Partager la publication "Installation et prise en main de Dataiku DSS 6.0 sous Windows 10"
Dans cet article nous verrons comment installer Dataiku DSS 6.0 sur un ordinateur sous Windows 10. Nous verrons aussi quelques exemples d’utilisation.
Qui est Dataiku ?
Dataiku est une société technologique spécialisé dans les logiciels pour les sciences de données.
Bien qu’aujourd’hui basée à New-York, Dataiku a été créé à Paris notamment par des anciens d’Exalead, Florian Douetteau et Clément Sténac.
Dataiku édite un logiciel : Data Science Studio, qui est une plateforme collaborative pour les sciences de données. DSS permet (facilement ?) de créer des prototypes, des POC (Proof Of Concept) et de de déployer des applications pour le traitement des données et l’intelligence artificielle.
Fonctionnalités de Dataiku DSS 6.0

Dataiku DSS repose sur différents groupes de fonctionnalités :
- Les outils d’import de données.
- Les outils de nettoyage et d’enrichissement des données.
- Les outils d’analyse de données.
- Les outils de visualisation de données.
- Les outils de machine learning, deep learning …
- Les outils pour la création de tableaux de bord…
En plus des fonctionnalités intégrées il est possible pour le Data Scientist de développer ses propres « recettes », notamment avec les 2 langages phares des sciences de données : R et Python. (Cela tombe bien, ce sont avec lesquels nous travaillons :-))
Nous reviendrons sur les différentes fonctionnalités par la suite.
Actuellement à la version 6.0, Dataiku DSS est proposé en version gratuite et payante. Nous verrons ici comment installer la version gratuite sur votre ordinateur Windows ou Linux.
Le logiciel Dataiku DSS est au format Web et est accessible via un navigateur. Comme Dataiku DSS ne fonctionne véritablement que sous Linux, nous serons obligés d’installer le « Sous-système Windows pour Linux » en anglais Windows Subsystem for Linux (WSL), puis ensuite une distribution Linux (par exemple Ubuntu).
Installation de WSL et Ubuntu
Prérequis
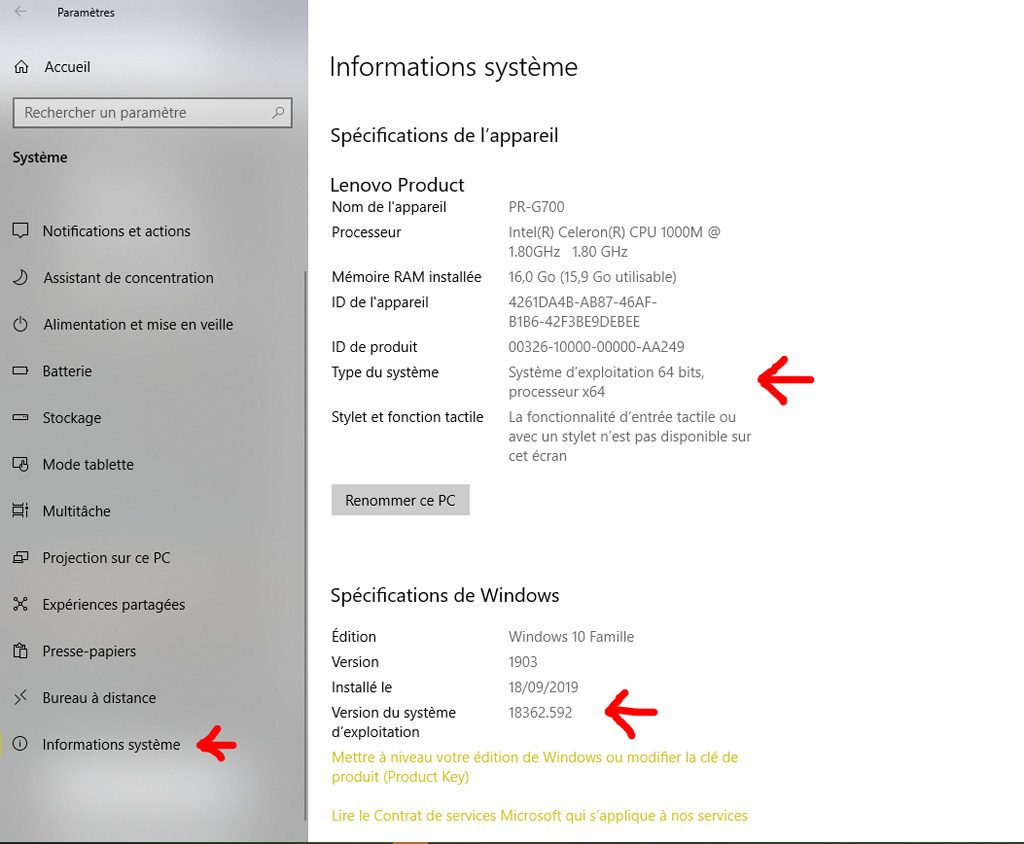
Au préalable il est nécessaire de vérifier que votre ordinateur à la version de Build égale ou supérieure à 16215 et que vous disposez d’un Windows 10 en 64 bits.
Pour votre version: allez dans Paramètres > Système > Informations système (tout en bas) :
Il faut aussi que vous ayez les droits administrateur.
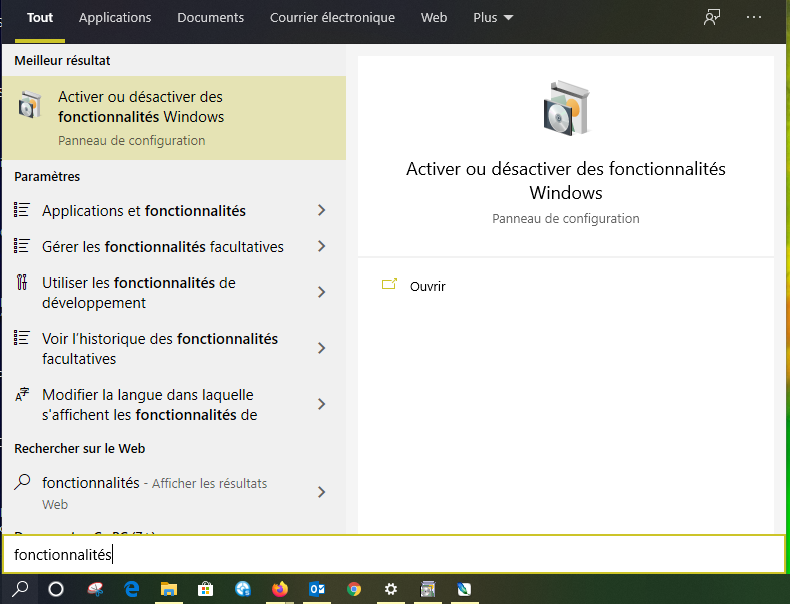
Installation de WSL
Dans la recherche Windows (loupe en bas à gauche), tapez « fonctionnalités » et choisissez » Activer ou désactiver des fonctionnalités Windows » :
La fenêtre des fonctionnalités Windows s’affiche :
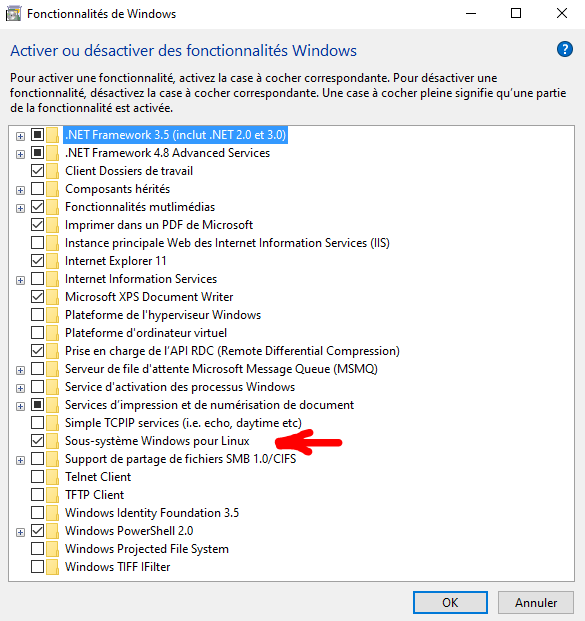
Vérifiez que la case « Sous-Système Windows pour Linux » est bien cochée et validez.
Redémarrez votre PC pour prendre en compte la nouvelle configuration.
