Partager la publication "Analyse en Composantes Principales sur les canaux de trafic Web avec Python"
Cet article reprend plus ou moins le même thème que notre article précédent : Analyse en Composantes Principales sur les canaux de trafic Web avec R, cette fois avec Python.
N’hésitez pas à vous reporter à cet article précédent, pour plus de détail concernant le concept d’Analyse en Composantes Principales.
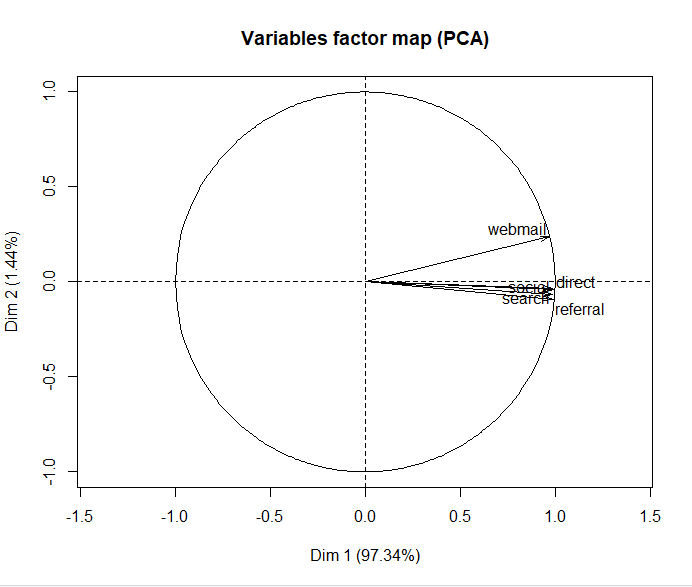
Dans notre cas, nous allons surtout utiliser cette analyse pour vérifier la corrélation entre les canaux de trafic sur notre site. Par exemple sur un graphique de ce type :
Rappelons les canaux que nous avons identifiés :
- Search – moteurs de recherche : Google, Bing, Qwant..
- Social – réseaux sociaux : FaceBook, Twitter, Instagram…
- Referral – liens sur d’autres sites
- Webmail – liens cliqués dans un email sur un webmail
- Direct – toutes les autres sources (non spécifiées par Google Analytics)
Comme nous l’avions indiqué aussi pour R, cet article est le dernier d’une série sur l’analyse de données provenant de Google Analytics concernant le site de l’association Networking Morbihan.
Comment allons nous procéder ?
Python Anaconda
Téléchargez la version de Python Anaconda qui vous convient selon votre ordinateur. Python Anaconda est une version de Python 3.xx adaptée aux Sciences de données.
Jeu de données
Vous pouvez; soit récupérer les jeux de données provenant de l’association Networking Morbihan sur notre Github :
- Toutes les pages vues
- Pages vues de base
- Pages Vues « Direct Marketing »
- Canaux en fonction des sources
Remarque : Dézippez les archives dans le même répertoire que votre code source
Soit créer un jeu de données à partir de vos données Google Analytics, en suivant la procédure décrite dans nos articles précédents :
- Importer les données de Google Analytics API avec Python Anaconda.
- Nettoyage du Spam dans Google Analytics avec Python.
- Détection du trafic Web significatif avec Python.
- Publication d’articles vs événements significatifs en Python.
- Quelle est la durée de vie de mes articles sur mon site ? Python.
