Partager la publication "Analyse du trafic selon les canaux avec Python"
Cet article reprend l’article Analyse du trafic selon les canaux avec R, cette fois en utilisant le langage Python.
Par conséquent, nous ne reprendrons pas en détail toutes les explications et vous invitons à vous reporter à ce précédent article.
Toutefois rappelons de quoi il s’agit :
Nous allons investiguer ici la typologie des sources de trafic ou canaux, et nous allons aussi comparer ces sources selon le type de pages : « pages de base » et « pages marketing ».
Nous verrons comment obtenir à partir de Google Analytics une information à peu près pertinente sur les différents canaux.
De quoi aurons nous besoin ?
Python Anaconda
Anaconda est une version de Python dédiée aux Data Sciences. Rendez vous sur la page de téléchargement d’Anaconda Distribution pour télécharger la version qui vous convient selon votre ordinateur.
Jeu de données
Vous pouvez soit utiliser nos données pour tester le programme (dézippez les archives dans le même répertoire que le code source ):
- Toutes les pages vues
- Pages vues de base
- Pages Vues « Direct Marketing »
- Canaux en fonction des sources
Soit, créer votre propre jeu de données à partir de vos statistiques Google Analytics, en suivant la procédure sur les articles précédents :
- Importer les données de Google Analytics API avec Python Anaconda.
- Nettoyage du Spam dans Google Analytics avec Python.
- Détection du trafic Web significatif avec Python.
- Publication d’articles vs événements significatifs en Python.
- Quelle est la durée de vie de mes articles sur mon site ? Python
Code source :
Copiez/Collez les codes sources suivants ou récupérez le code en entier gratuitement dans notre boutique : https://www.anakeyn.com/boutique/produit/script-python-trafic-par-canaux/
Chargement des bibliothèques et récupération des données de pages vues globales :
il s’agit pour nous du fichier dfPageViews.csv
# -*- coding: utf-8 -*-
"""
Created on Tue Jun 4 09:50:35 2019
@author: Pierre
"""
#########################################################################
# TrafficChannelsPython
# Analyse du trafic selon les canaux, comparatif des pages de base et des
# Articles marketing
# Auteur : Pierre Rouarch 2019 - Licence GPL 3
# Données : Issues de l'API de Google Analytics -
# Comme illustration Nous allons travailler sur les données du site
# https://www.networking-morbihan.com
#############################################################
# On démarre ici pour récupérer les bibliothèques utiles !!
#############################################################
#def main(): #on ne va pas utiliser le main car on reste dans Spyder
#Chargement des bibliothèques utiles (décommebter au besoin)
import numpy as np #pour les vecteurs et tableaux notamment
import matplotlib.pyplot as plt #pour les graphiques
#import scipy as sp #pour l'analyse statistique
import pandas as pd #pour les Dataframes ou tableaux de données
import seaborn as sns #graphiques étendues
#import math #notamment pour sqrt()
#from datetime import timedelta
#from scipy import stats
#pip install scikit-misc #pas d'install conda ???
from skmisc import loess #pour methode Loess compatible avec stat_smooth
#conda install -c conda-forge plotnine
from plotnine import * #pour ggplot like
#conda install -c conda-forge mizani
from mizani.breaks import date_breaks #pour personnaliser les dates affichées
#Si besoin Changement du répertoire par défaut pour mettre les fichiers de sauvegarde
#dans le même répertoire que le script.
import os
print(os.getcwd()) #verif
#mon répertoire sur ma machine - nécessaire quand on fait tourner le programme
#par morceaux dans Spyder.
#myPath = "C:/Users/Pierre/CHEMIN"
#os.chdir(myPath) #modification du path
#print(os.getcwd()) #verif
#Revenons au Dataframe des pages vues dfPageViews
#Relecture ############
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
dfPageViews = pd.read_csv("dfPageViews.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
dfPageViews.info() #72821 enregistrements
Regardons ce que l’on a dans la variable medium :
############################################################ # Typologie du trafic entrant ############################################################ #regardons ce que l'on a dans la variable medium. dfPageViews['medium'].value_counts() #La variable medium ne nous donne pas une information fiable.
organic 29678
(none) 21913
referral 19994
twitter 1215
facebook 15
sortir-en-bretagne 4
(not set) 2
Name: medium, dtype: int64
(none) correspond au trafic « direct » un peu fourre tout. les « referral » demanderons à être investigués.
Regardons dans la variable source
##########################################################################
#regardons les différentes sources
mySources = dfPageViews['source'].value_counts().to_frame()
mySources.info()
mySources.rename(columns = {'source':'freq'}, inplace = True)
mySources['source']=mySources.index
mySources['freq'].head(n=20) #20 premières valeurs
google 28089
(direct) 21913
facebook.com 3315
viadeo.com 2507
google.fr 1714
twitterfeed 1232
quaidesreseaux56.fr 882
images.google.fr 853
l.facebook.com 786
m.facebook.com 712
bing 690
t.co 652
designsgenius.com 517
linkis.com 511
localhost 505
linkedin.com 482
images.google 452
aleos2i.fr 443
fr.viadeo.com 374
yahoo 279
Name: freq, dtype: int64
On retrouve nos (none) en (direct)
On va regrouper les canaux « à la main » et les récupérer dans le fichier mySourcesChannel.csv.
# Sauvegarde en csv
mySources.to_csv("mySources.csv", sep=";", index=False) #séparateur ;
#.... traitement manuel externe ....