Installation de la distribution Linux Ubuntu
L’installation de la distribution Linux se fait à partir du Microsoft Store. Recherchez « Microsoft Store » dans la recherche Windows :
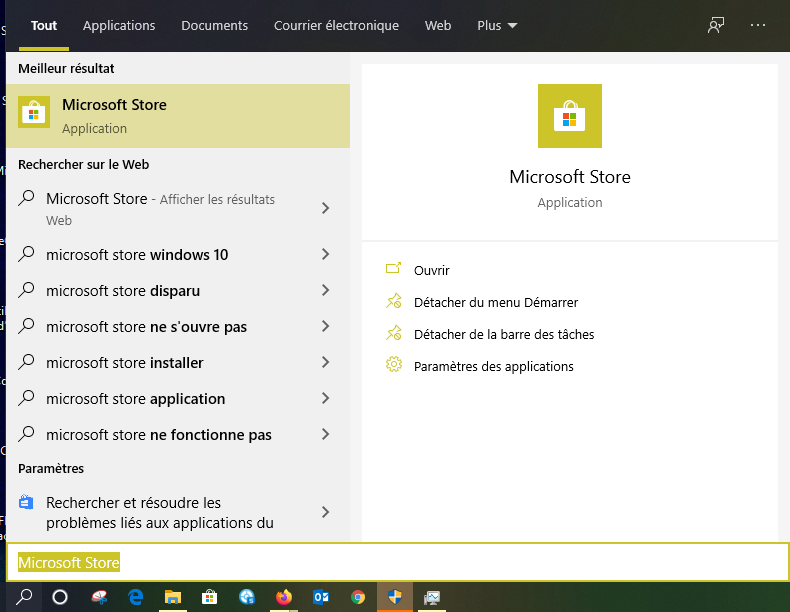
Dans Microsoft Store Recherchez « Linux » et choisissez votre distribution.
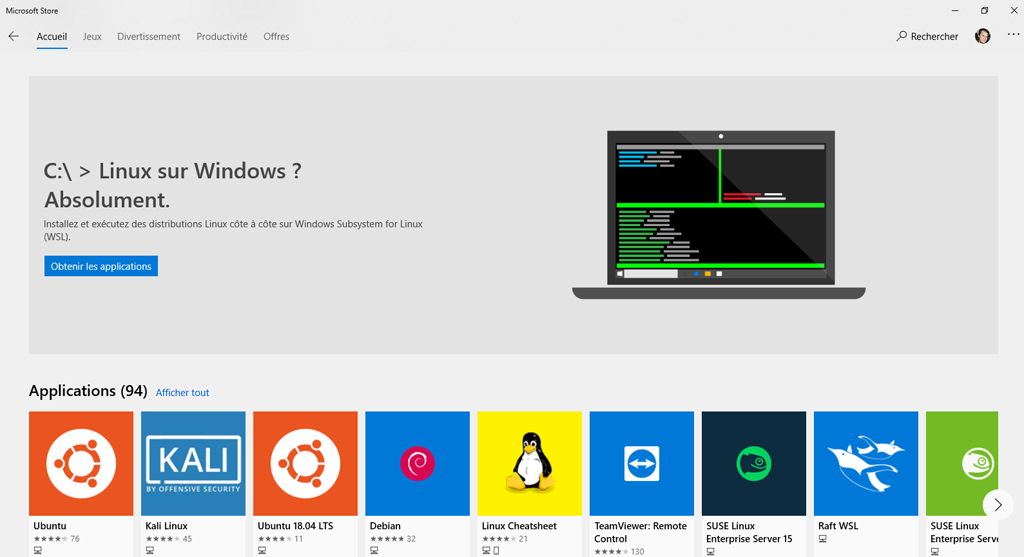
Je conseille la dernière version d’Ubuntu : 18.04 LTS
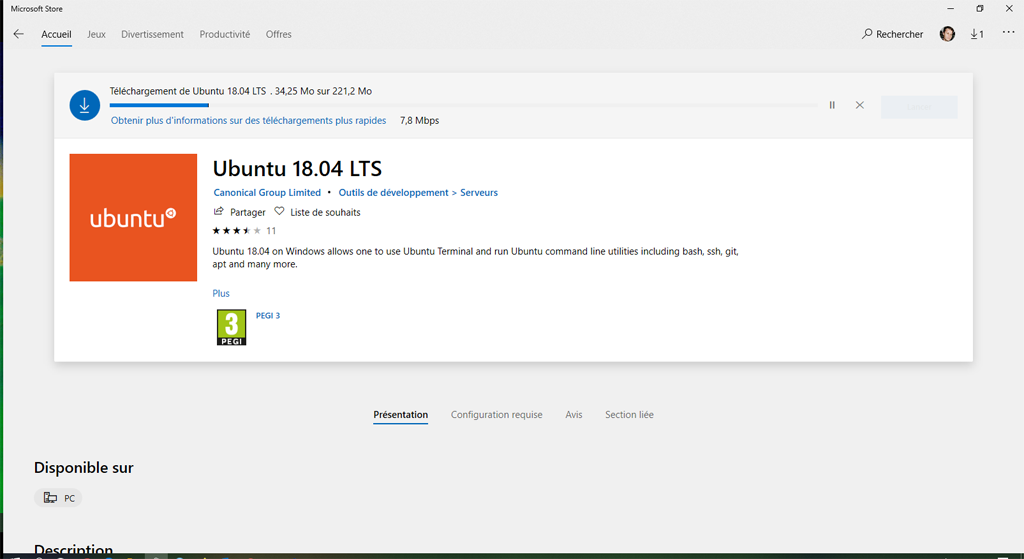
A la fin du téléchargement le système propose de lancer Ubuntu. Ceci ouvre une console Linux.
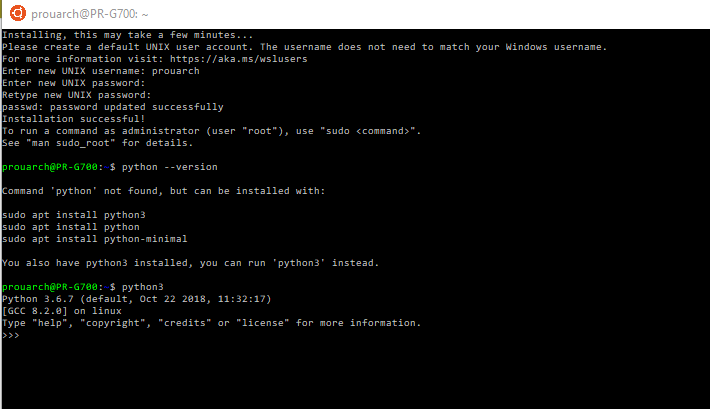
L’installation peut durer quelques minutes. Ensuite il vous demande de créer un utilisateur :
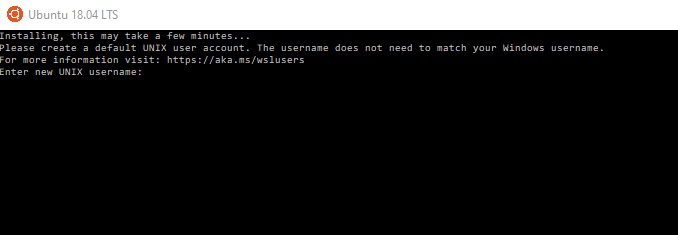
Pour info il existe déjà un Python d’installé par défaut : Python 3.6.7. Ce qui apporte un intérêt pour la compatibilité avec DSS sous Python 3.6, comme on le verra plus tard.
Profitons-en pour mettre à jour les paquets dans notre installation :
sudo apt update && sudo apt upgradeEt charger pip (en fait pip3) le gestionnaire de bibliothèques Python pour Python 3 . Remarque : le système chargera aussi de nombreuses bibliothèques Python.
sudo apt install python3-pip
Remarque : vous pouvez faire des copier/coller entre Windows et Linux ce qui facilitera la saisie des données :
- Windows : Ctrl + c / Ctrl + v
- Linux : Ctrl + Shift + c / Ctrl + Shift + v
Installation de Dataiku DSS
Téléchargement de l’archive Dataiku DSS :
Dans la fenêtre Ubuntu, tapez :
wget https://cdn.downloads.dataiku.com/public/dss/6.0.1/dataiku-dss-6.0.1.tar.gz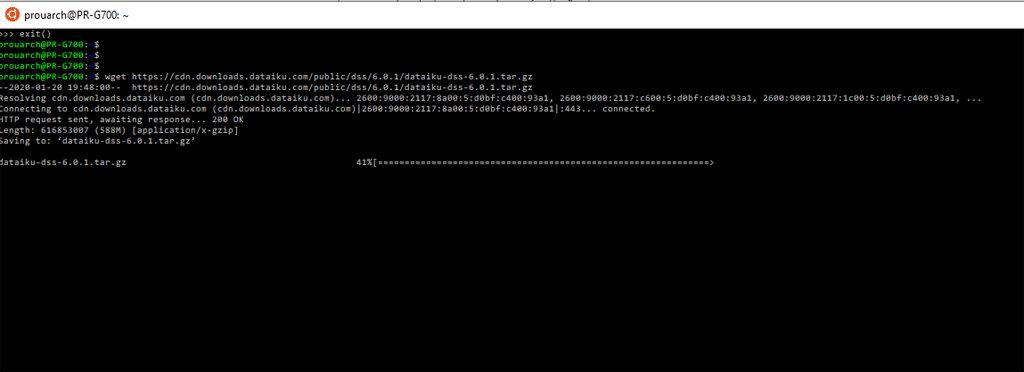
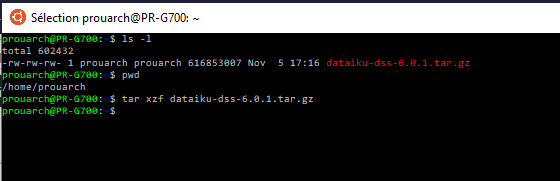
Décompactage de l’archive de Dadaiku DSS :
Décompacter l’archive :
tar xvzf dataiku-dss-6.0.1.tar.gzIci on décompacte dans le répertoire au nom de l’archive (pour moi /home/prouarch/dataiku-dss-6.0.1). Remarque : prouarch est le nom d’utilisateur que j’ai choisi précédemment.