- Analyse du trafic selon les canaux avec Python
Code Source :
Vous pouvez récupérer les différents morceaux de code ci-dessous ou récupérer tout le code gratuitement dans notre boutique à l’adresse : https://www.anakeyn.com/boutique/produit/scipt-python-acp-canaux-web/
Récupération des bibliothèques utiles :
######################################################################### # PCATrafficChannelsPython # Analyse en Composantes Principalkes du trafic selon les canaux # Auteur : Pierre Rouarch 2019 - Licence GPL 3 # Données : Issues de l'API de Google Analytics - # Comme illustration Nous allons travailler sur les données du site # https://www.networking-morbihan.com ############################################################# # On démarre ici pour récupérer les bibliothèques utiles !! ############################################################# #def main(): #on ne va pas utiliser le main car on reste dans Spyder #Chargement des bibliothèques utiles (décommenter au besoin) import numpy as np #pour les vecteurs et tableaux notamment import matplotlib.pyplot as plt #pour les graphiques #import scipy as sp #pour l'analyse statistique import pandas as pd #pour les Dataframes ou tableaux de données import seaborn as sns #graphiques étendues #import math #notamment pour sqrt() #from datetime import timedelta #from scipy import stats #pip install scikit-misc #pas d'install conda ??? from skmisc import loess #pour methode Loess compatible avec stat_smooth #conda install -c conda-forge plotnine from plotnine import * #pour ggplot like #conda install -c conda-forge mizani from mizani.breaks import date_breaks #pour personnaliser les dates affichées from sklearn.decomposition import PCA #pour pca from sklearn.preprocessing import StandardScaler #pour standardization #Si besoin Changement du répertoire par défaut pour mettre les fichiers de sauvegarde #dans le même répertoire que le script. import os print(os.getcwd()) #verif #mon répertoire sur ma machine - nécessaire quand on fait tourner le programme #par morceaux dans Spyder. #myPath = "C:/Users/Pierre/CHEMIN" #os.chdir(myPath) #modification du path #print(os.getcwd()) #verif
Pour les données Globales
Récupération des données et preparation pour l’ACP
############################################################
# TRAFIC GLOBAL RECUPERATION DES DONNEES
############################################################
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
dfPageViews = pd.read_csv("dfPageViews.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
dfPageViews.info() #72821 enregistrements
#Recupération des sources
mySourcesChannel = pd.read_csv("mySourcesChannel.csv", sep=";")
mySourcesChannel.info()
dfPageViews.info()
#On vire les blancs pour faire le merge on
dfPageViews['source'] = dfPageViews['source'].str.strip()
mySourcesChannel['source'] = mySourcesChannel['source'].str.strip()
dfPVChannel = pd.merge(dfPageViews, mySourcesChannel, on='source', how='left')
dfPVChannel.info()
#voyons ce que l'on a comme valeurs.
dfPVChannel['channel'].value_counts()
sorted(dfPVChannel['channel'].unique())
############################################################################
# #Préparation des données pour l'ACP
############################################################################
#creation de la dataframe PVDataForACP
PVDataForACP = dfPVChannel[['pagePath', 'channel', 'pageviews']].copy() #nouveau dataframe avec que la date et les canaux