mySourcesChannel = pd.read_csv("mySourcesChannel.csv", sep=";")
mySourcesChannel.info()
dfPageViews.info()
Analyse du trafic Global
On va traiter les données concernant le trafic Global :
#traitement préalable des données #On vire les blancs pour faire le merge on dfPageViews['source'] = dfPageViews['source'].str.strip() mySourcesChannel['source'] = mySourcesChannel['source'].str.strip() dfPVChannel = pd.merge(dfPageViews, mySourcesChannel, on='source', how='left') dfPVChannel.info() #voyons ce que l'on a comme valeurs. dfPVChannel['channel'].value_counts() sorted(dfPVChannel['channel'].unique()) #creation de la dataframe dateChannel_data par jour et canal dfDatePVChannel = dfPVChannel[['date', 'channel', 'pageviews']].copy() #nouveau dataframe avec que la date et les canaux dfDatePVChannel.info() dateChannel_data = dfDatePVChannel.groupby(['date', 'channel']).count() # #dans l'opération précédente la date et le channel sont partis dans l'index dateChannel_data = dateChannel_data.reset_index() #recrée les colonnes date et channel dateChannel_data['Année'] = dateChannel_data['date'].astype(str).str[:4] #ajoute l'année dateChannel_data.info() dateChannel_data.sort_values(by=['date', 'channel']) dateChannel_data.head(20)
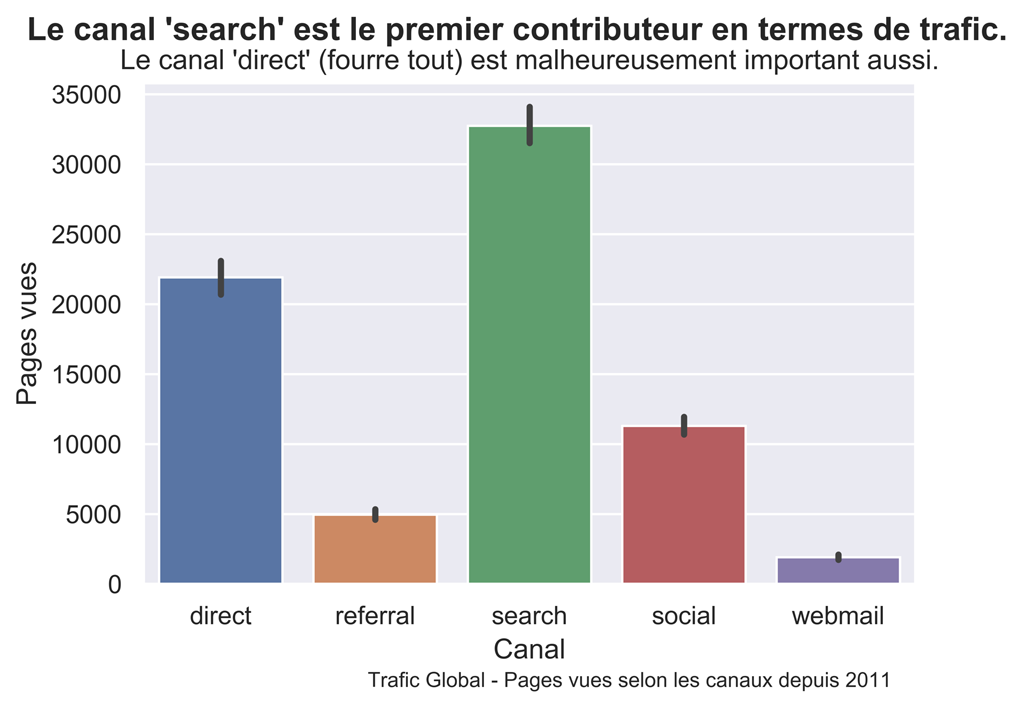
Graphique en barre sur toute la période
##########################################################################
# Graphique en barre général Répartition du trafic selon les canaux.
##########################################################################
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.barplot(x='channel', y='pageviews', data=dateChannel_data, estimator=sum, order=sorted(dfPVChannel['channel'].unique()))
fig.suptitle("Le canal 'search' est le premier contributeur en termes de trafic.", fontsize=14, fontweight='bold')
ax.set(xlabel="Canal", ylabel="Pages vues",
title="Le canal 'direct' (fourre tout) est malheureusement important aussi.")
fig.text(.35,-.03,"Trafic Global - Pages vues selon les canaux depuis 2011", fontsize=9)
#plt.show()
fig.savefig("PV-Channel-bar.png", bbox_inches="tight", dpi=600)
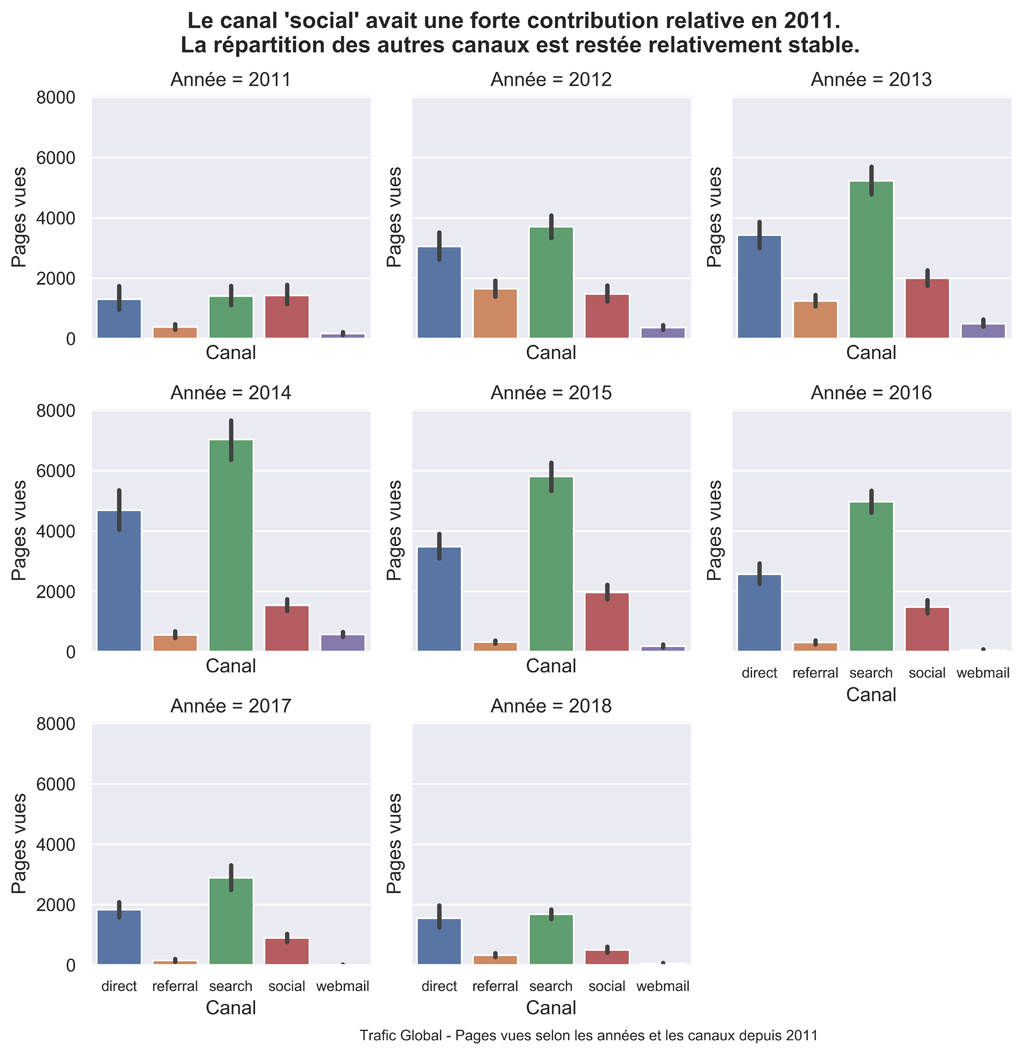
Graphique en barre par ANNEES
##########################################################################
#Graphique en barre par année
#Répartition du trafic selon les canaux.