Attention le processus peut-être long !
Installation de Dataiku DSS :
Vous devrez indiquez :
- Le répertoire d’installation « DATA_DIR », pour faire simple on l’appellera « DATA_DIR » :-).
- Le port de l’application, ici 11000 (valeur conseillée)
- La version de Python que l’on souhaite utiliser : pour nous Python 3.6
Attention, le système peut vous demander d’installer les dépendances au préalable. On en profite pour remettre à jour notre système.
sudo apt-get updatePuis on installe les dépendances pour Dataiku DSS :
sudo -i "/home//dataiku-dss-6.0.1/scripts/install/install-deps.sh" Enfin on installe Dataiku DSS. Remarque : vérifiez votre version, celle-ci peut avoir changé depuis la publication de cet article.
dataiku-dss-6.0.1/installer.sh -d DATA_DIR -p 11000 python3.6Démarrage de Dataiku DSS :
DATA_DIR/bin/dss startOuverture de Data Science Studio
Ouvrez un navigateur Chrome ou Firefox et allez à l’adresse : http://. Souvent (et pour moi) http://127.0.0.1:11000.
La première fois que vous ouvrez Dataiku DSS, celui-ci vous demande si vous avez une licence. Cliquez sur « No »
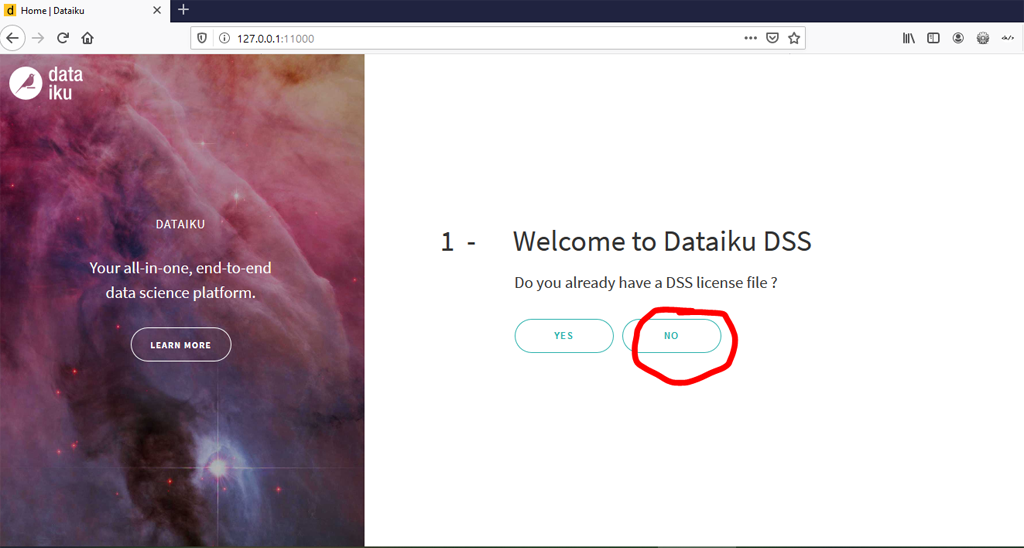
Puis choisissez la version gratuite et remplissez le formulaire :
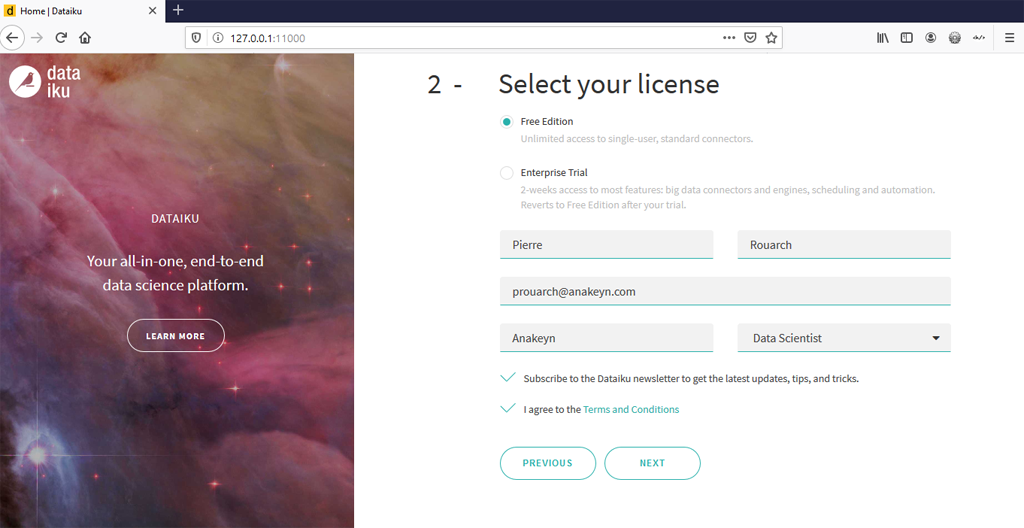
Et voilà ! l’installation est terminée, notez bien le login et le mot de passe par défaut : « admin », « admin ».
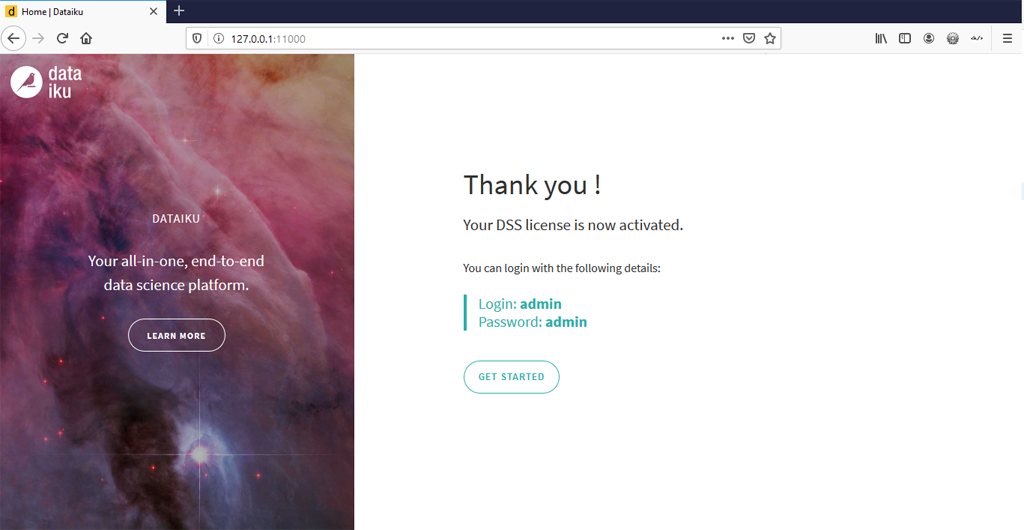
Prise en main de Dataiku DSS
La première fois que vous arrivez sur la page d’accueil, DSS vous propose des tutoriels, des vidéos et des cas types. N’hésitez pas à les consulter et à vous entrainer.
Prenons par exemple le premier tutoriel :
101 Basic Tutorial
Ce tutoriel présente des données d’une entreprise fictive, Haiku T-Shirt qui distribue ses produits en ligne.
Vous pouvez retrouver en détail ce tutoriel sur le site « Academy » de Dataiku en anglais : https://academy.dataiku.com/latest/tutorial/basics/index.html
Nous n’allons pas reprendre ce tutoriel en entier mais pointer sur les éléments qui nous semblent important.
La première chose à faire est de récupérer le jeu de données orders.csv sur votre ordinateur.