PVDataForACP.info()
PVDataForACP = PVDataForACP.groupby(['pagePath','channel']).count()
#
PVDataForACP.reset_index(inplace=True)
PVDataForACP.info()
#création d'une colonne par type de channel
PVDataForACP = PVDataForACP.pivot(index='pagePath',columns='channel',values='pageviews')
#Mettre des 0 à la place de NaN
PVDataForACP .fillna(0,inplace=True)
PVDataForACP.to_csv("PVDataForACP.csv", sep=";", index=False) #on sauvegarde si besoin
PVDataForACP.info() #description des données
PVDataForACP.describe() #résumé des données
Calcul de l’ACP pour les données Globales
##########################################################################
# ACP - Analyse en Composantes Principales pour le
# trafic Global - Chaque observation est une page
##########################################################################
X=PVDataForACP.values #uniquement les valeurs dans une matrice.
scaler = StandardScaler() #instancie un objet StandardScaler
scaler.fit(X) #appliqué aux données
X_scaled = scaler.fit_transform(X) #données transformées
pca = PCA(n_components=5) #instancie un objet PCA
pca.fit(X_scaled) #appliqué aux données scaled
pca.components_.T
pca.explained_variance_
pca.explained_variance_ratio_ #en pourcentage
pca.explained_variance_ratio_[0]
#Préparation des données pour affichage
dfpca = pd.DataFrame(data = pca.explained_variance_ratio_
, columns = ['Variance Expliquée'])
dfpca.index.name = 'Composantes'
dfpca.reset_index(inplace=True)
dfpca['Composantes'] +=1
Screeplot : pourcentage de variance expliquée pour les données globales
#Graphique Screeplot
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.barplot(x='Composantes', y= 'Variance Expliquée', data=dfpca )
ax.set(xlabel='Composantes', ylabel='% Variance Expliquée',
title="La première composante comprend " + "{0:.2f}%".format(pca.explained_variance_ratio_[0]*100) + "de l'information")
fig.text(.9,-.05,"Screeplot du % de variance des composantes de l'ACP Normalisée \n Corrélation de Pearson pour les canaux - toutes les pages", fontsize=9, ha="right")
#plt.show()
fig.savefig("All-PCA-StandardScaler-Pearson-screeplot-channel.png", bbox_inches="tight", dpi=600)
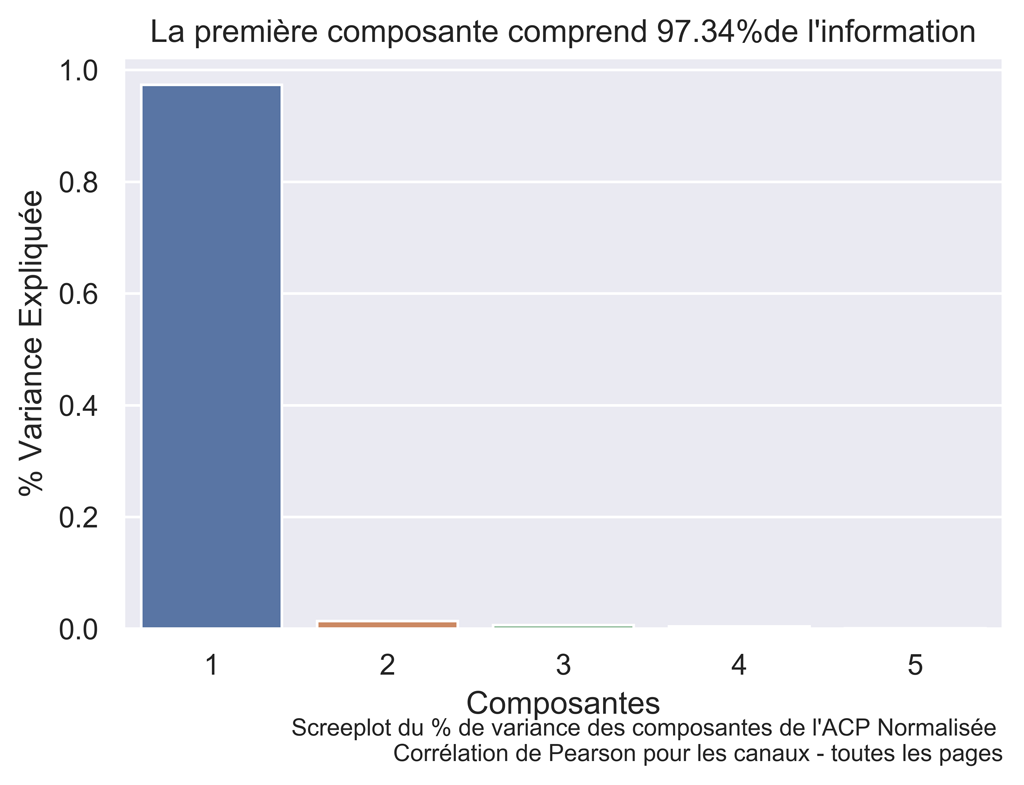
Quasiment toute l’information est contenue dans la composante 1
Diagramme DES INDIVIDUS ET des variables pour toutes les pages :
Cette fois, nous faisons aussi apparaître les individus même si cela n’est pas vraiment l’information que l’on recherche.
##############
##nuage des individus et axes des variables
labels=PVDataForACP.columns.values
score= X_scaled[:,0:2]
coeff=np.transpose(pca.components_[0:2, :])
n = coeff.shape[0]
xs = score[:,0]
ys = score[:,1]
#
scalex = 1.0/(xs.max() - xs.min())
scaley = 1.0/(ys.max() - ys.min())
#Graphique du nuage des pages et des axes des variables.
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.scatterplot(xs * scalex,ys * scaley, alpha=0.4) #
for i in range(n):
ax.arrow(0, 0, coeff[i,0]*1, coeff[i,1]*1,color = 'r',alpha = 0.5, head_width=.03)
ax.text(coeff[i,0]*1.15, coeff[i,1]*1.15 , labels[i], color = 'r', ha = 'center', va = 'center')
ax.set(xlabel='Composante 1', ylabel='Composante 2',
title="Les variables sont toutes du même bord de l'axe principal 1 \n Sur l'axe 2 seul Webmail se détache")
ax.set_ylim((-0.7, 1.1))
fig.text(.9,-.05,"Nuage des pages et axes des variables Normalisées via StandardScaler \n Corrélation de Pearson pour les canaux - toutes les pages", fontsize=9, ha="right")
