative_features)
names(negative_features) <- paste0('Neg_', names(negative_features))
preds <- data.frame(pred.xgbmod, positive_features, negative_features)
preds <- preds[order(preds$pred.xgbmod, decreasing=TRUE),]
str(preds)
head(preds, n=20) #visualisation
tail(preds, n=20) #visualisation
#graphique des 1er facteurs les plus rencontrés en positif au dessus de la moyenne.
predsTRUE <- preds[which(preds$pred.xgbmod>0.5),]
#str(predsTRUE) #verif
#tail(predsTRUE) #verif
count.Pos_X1 <- plyr::count(predsTRUE$Pos_X1)
str(count.Pos_X1)
count.Pos_X1$x <- as.character(count.Pos_X1$x)
order.count.Pos_X1 <- count.Pos_X1[order(count.Pos_X1$freq, decreasing=TRUE), ]
ggplot(data = order.count.Pos_X1[1:10,], aes(x=reorder(x, freq), y=freq )) +geom_bar(stat="identity") + coord_flip()
Le graphique suivant indique les 10 facteurs qui apparaissent le plus souvent en position 1 pour expliquer positivement par rapport à la moyenne une prédiction vrai de positionnement sur la première place des résultats de Google (ouf!!!).
En d’autres termes et par exemple : le fait d’avoir une taille de balise « keywords » plus grande que la moyenne des observations semble indiquer que la probabilité que l’on ait une page en position 1 dans les SERPs de Google est plus élevée.
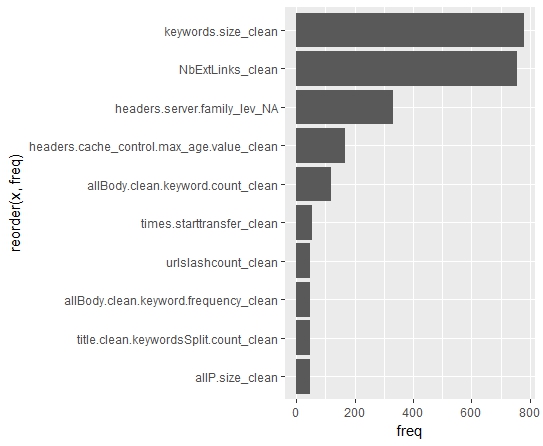
Comme on l’a vu précédemment cette tendance est contraire à l’avis des experts et aux indications de Google.
Conclusion
A ce stade il apparait que certaines informations fournies par le Machine Learning aillent en contradiction avec la littérature habituelle sur le SEO.
Soit tous les experts se sont trompés et Google nous a trompé depuis plusieurs années (ce qui est peu probable, quoique pour Google … 🙂 c’est moins sûr…).
Soit les variables que nous avons trouvées ne sont pas des variables explicatives mais des variables corrélées dans notre cas avec d’autres variables explicatives cachées.
Soit le modèle est sur-ajusté aux données que nous avons.
Soit encore un facteur qui nous échappe pour l’instant.
Il conviendra d’être prudent et de continuer à tester d’autres variables potentielles.
Merci pour votre avis en commentaires,
Pierre
BartekPL
21 mai 2018 at 18 h 05 minUnfortunately i can’t read it in this language, could you describe what is doing your script? I’m very interest
BartekPL
21 mai 2018 at 21 h 00 minnevermind, i translated article with google.
Keywords.size – could give example of it
nbextlinks – backlinks?;)
headers.server.family – i don’t have any idea what is it
headers cache control max age – age of domain
allBody keyword count – frequency of keyword?
Could you give me explanation of rest factors.
And you forgot about CTR which is hidden for us
Thank you
Pierre • Post Author •
22 mai 2018 at 10 h 58 minHi Bartek,
Keywords.size is the size (number of characters) of the meta « keywords » tag (which is no more used by Google since 2009 ????)
Nbextlinks : number of links on the page to external domains – not backlinks : I don’t have this information, maybe I could try get backlinks information from MOZ, Majestic SEO or Ahrefs or other providers in a next article.
headers.server.family : Apache, Nginx, IIS, cloud … (server type)
headers.cache.control.max.age : the age of the cache given by headers. This is not age of domain. I will try to get age of domain or age of page in a next article.
allbody.keyword.count : the number of keyword (or expression) occurences. allbody.keyword.frequency : the frequency ie : all words count/keyword count.
for the « headers » variables see here https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers list of http headers. headers variables are given by the GET function.
CTR : you mean Click-Through Rate on Google SERPs (Search Engine Results Pages) ? Here, the CTR is given by Yooda and is calculated from the … position so we can’t use it as an explanatory variable.
BartekPL
23 mai 2018 at 21 h 29 minWow awesome! ML at this sample do a really fun, tried it in rstudio and for me works as same as you, also successful.
Though i don’t know R syntax but i will try to add new features and share it with you