Puis ensuite sur la page d’accueil du Tutoriel d’importer le jeux de données en cliquant sur « Import your first dataset » :
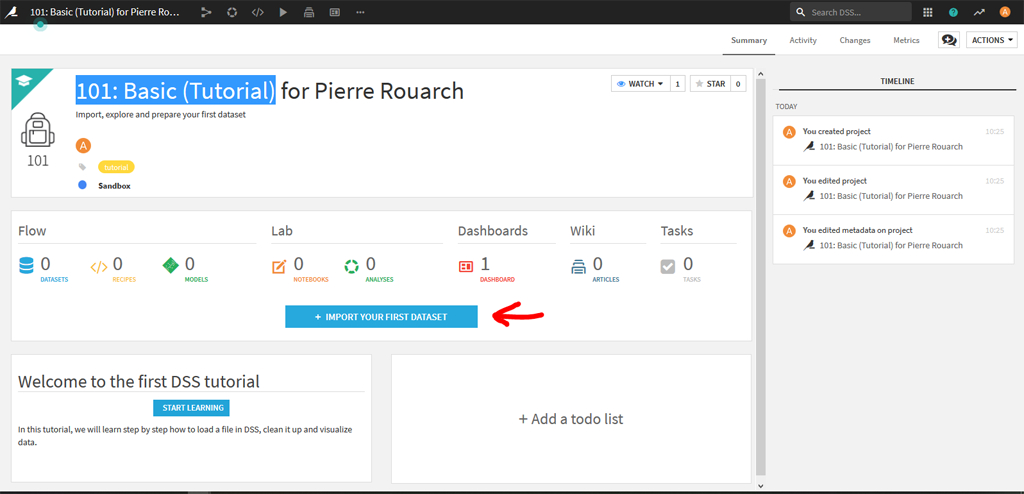
Dataiku DSS vous propose différentes méthodes pour importer et enregistrer vos données.
Remarque : toutes les options ne sont pas accessibles dans la version gratuite. Notamment l’accès à des bases SQL propriétaires et aux bases NoSQL ainsi que les plugins réalisés par Dataiku (voir plus bas) . Toutefois c’est bien suffisant pour réaliser un prototype.
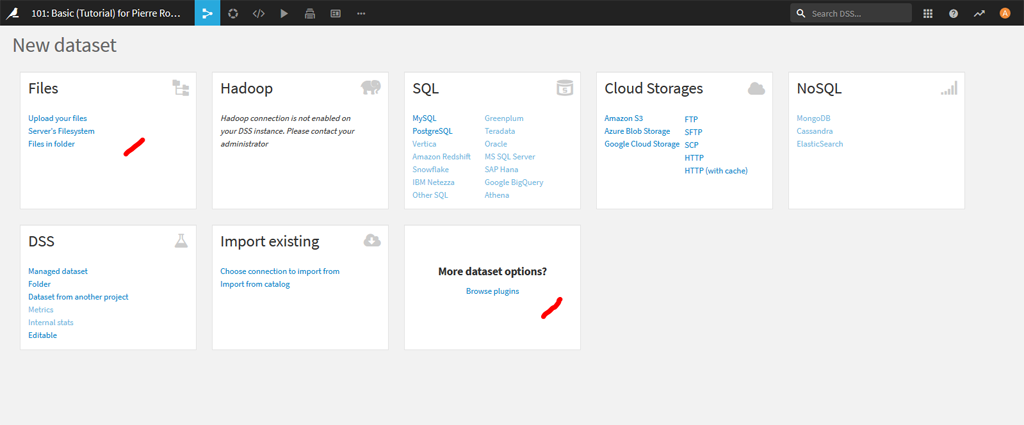
APPARTE : Plugins*
Par curiosité allons voir les plugins : ceux-ci sont classés dans différentes rubriques : Connector, Machine Learning, Vizualisation…
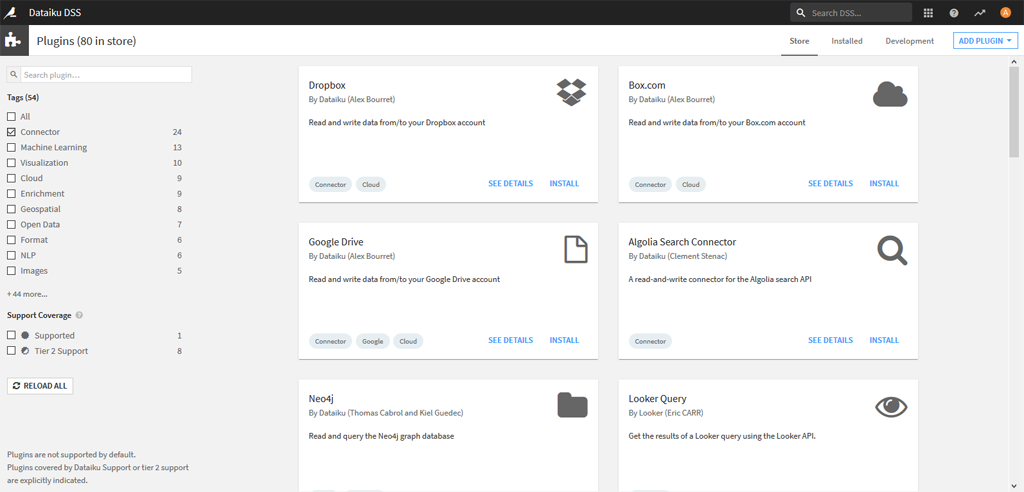
*Attention ! les plugins réalisés par Dataiku ne sont pas utilisables avec la version gratuite. Vous pouvez toutefois aller voir leur code source :
Regardons par exemple le plugin « Google Drive » pour pouvoir récupérer des fichiers sur notre Google Drive – > Cliquez sur Install et confirmez.
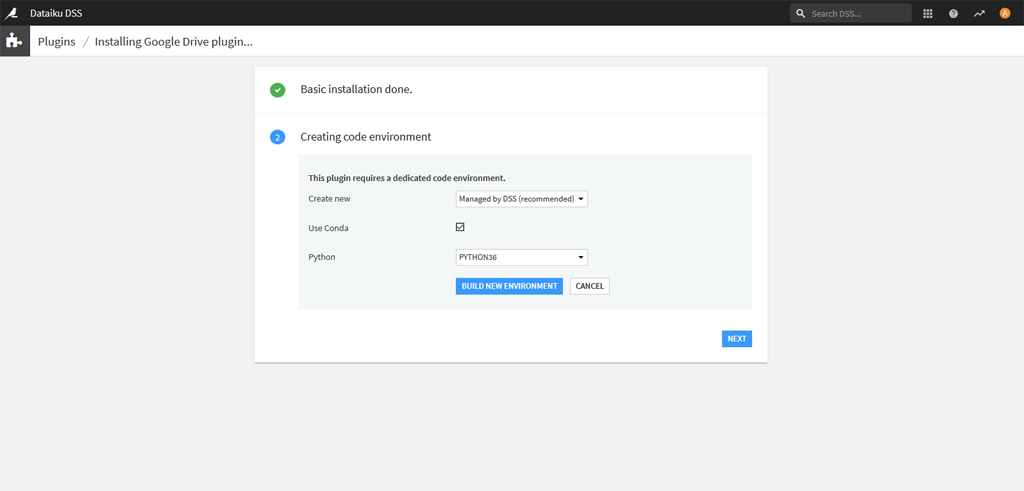
Le système va faire l’installation de base, puis va vous demander de créer un environnement pour votre code. Cet environnement correspond au même concept que les environnements virtuels de python. On va charger les bibliothèques qui nous intéressent pour faire fonctionner ce plugin.