##########################################################################
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
g=sns.FacetGrid(dateChannel_data, col="Année", col_wrap=3)
g.map(sns.barplot, 'channel', 'pageviews', palette="deep", estimator=sum, order=sorted(dfPVChannel['channel'].unique()))
plt.subplots_adjust(top=0.9)
g.fig.suptitle("Le canal 'social' avait une forte contribution relative en 2011. \n La répartition des autres canaux est restée relativement stable.", fontsize=14, fontweight='bold')
g.set(xlabel="Canal", ylabel="Pages vues")
g.set_xticklabels(fontsize=9)
g.fig.text(.35,-.00,"Trafic Global - Pages vues selon les années et les canaux depuis 2011", fontsize=9)
#plt.show()
g.savefig("PV-Channel-bar-an.png", bbox_inches="tight", dpi=600)
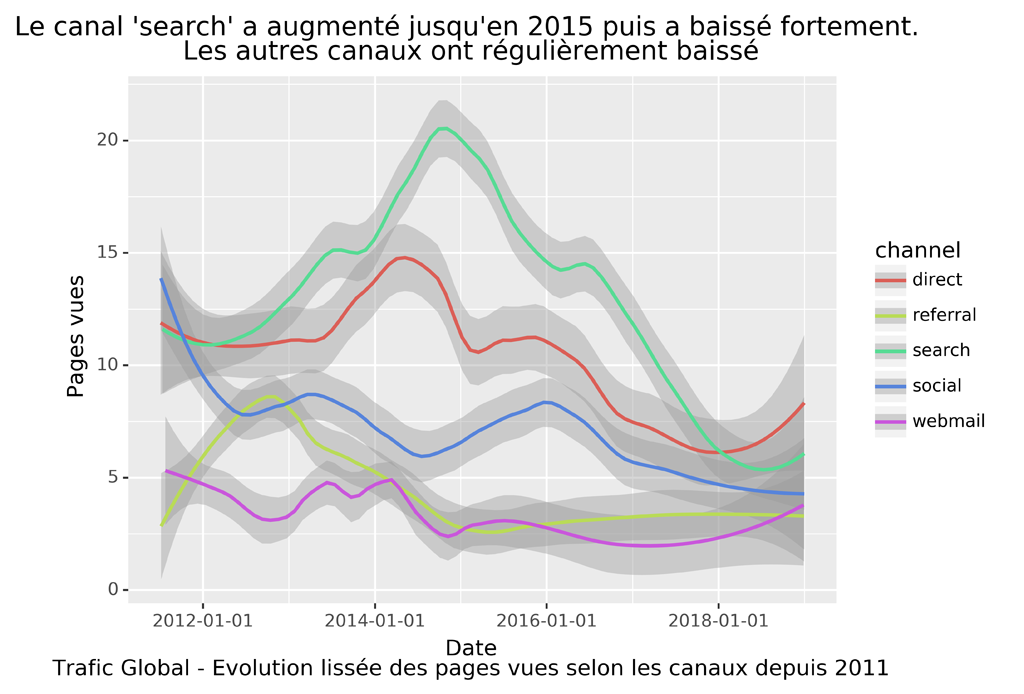
EVOLUTION DES PAGES VUES SELON LES CANAUX
####################################################################
#Evolution des pages vues selon les canaux (lissée)
####################################################################
###################################################################################
###### On prendra Plotline : implémentation de ggplot dans Python ########
#https://plotnine.readthedocs.io/en/stable/generated/plotnine.stats.stat_smooth.html#plotnine.stats.stat_smooth
p = (ggplot(dateChannel_data) +
stat_smooth(aes('date', 'pageviews', color='channel'), method='loess', span=0.4) +
ylab("Pages vues") +
scale_x_datetime(breaks=date_breaks('2 years')) + # new
ggtitle("Le canal 'search' a augmenté jusqu'en 2015 puis a baissé fortement. \nLes autres canaux ont régulièrement baissé") +
xlab("Date\nTrafic Global - Evolution lissée des pages vues selon les canaux depuis 2011")
)
p.save("PV-Channel-smooth.png", bbox_inches="tight", dpi=600)
##Remarque : certains paramètres d'affichage ne sont pas implémentés comme
##par exemple caption par rapport au ggplot de R
#sauvegarde de dateChannel_data
dateChannel_data.to_csv("dateChannel_data.csv", sep=";", index=False)
Analyse du trafic de base
C omme on l’a vu dans des précédents articles, le trafic de « base » est le trafic pour les pages hors trafic créé grâce aux « articles marketing » . On le récupère dans le fichier dfBasePageViews.csv
##########################################################################
# Pour le traffic de base
##########################################################################
#Relecture ############
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
dfBasePageViews = pd.read_csv("dfBasePageViews.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
dfBasePageViews.dtypes
dfBasePageViews.count() #37615
dfBasePageViews.head(20)
#On vire les blancs pour faire le merge on
dfBasePageViews['source'] = dfBasePageViews['source'].str.strip()
mySourcesChannel['source'] = mySourcesChannel['source'].str.strip()
#récuperation de la variable channel dans la dataframe principale par un left join.
dfBasePVChannel = pd.merge(dfBasePageViews, mySourcesChannel, on='source', how='left')
dfBasePVChannel.info()
#voyons ce que l'on a comme valeurs.
dfBasePVChannel['channel'].value_counts()
sorted(dfBasePVChannel['channel'].unique())
#création de la dataframe dateChannel_BaseData par jour et canal
dfDateBasePVChannel = dfBasePVChannel[['date', 'channel', 'pageviews']].copy() #nouveau dataframe avec que la date et les canaux
dfDateBasePVChannel.info()
dateChannel_baseData = dfDateBasePVChannel.groupby(['date', 'channel']).count() #
#dans l'opération précédente la date et le channel sont partis dans l'index
dateChannel_baseData = dateChannel_baseData.reset_index() #recrée les colonnes date et channel
dateChannel_baseData['Année'] = dateChannel_baseData['date'].astype(str).str[:4] #ajoute l'année
dateChannel_baseData.info()
dateChannel_baseData.sort_values(by=['date', 'channel'])
dateChannel_baseData.head(20)