Ici pour notre environnement on a choisi de fonctionner avec la gestion via DSS, l’utilisation de Conda et Python3.6 :
Le système va télécharger les dépendances dont il a besoin pour ce plugin. Cela peut prendre un certain temps :
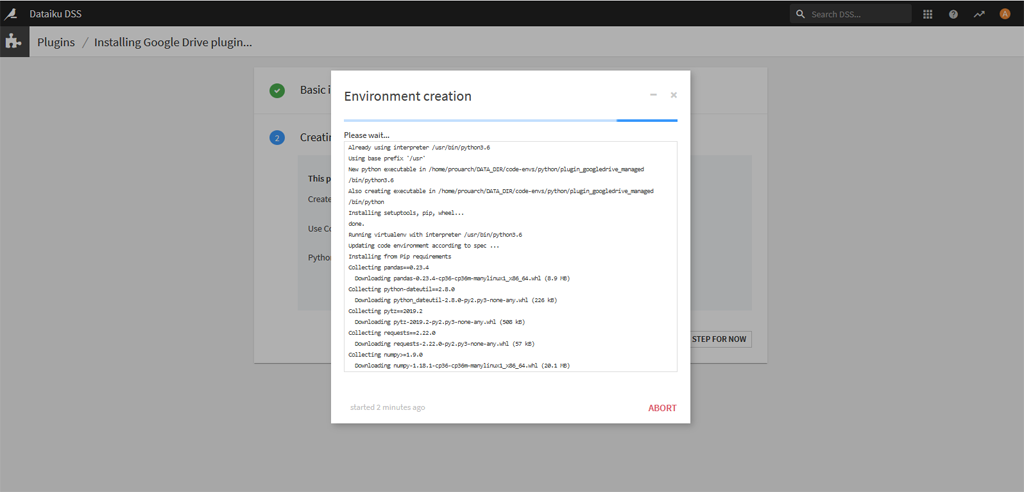
A la fin le système nous informe des différentes dépendances installées
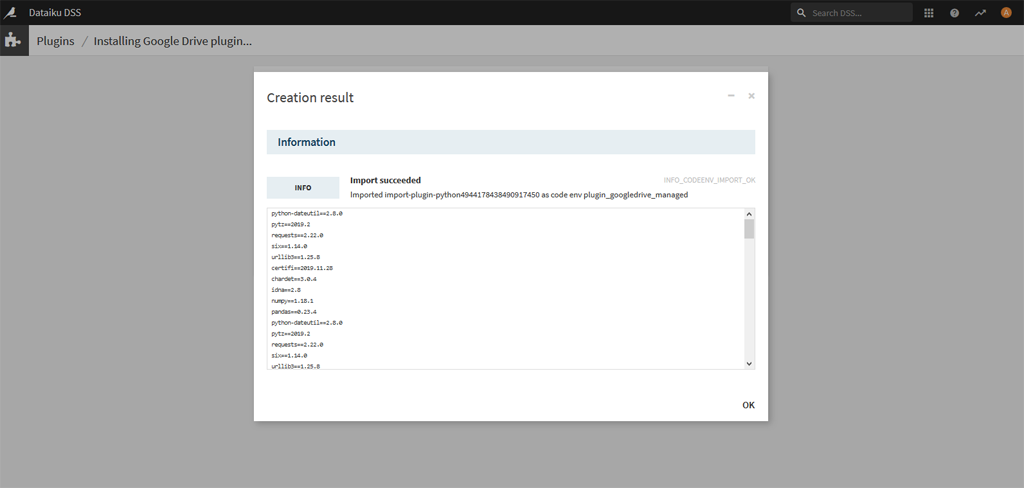
Revenez ensuite à la page des plugins et cliquez sur « Installed ». Vous aurez ainsi la liste de vos plugins installés. Ici on retrouve 3 plugins par défaut et le plugin Google Drive que l’on vient d’installer.
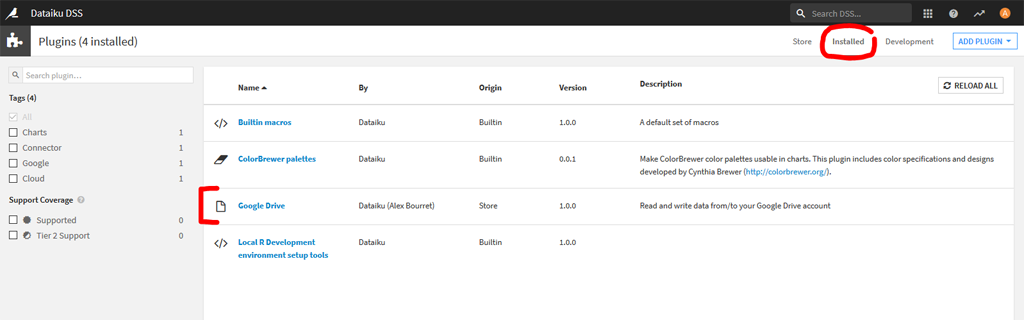
Cliquez sur « Google Drive » pour aller voir les caractéristiques de celui-ci :
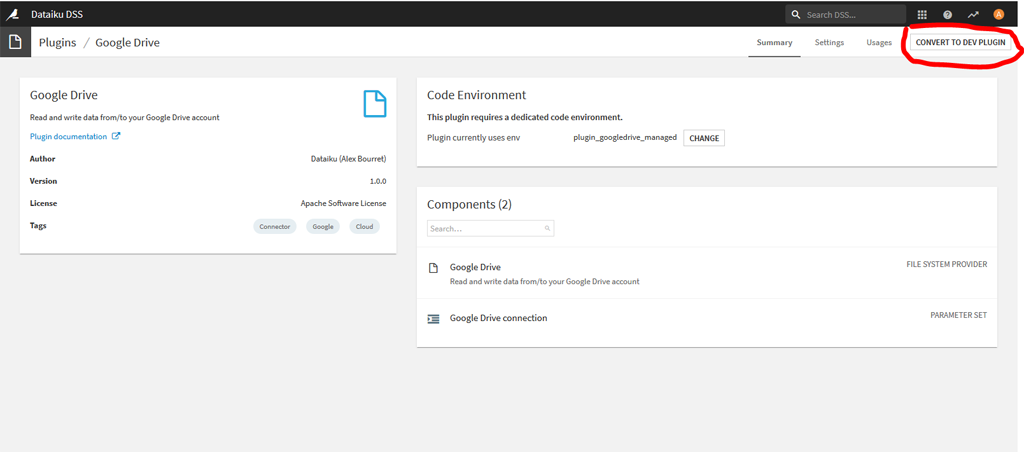
Afin de pouvoir consulter et modifier le code source du Plugin vous pouvez le transformer en plugin « en Développement » -> cliquez sur « Convert to Dev Plugin »
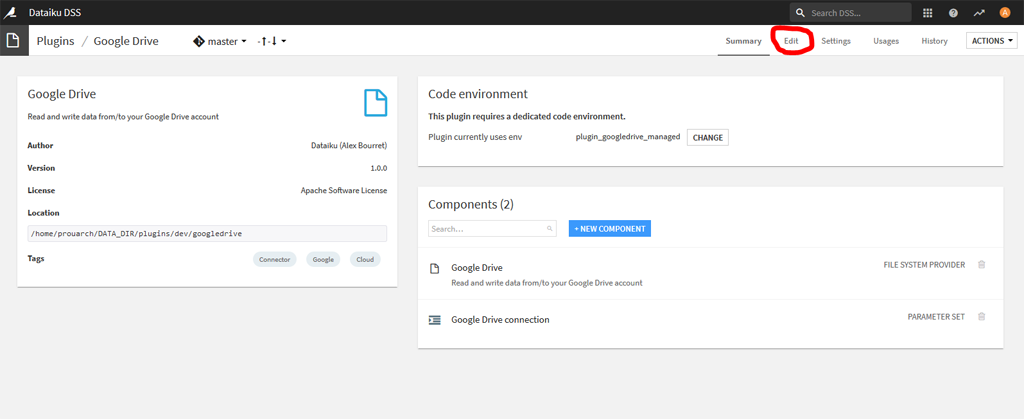
Cliquez sur « Edit » pour accéder au code source du Plugin :
Nous n’allons pas aller plus loin aujourd’hui en ce qui concerne le code source mais il faut savoir que, comme celui-ci est disponible, cela pourra nous aider dans le développement de nos propres plugins plus tard (ceux-ci pourrons fonctionner avec la version gratuite).
Retour au Projet
Revenons à notre projet, soit en cliquant sur l’icône en forme de grille puis en choisissant « Projects », soit en revenant à la page d’accueil en cliquant sur l’oiseau.
Import des données
Revenons à notre projet :
Cliquez sur « Import your first dataset » :
Dans le carré « files » cliquez sur « upload your files » et uploadez ensuite le fichier orders.csv que l’on avait récupéré précédemment. une fois l’importation faite, cliquez sur « preview » en bas à droite pour voir comment s’est passé l’importation.
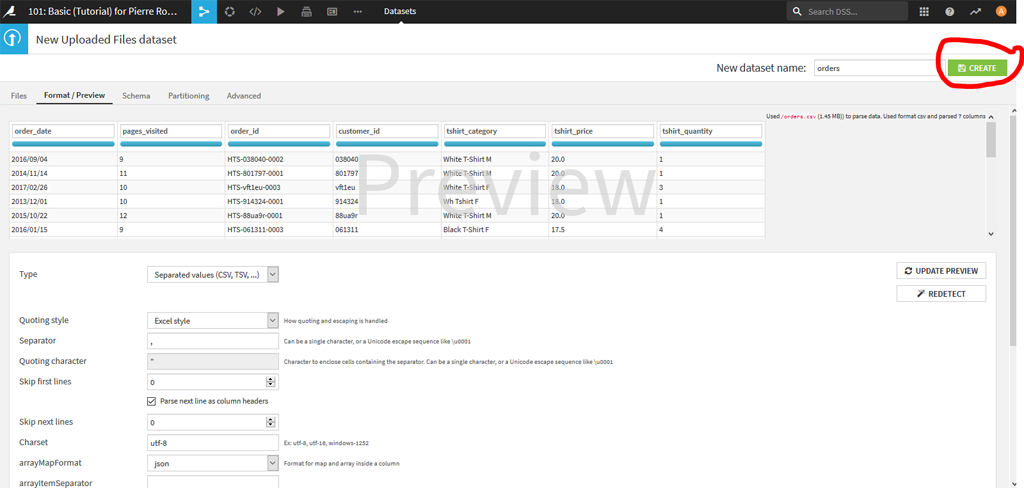
En général, Dataiku reconnait assez facilement les format de fichiers. Toutefois, si cela ne convient pas vous pouvez modifier les paramètres d’importation. Une fois que tout vous semble OK, cliquez sur « Create » pour sauvegarder le dataset dans le système.