GRAPHIQUE TRAFIC DE BASE DEPUIS 2011
##########################################################################
# Graphique en barre général Répartition du trafic selon les canaux.
##########################################################################
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.barplot(x='channel', y='pageviews', data=dateChannel_baseData, estimator=sum, order=sorted(dfBasePVChannel['channel'].unique()))
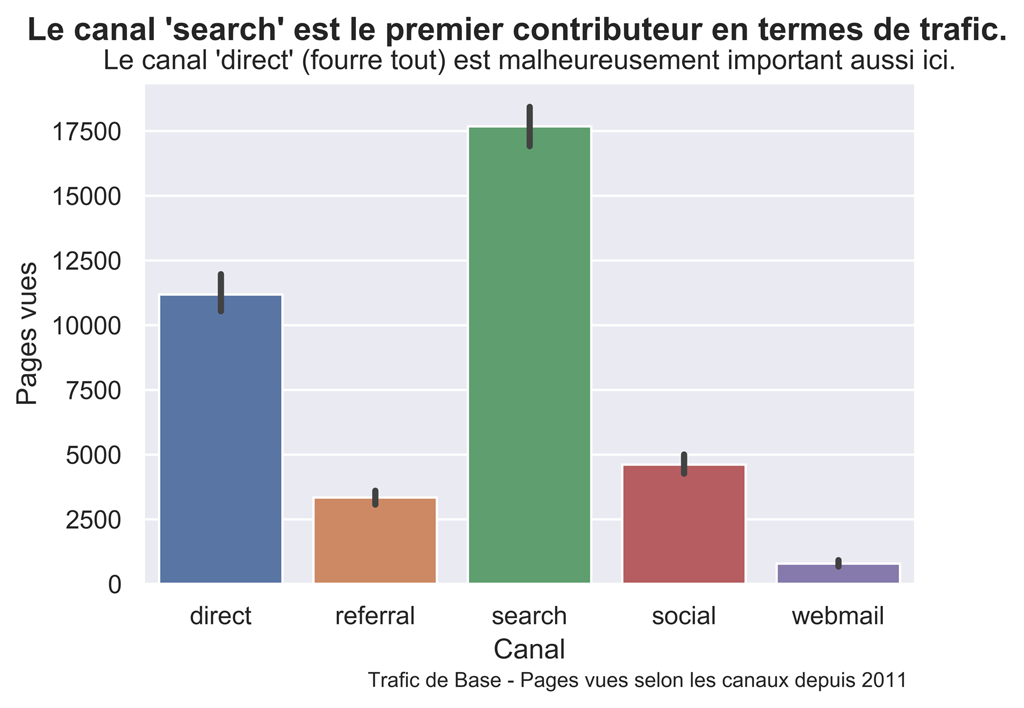
fig.suptitle("Le canal 'search' est le premier contributeur en termes de trafic.", fontsize=14, fontweight='bold')
ax.set(xlabel="Canal", ylabel="Pages vues",
title="Le canal 'direct' (fourre tout) est malheureusement important aussi ici.")
fig.text(.35,-.03,"Trafic de Base - Pages vues selon les canaux depuis 2011", fontsize=9)
#plt.show()
fig.savefig("Base-PV-Channel-bar.png", bbox_inches="tight", dpi=600)
trafic de base par annees
##########################################################################
#Graphique en barre par année
#Répartition du trafic selon les canaux.
##########################################################################
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
g=sns.FacetGrid(dateChannel_baseData, col="Année", col_wrap=3)
g.map(sns.barplot, 'channel', 'pageviews', palette="deep", estimator=sum, order=sorted(dfBasePVChannel['channel'].unique()))
plt.subplots_adjust(top=0.9)
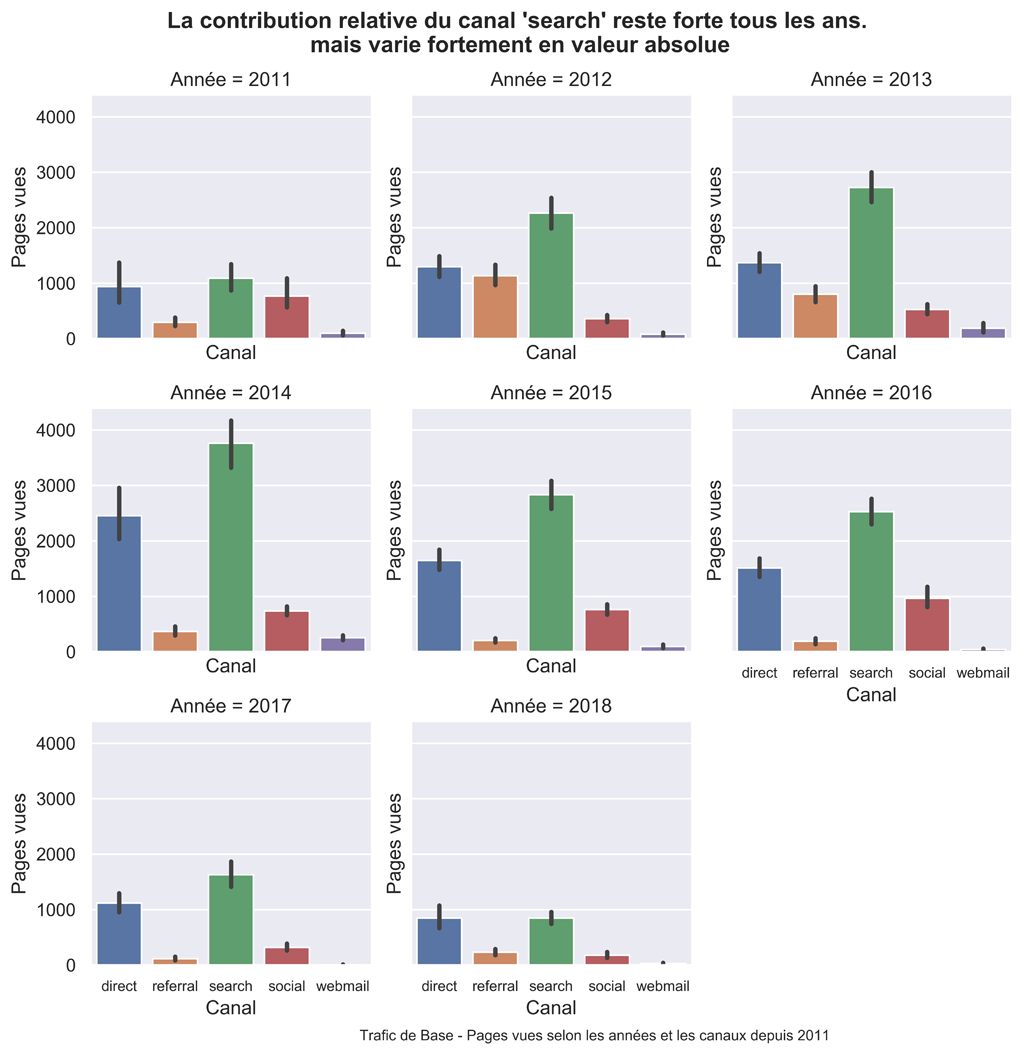
g.fig.suptitle("La contribution relative du canal 'search' reste forte tous les ans.\n mais varie fortement en valeur absolue", fontsize=14, fontweight='bold')
g.set(xlabel="Canal", ylabel="Pages vues")
g.set_xticklabels(fontsize=9)
g.fig.text(.35,-.00,"Trafic de Base - Pages vues selon les années et les canaux depuis 2011", fontsize=9)
#plt.show()
g.savefig("Base-PV-Channel-bar-an.png", bbox_inches="tight", dpi=600)
EVOLUTION DU TRAFIC DE BASE SELON LES CANAUX
###################################################################################
###### Avec Plotline
p = (ggplot(dateChannel_baseData) +
stat_smooth(aes('date', 'pageviews', color='channel'), method='loess', span=0.4) +
ylab("Pages vues") +
scale_x_datetime(breaks=date_breaks('2 years')) + # new
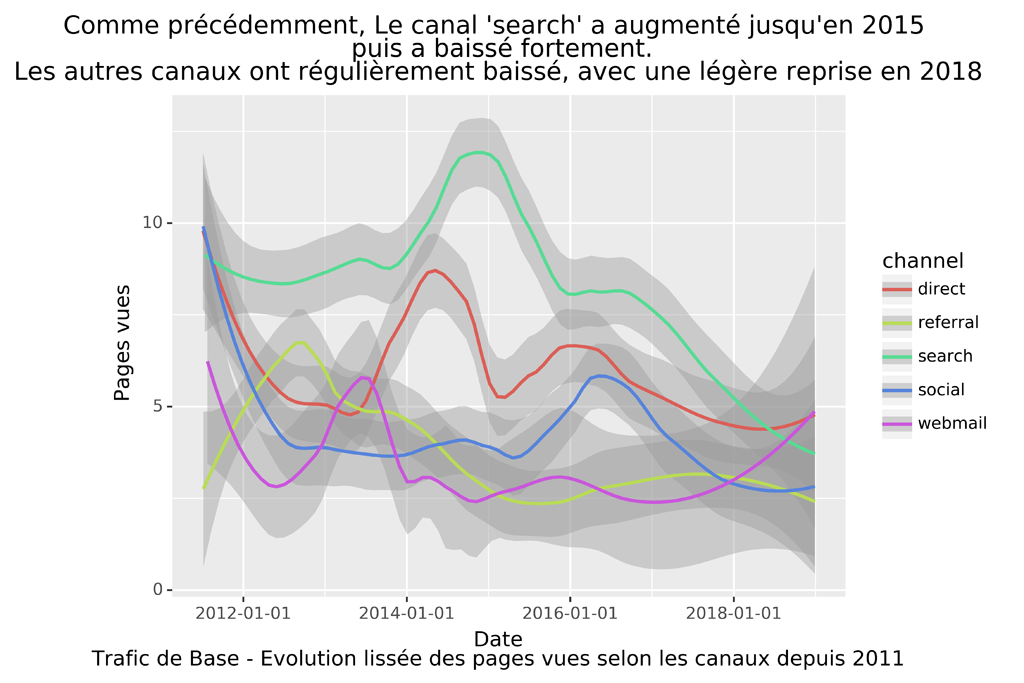
ggtitle("Comme précédemment, Le canal 'search' a augmenté jusqu'en 2015 \n puis a baissé fortement.\nLes autres canaux ont régulièrement baissé, avec une légère reprise en 2018") +
xlab("Date\nTrafic de Base - Evolution lissée des pages vues selon les canaux depuis 2011")
)
p.save("Base-PV-Channel-smooth.png", bbox_inches="tight", dpi=600)
Analyse du trafic Direct Marketing
Nous nous concentrons ici sur ce que l’on a appelé le trafic « Direct
Marketing » : il s’agit du trafic dont le point d’entrée est un page « Article Marketing ».
##########################################################################
#regardons pour le trafic Direct Marketing uniquement i.e le traffic dont
# la source a dirigé vers une page Articles Marketing
##########################################################################
#Relecture ############
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
dfDMPageViews = pd.read_csv("dfDMPageViews.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
dfDMPageViews.dtypes
dfDMPageViews.count() #28553
dfDMPageViews.head(20)
#On vire les blancs pour faire le merge on
dfDMPageViews['source'] = dfDMPageViews['source'].str.strip()
mySourcesChannel['source'] = mySourcesChannel['source'].str.strip()
#recuperation de la variable channel dans la dataframe principale par un left join.
dfDMPVChannel = pd.merge(dfDMPageViews, mySourcesChannel, on='source', how='left')
dfDMPVChannel.info()
#voyons ce que l'on a comme valeurs.
dfDMPVChannel['channel'].value_counts()
sorted(dfDMPVChannel['channel'].unique())
#creation de la dataframe dateChannel_DMData par jour et canal
dfDateDMPVChannel = dfDMPVChannel[['date', 'channel', 'pageviews']].copy() #nouveau dataframe avec que la date et les canaux
dfDateDMPVChannel.info()
dateChannel_DMData = dfDateDMPVChannel.groupby(['date', 'channel']).count() #
#dans l'opération précédente la date et le channel sont partis dans l'index
dateChannel_DMData = dateChannel_DMData.reset_index() #recrée les colonnes date et channel
dateChannel_DMData['Année'] = dateChannel_DMData['date'].astype(str).str[:4] #ajoute l'année
dateChannel_DMData.info()
dateChannel_DMData.sort_values(by=['date', 'channel'])
dateChannel_DMData.head(20)
Graphique ARTICLES DIRECT MARKETING dePUIS 2011
##########################################################################
# Graphique en barre général Répartition du trafic selon
#les canaux pour le trafic Direct Marketing
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.barplot(x='channel', y='pageviews', data=dateChannel_DMData, estimator=sum, order=sorted(dfDMPVChannel['channel'].unique()))
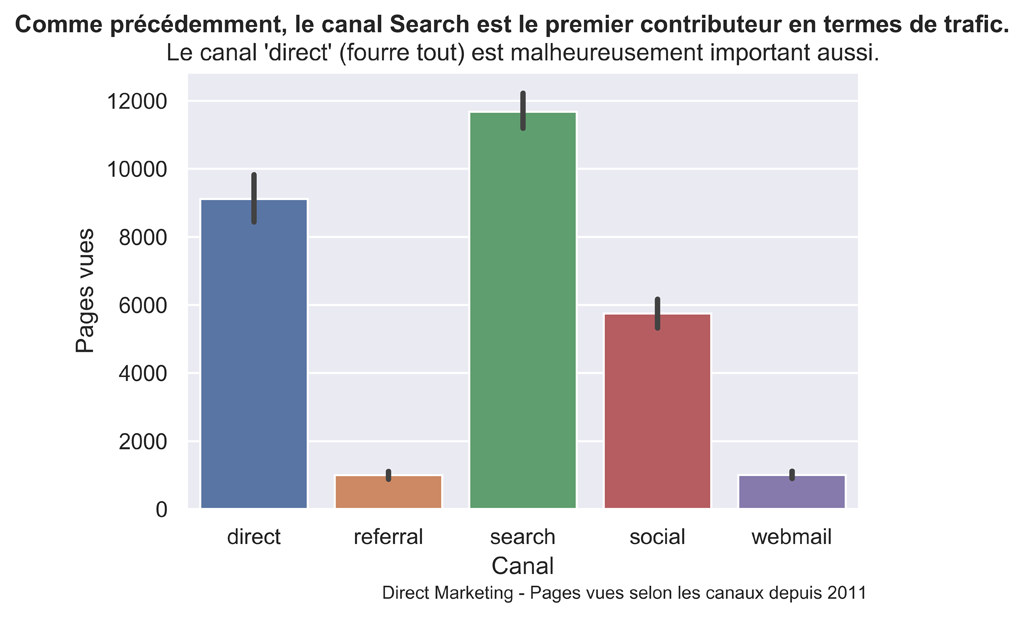
fig.suptitle("Comme précédemment, le canal Search est le premier contributeur en termes de trafic.", fontsize=12, fontweight='bold')
ax.set(xlabel="Canal", ylabel="Pages vues",
title="Le canal 'direct' (fourre tout) est malheureusement important aussi.")