Echantillonnage
Par défaut le système travaille sur un échantillon de l’ensemble des données. En cliquant sur « Configure Sample », vous pouvez modifier la taille de l’échantillon ainsi que la méthode d’échantillonnage.
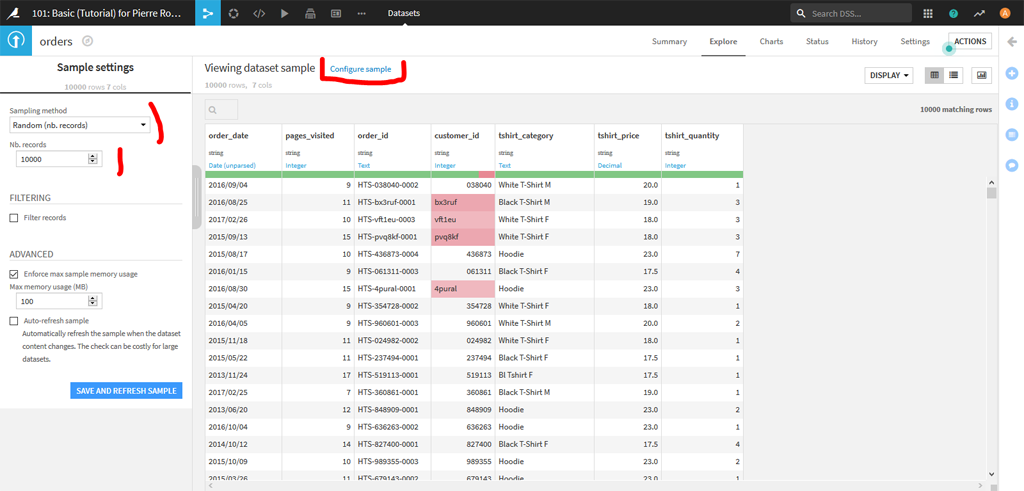
Analyse rapide par variable
En cliquant sur le nom de la variable un menu déroulant s’affiche et vous pouvez par exemple faire une première analyse d’une variable. Ici choisissons par exemple le nombre de pages visitées par les acheteurs :
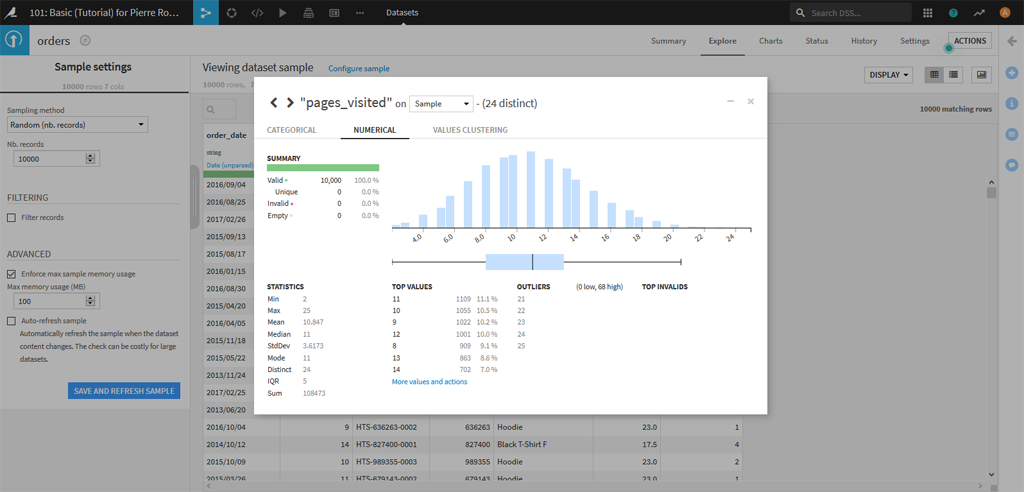
La distribution des pages vues par les acheteurs présente une belle courbe de Gauss.
Graphiques
Sur la page du dataset dans le menu horizontal, vous pouvez voir l’option Charts. Charts est un outil qui permet de créer des graphiques rapidement à partir des données du Dataset avec des glisser/déposer un peu à la mode de Tableau.
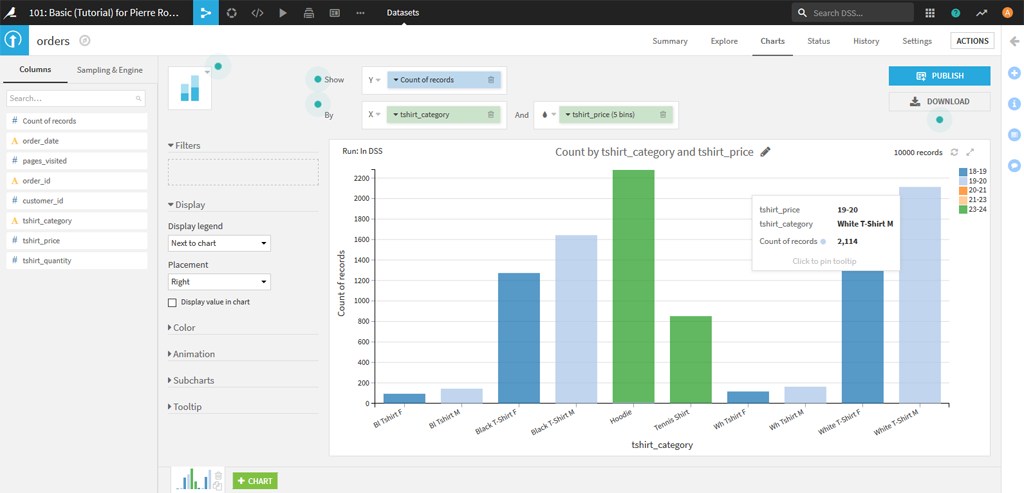
Si vous cliquez sur « Publish » vous pourrez récupérer votre graphique dans un tableau de bord :
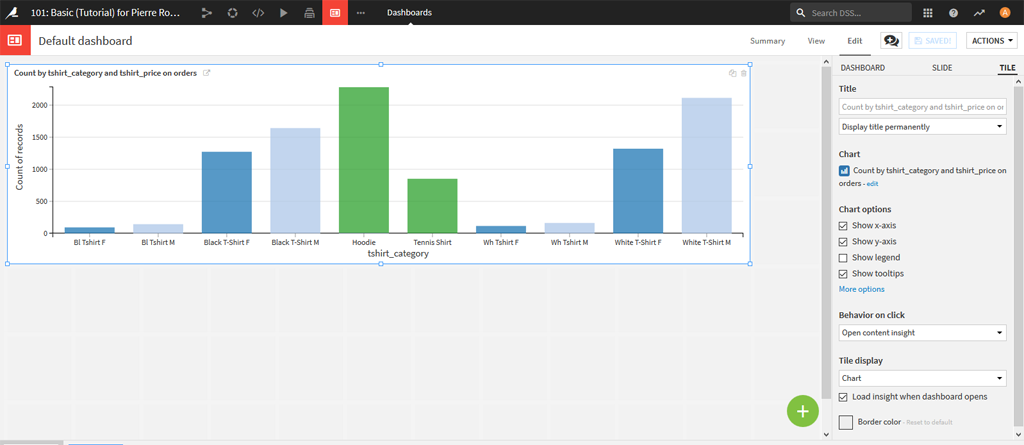
Comme vous pouvez le constater il y a des descriptions de T-Shirt en doublon. Par exemple Bl et Black et Wh et White font référence à des mêmes produit.
Nous allons donc les dédoublonner, nous allons pour cela faire appel à une « recette ».