fig.text(.35,-.03,"Direct Marketing - Pages vues selon les canaux depuis 2011", fontsize=9)
#plt.show()
fig.savefig("DM-PV-Channel-bar.png", bbox_inches="tight", dpi=600)
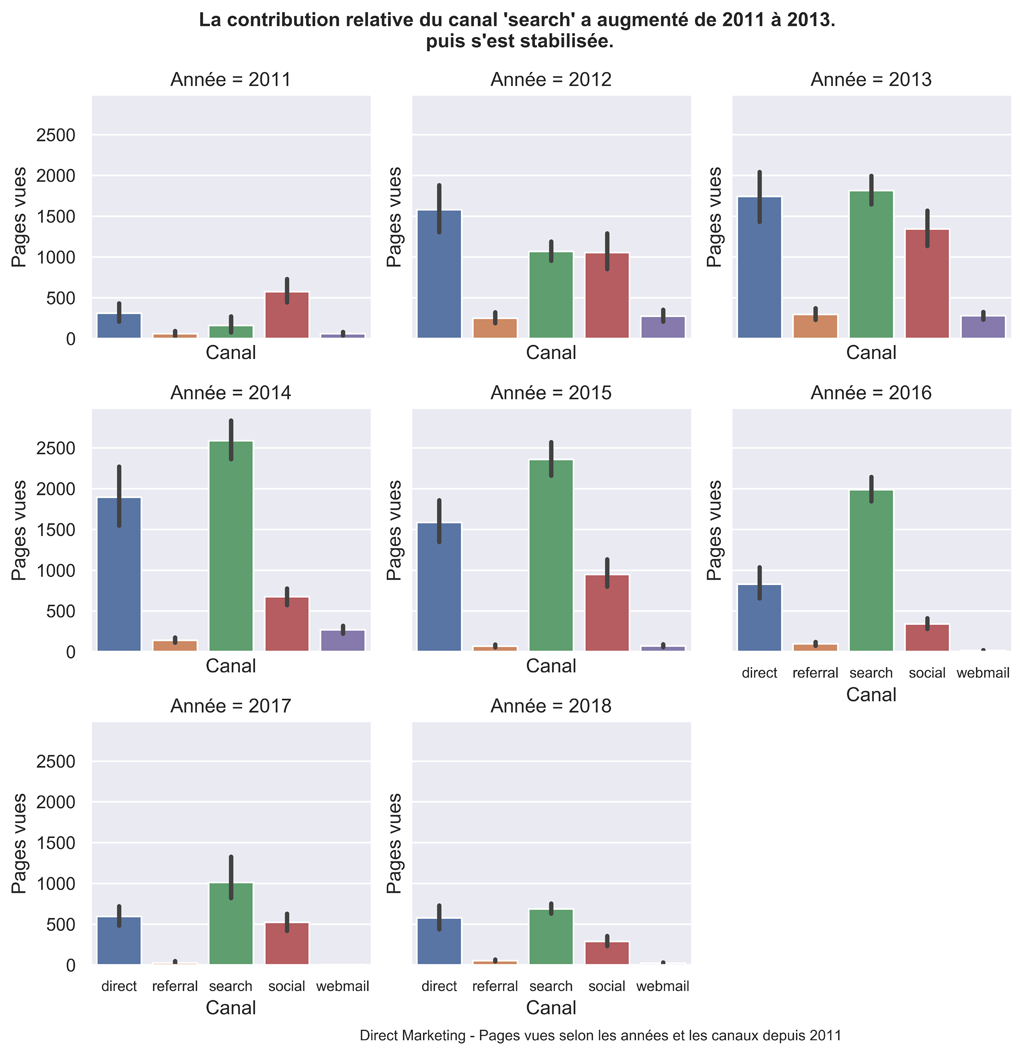
Graphique ARTICLES DIRECT MARKETING PAR ANS
##########################################################################
#Graphique en barre par année
#Répartition du trafic direct marketing selon les sources.
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
g=sns.FacetGrid(dateChannel_DMData, col="Année", col_wrap=3)
g.map(sns.barplot, 'channel', 'pageviews', palette="deep", estimator=sum, order=sorted(dfDMPVChannel['channel'].unique()))
plt.subplots_adjust(top=0.9)
g.fig.suptitle("La contribution relative du canal 'search' a augmenté de 2011 à 2013.\n puis s'est stabilisée.", fontsize=12, fontweight='bold')
g.set(xlabel="Canal", ylabel="Pages vues")
g.set_xticklabels(fontsize=9)
g.fig.text(.35,-.00,"Direct Marketing - Pages vues selon les années et les canaux depuis 2011", fontsize=9)
#plt.show()
g.savefig("DM-PV-Channel-bar-an.png", bbox_inches="tight", dpi=600)
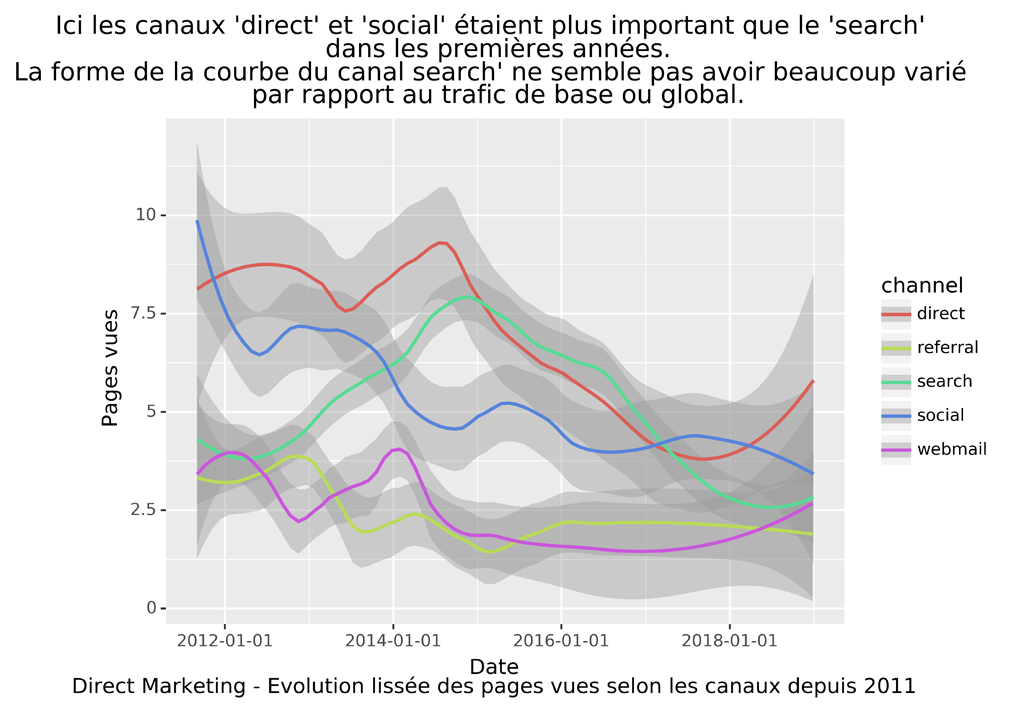
GRAPHIQUE EVOLUTION DU TRAFIC DIRECT MARKETING SELON LES CANAUX DEPUIS 2011
###################################################################################
###### Avec Plotline
#evolution des pages vues selon les canaux pour le trafic direct marketing
p = (ggplot(dateChannel_DMData) +
stat_smooth(aes('date', 'pageviews', color='channel'), method='loess', span=0.4) +
ylab("Pages vues") +
scale_x_datetime(breaks=date_breaks('2 years')) + # new
ggtitle("Ici les canaux 'direct' et 'social' étaient plus important que le 'search' \n dans les premières années.\nLa forme de la courbe du canal search' ne semble pas avoir beaucoup varié \n par rapport au trafic de base ou global.") +
xlab("Date\nDirect Marketing - Evolution lissée des pages vues selon les canaux depuis 2011")
)
p.save("DM-PV-Channel-smooth.png", bbox_inches="tight", dpi=600)
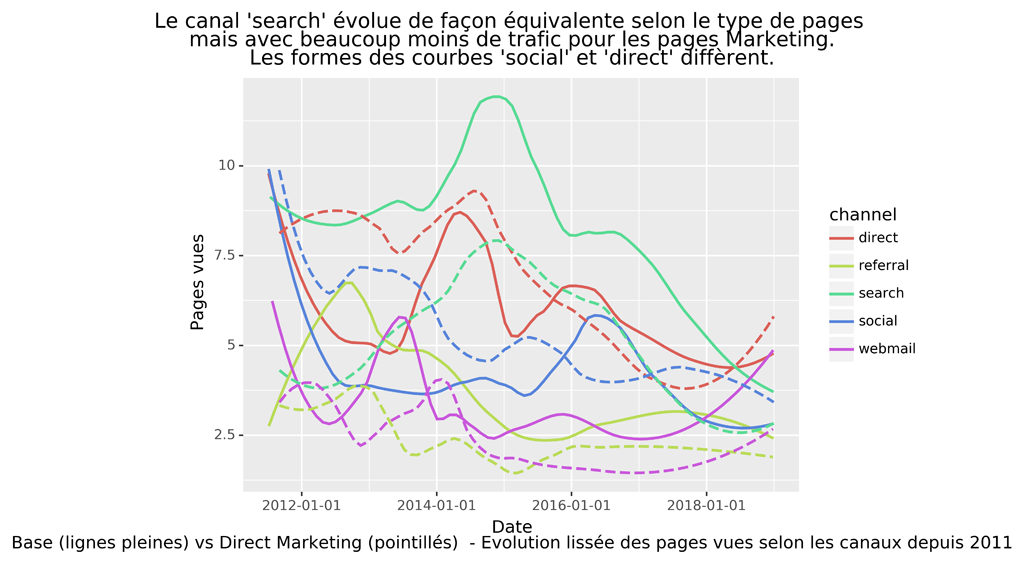
Comparatif trafic de base vs trafic Direct Marketing
EVOLUTION DANS LE TEMPS
##########################################################################
# Comparatif DM vs Base
#evolution des pages vues selon les canaux pour le trafic direct marketing vs Base
############################################################################
p = (ggplot() +
stat_smooth(aes('date', 'pageviews', color='channel'), data=dateChannel_baseData, method='loess', span=0.4, se = False) +
stat_smooth(aes('date', 'pageviews', color='channel'), data=dateChannel_DMData, method='loess', span=0.4, se = False, linetype='dashed') +
ylab("Pages vues") +
scale_x_datetime(breaks=date_breaks('2 years')) + # new
ggtitle("Le canal 'search' évolue de façon équivalente selon le type de pages \n mais avec beaucoup moins de trafic pour les pages Marketing. \nLes formes des courbes 'social' et 'direct' diffèrent.") +
xlab("Date\nBase (lignes pleines) vs Direct Marketing (pointillés) - Evolution lissée des pages vues selon les canaux depuis 2011")
)
p.save("Base-DM-PV-Channel-smooth.png", bbox_inches="tight", dpi=600)
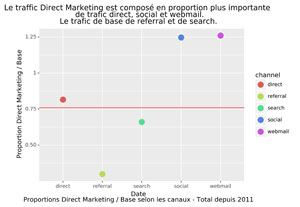
Graphique des CANAUX EN PROPOrTION Direct MArketing / Base
#Comparatif des proportions
#proportions des différents trafics
propDMBase = len(dfDMPVChannel.index) / len(dfBasePVChannel.index) #0.76
myPropDMBase = pd.DataFrame(data={'channel' : ["direct", "referral", "search", "social", "webmail"],
'proportion' : [0,0,0,0,0]})
myPropDMBase.loc[0, "proportion"] = sum(dfDMPVChannel.channel=="direct") / sum(dfBasePVChannel.channel=="direct") #0.81
myPropDMBase.loc[1, "proportion"] = sum(dfDMPVChannel.channel=="referral") / sum(dfBasePVChannel.channel=="referral") #0.29
myPropDMBase.loc[2, "proportion"] = sum(dfDMPVChannel.channel=="search") / sum(dfBasePVChannel.channel=="search") #0.66
myPropDMBase.loc[3, "proportion"] = sum(dfDMPVChannel.channel=="social") / sum(dfBasePVChannel.channel=="social") #1.25
myPropDMBase.loc[4, "proportion"] = sum(dfDMPVChannel.channel=="webmail") / sum(dfBasePVChannel.channel=="webmail") #1.26
p = (ggplot(myPropDMBase) +
geom_point(aes('channel', 'proportion', color='channel'), size=5) +