Recette dans le flUX :
Sur la page ou vous êtes, passez votre souris sur le petit signe :

Dans le menu déroulant choisissez flow :
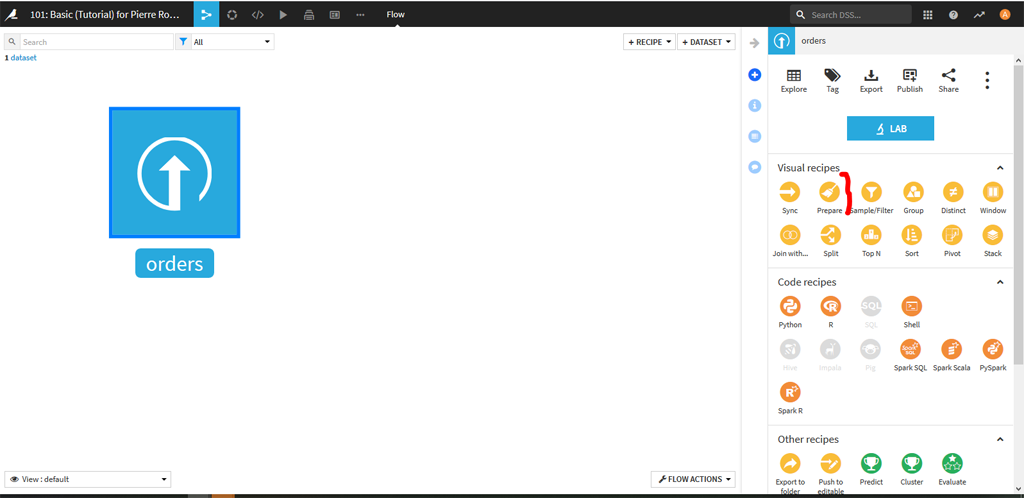
Dans le menu de droite (au besoin cliquez sur « Actions ») choisissez la recette « prepare »
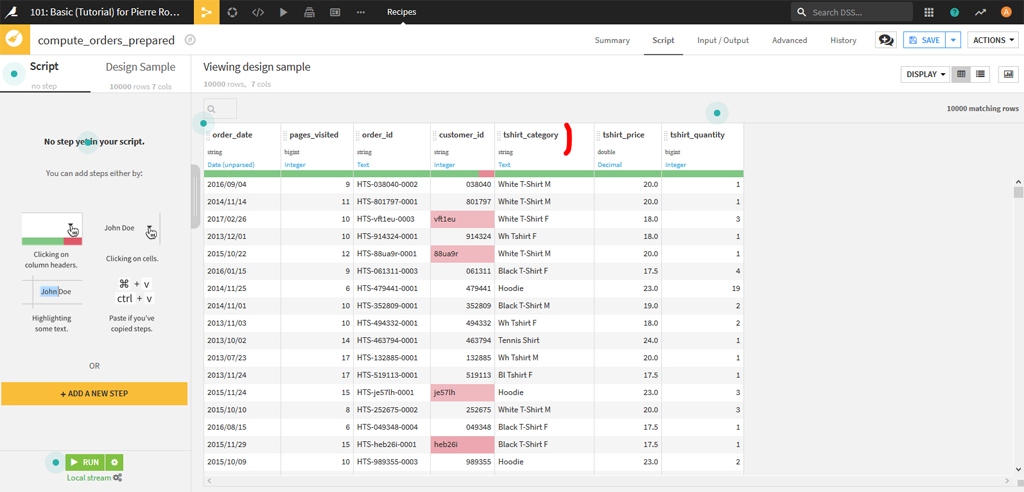
Sur la variable « tshirt_category » faites une analyse. Sélectionner 2 types de T-shirts équivalents (par exemple White T-Shirt M et Wh Tshirt M) et faites un « Merge Selected » (menu « Mass Actions »)
Le résultat permet de regrouper 2 catégories dans une .
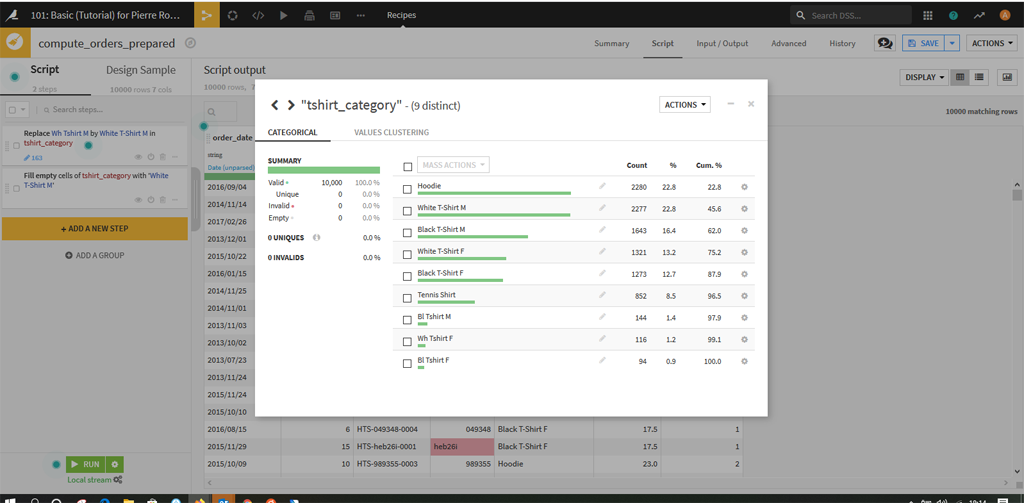
Recommencer l’opération autant de fois que nécessaire.
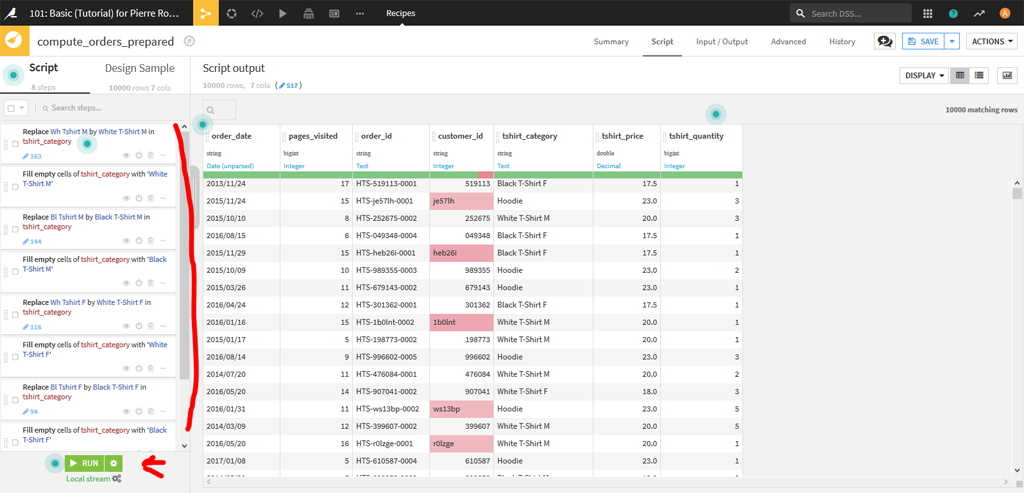
Sur ma gauche on peut voir l’ensemble des actions suivies par la recette. Cliquez sur « Run » pour lancer le processus.
Une fois le processus terminé, retournez sur la page de « Flow » :
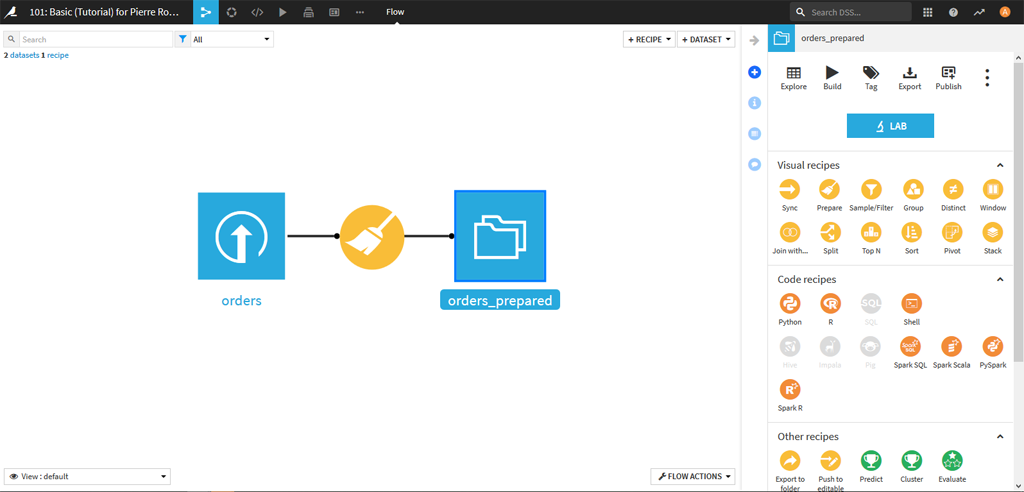
Dans le nouveau flux nous avons maintenant une recette pour nettoyer le dataset de base et un nouveau dataset propre.
Regroupement
Il serait intéressant de regrouper les ventes par client. Sur la page de Flow dans le menu des recettes choisissez « Group » et groupez par « customer_id ».