geom_hline(yintercept = propDMBase, color= "red" ) +
ylab("Proportion Direct Marketing / Base") +
ggtitle("Le traffic Direct Marketing est composé en proportion plus importante \n de trafic direct, social et webmail.\nLe trafic de base de referral et de search.") +
xlab("Date\nProportions Direct Marketing / Base selon les canaux - Total depuis 2011")
)
p.save("Base-DM-PV-Channel-prop.png", bbox_inches="tight", dpi=600)
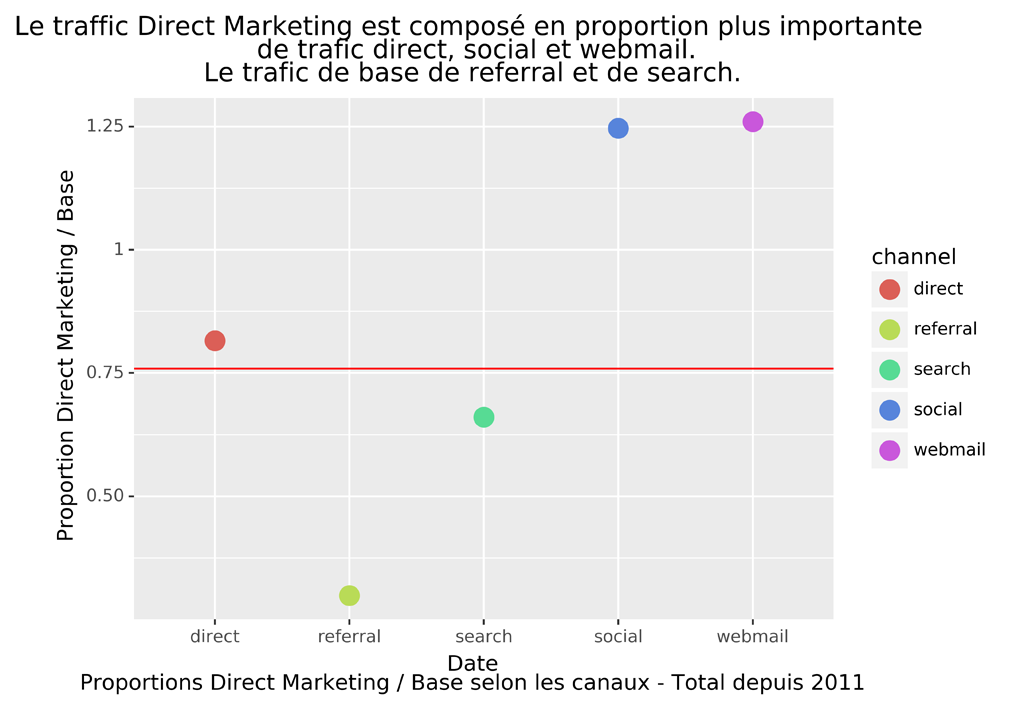
Dans notre cas, le trafic « Referral » concerne surtout les pages de base, tandis que le trafic « Social » et « Webmail » les pages articles.
Pour finir, vérifions la significativité des proportions. On utilisera la fonction proportions_ztest de la bibliothèque stats de Python.
#verification que les proportions sont statistiquement valides.
from statsmodels.stats.proportion import proportions_ztest
#trafic direct
#H0 prop direct/total DM <= direct/total base,
#H1 : prop direct/total DM > direct/total base, (p.value << 0.05)
#2-sample test
myNobs = np.array([sum(dfBasePVChannel.channel=="direct"), len(dfBasePVChannel.index)])
myCount = np.array([sum(dfDMPVChannel.channel=="direct"), len(dfDMPVChannel.index) ])
stat, pval = proportions_ztest(nobs=myNobs, count=myCount, alternative='larger')
pval #4.224315160144362e-36 <<<< 0.05
print('{0:0.3f}'.format(pval)) #0.000
#trafic referral
#H0 prop referral/total DM >= referral/total base,
#H1 : prop referral/total DM < referral/total base, (p.value << 0.05)
#2-sample test
myNobs = np.array([sum(dfBasePVChannel.channel=="referral"), len(dfBasePVChannel.index)])
myCount = np.array([sum(dfDMPVChannel.channel=="referral"), len(dfDMPVChannel.index) ])
stat, pval = proportions_ztest(nobs=myNobs, count=myCount, alternative='smaller')
pval #0.0 <<<< 0.05
print('{0:0.3f}'.format(pval)) #0.000
#trafic search
#H0 prop search/total DM >= search/total base ,
#H1 : prop search/total DM < search/total base (p.value << 0.05)
myNobs = np.array([sum(dfBasePVChannel.channel=="search"), len(dfBasePVChannel.index)])
myCount = np.array([sum(dfDMPVChannel.channel=="search"), len(dfDMPVChannel.index) ])
stat, pval = proportions_ztest(nobs=myNobs, count=myCount, alternative='smaller')
pval #4.2016829773306624e-130 <<<< 0.05
print('{0:0.3f}'.format(pval)) #0.000
#trafic social
#H0 prop social/total DM <= social/total base,
#H1 : prop social/total DM > social/total base, (p.value << 0.05)
myNobs = np.array([sum(dfBasePVChannel.channel=="social"), len(dfBasePVChannel.index)])
myCount = np.array([sum(dfDMPVChannel.channel=="social"), len(dfDMPVChannel.index) ])
stat, pval = proportions_ztest(nobs=myNobs, count=myCount, alternative='larger')
pval #0.0 <<<< 0.05
print('{0:0.3f}'.format(pval)) #0.000
#trafic webmail
#H0 prop webmail/total DM <= webmail/total base,
#H1 : prop webmail/total DM > webmail/total base, (p.value << 0.05)
myNobs = np.array([sum(dfBasePVChannel.channel=="webmail"), len(dfBasePVChannel.index)])
myCount = np.array([sum(dfDMPVChannel.channel=="webmail"), len(dfDMPVChannel.index) ])
stat, pval = proportions_ztest(nobs=myNobs, count=myCount, alternative='larger')
pval #3.999732720551773e-242 <<<< 0.05
print('{0:0.3f}'.format(pval)) #0.000
#on sauvegarde si besoin
dfDMPVChannel.to_csv("dfDMPVChannel.csv", sep=";", index=False)
##########################################################################
# MERCI pour votre attention !
##########################################################################
#on reste dans l'IDE
#if __name__ == '__main__':
# main()
Pour finir cette série d’articles sur des données de trafic provenant de Google Analytics, nous ferons une Analyse en Composantes Principales sur les canaux, dans un prochain article.
A bientôt,
Pierre