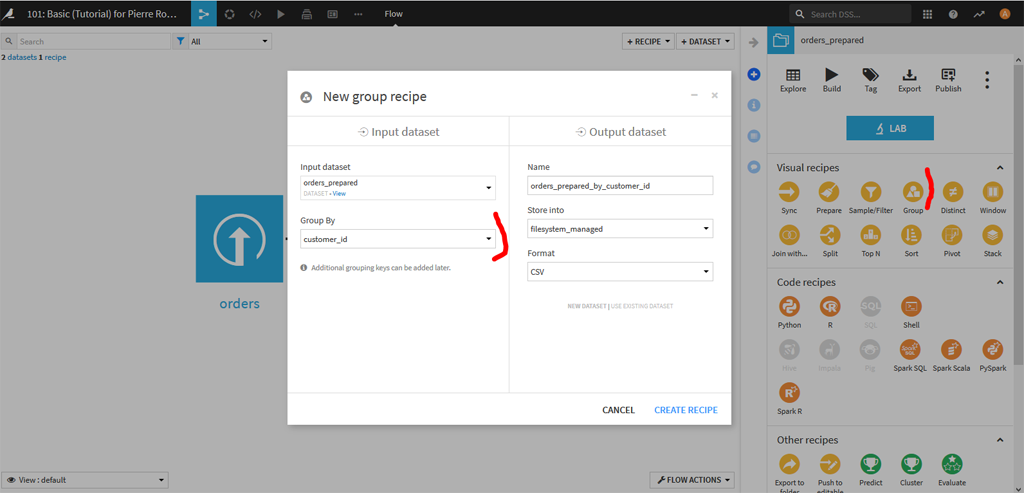
Lors des regroupement des variables ne vont plus servir comme par exemple order_id, alors que pour d’autres il sera judicieux de faire apparaitre un indicateur intéressant :
- Date de commande : on prend la dernière pour savoir si le client est toujours actif.
- Le nombre de pages visitées en moyenne sur toutes les commandes de la personne.
- Le total en valeur.
- Le total en volume.
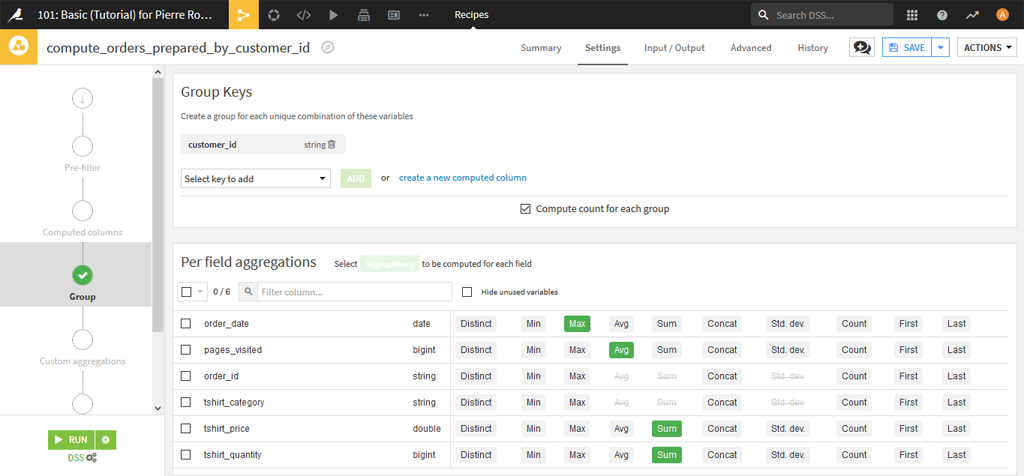
Cliquez ensuite sur Run pour créer le nouveau Dataset et retournez ensuite à la page de Flow.
Nouvelle page de Flow
La page de flow s’est enrichie avec la recette de regroupement et le nouveau dataset :
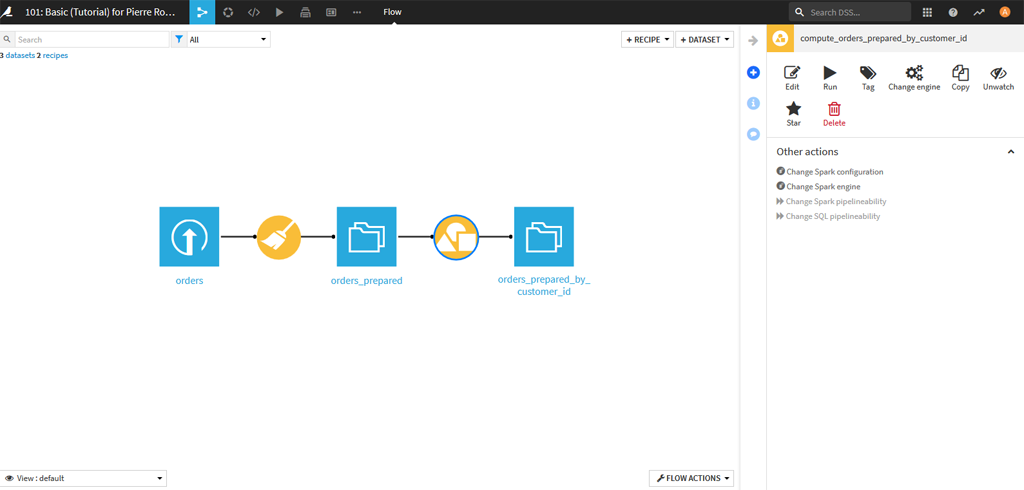
Cliquez sur le nouveau Dataset
Dataset Regroupé
Ouvrez le dernier Dataset :
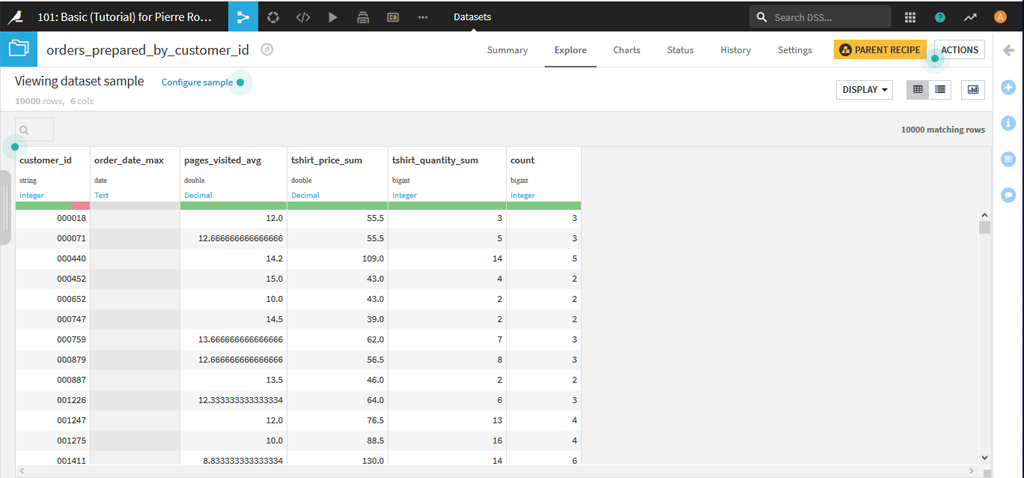
A ce stade, vous pouvez analyser les variables une à une comme nous l’avons vu précédemment ou bien faire un graphique avec la fonction « Charts » :
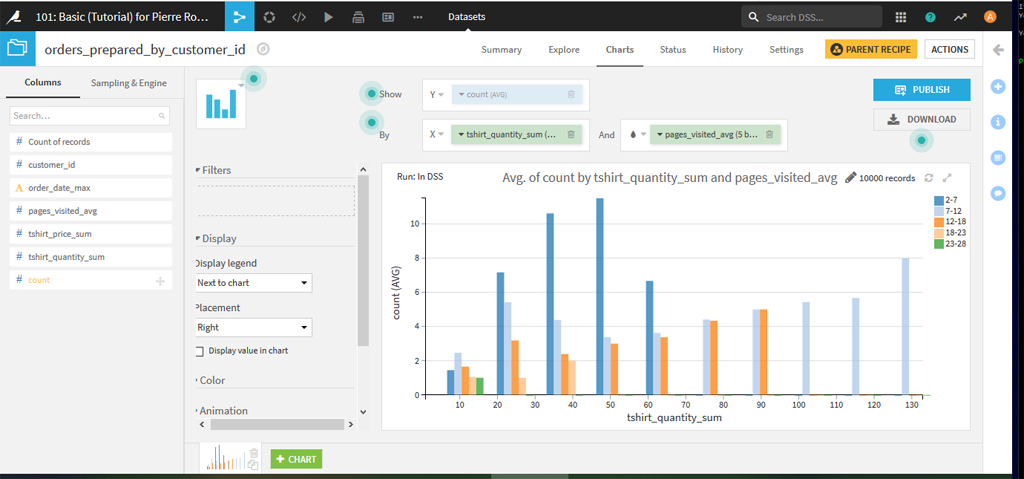
Nous allons arrêter là pour l’instant.
Nous aurons l’occasion de tester d’autres fonctionnalités de Dataiku DSS dans d’autres articles dédiés au Data SEO et Web Analytics.
N’hésitez pas à faire vos remarques et poser vos questions en commentaires.
A Bientôt,
Pierre