#plt.show()
fig.savefig("All-PCA-StandardScaler-Pearson-cloud-channel.png", bbox_inches="tight", dpi=600)
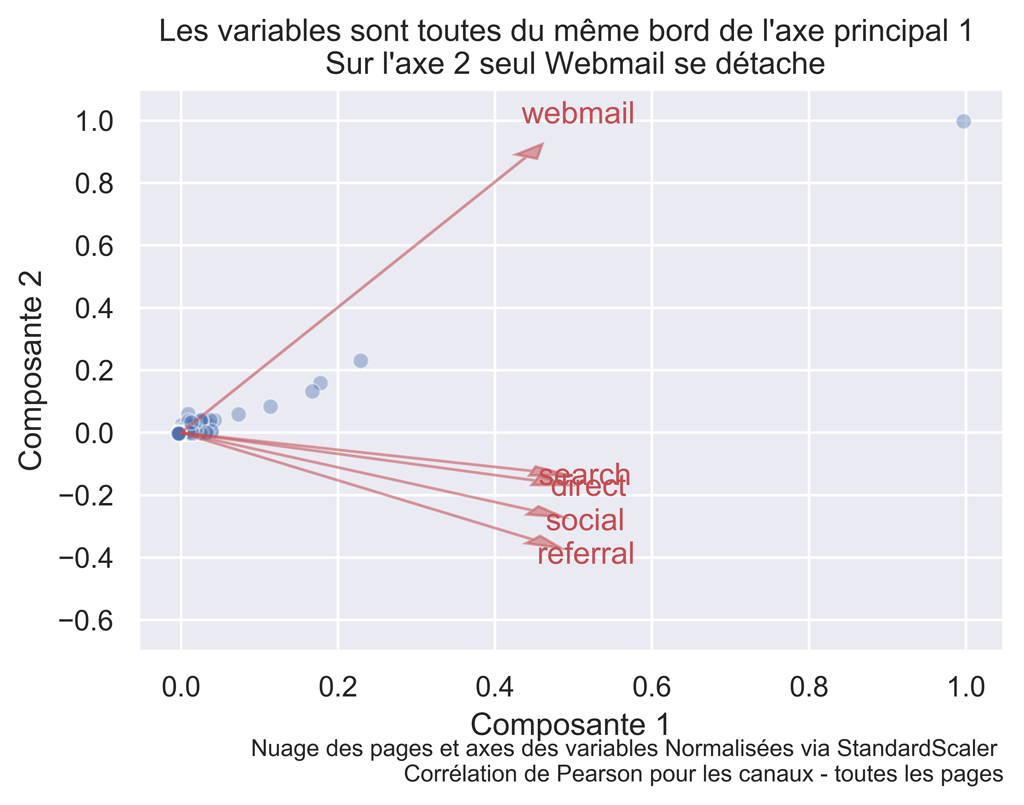
Toutes les variables sont dans l’axe de la composante 1. Compte tenu du fait que celle-ci comporte pratiquement toute l’information le fait que webmail se détache n’est pas si significatif que cela, la composante 2 ne comportant que 2% de l’information. Il y a ici un effet grossissant pour la composante 2.
Pages de base :
Rappel : les pages de bases sont surtout les pages « statiques » du site : page d’accueil, les adhérents, s’inscrire etc.
Récupération des données DES PAGES DE BASE et preparation pour l’ACP
##########################################################################
# Pour le traffic de base
##########################################################################
#Relecture ############
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
dfBasePageViews = pd.read_csv("dfBasePageViews.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
dfBasePageViews.dtypes
dfBasePageViews.count() #37615
dfBasePageViews.head(20)
#On vire les blancs pour faire le merge on
dfBasePageViews['source'] = dfBasePageViews['source'].str.strip()
mySourcesChannel['source'] = mySourcesChannel['source'].str.strip()
#récuperation de la variable channel dans la dataframe principale par un left join.
dfBasePVChannel = pd.merge(dfBasePageViews, mySourcesChannel, on='source', how='left')
dfBasePVChannel.info()
#voyons ce que l'on a comme valeurs.
dfBasePVChannel['channel'].value_counts()
sorted(dfBasePVChannel['channel'].unique())
############################################################################
# #Préparation des données pour l'ACP
#creation de la dataframe BasePVDataForACP
BasePVDataForACP = dfBasePVChannel[['pagePath', 'channel', 'pageviews']].copy() #nouveau dataframe avec que la date et les canaux
BasePVDataForACP.info()
BasePVDataForACP = BasePVDataForACP.groupby(['pagePath','channel']).count()
#
BasePVDataForACP.reset_index(inplace=True)
BasePVDataForACP.info()
#création d'une colonne par type de channel
BasePVDataForACP = BasePVDataForACP.pivot(index='pagePath',columns='channel',values='pageviews')
#Mettre des 0 à la place de NaN
BasePVDataForACP .fillna(0,inplace=True)
BasePVDataForACP.to_csv("BasePVDataForACP.csv", sep=";", index=False) #on sauvegarde si besoin
BasePVDataForACP.info() #description des données
BasePVDataForACP.describe() #résumé des données
Calcul de l’ACP pour les données « de BASE »
##########################################################################
# ACP - Analyse en Composantes Principales pour le
# trafic de base - Chaque observation est une page
##########################################################################
X=BasePVDataForACP.values #uniquement les valeurs dans une matrice.
scaler = StandardScaler() #instancie un objet StandardScaler
X_scaled = scaler.fit_transform(X) #données transformées centrage-réduction
print(X_scaled)
pcaBase = PCA(n_components=5) #instancie un objet PCA
pcaBase.fit(X_scaled) #appliqué aux données scaled
pcaBase.components_.T
pcaBase.explained_variance_
pcaBase.explained_variance_ratio_ #en pourcentage
pcaBase.explained_variance_ratio_[0]
#Préparation des données pour affichage
dfpcaBase = pd.DataFrame(data = pcaBase.explained_variance_ratio_
, columns = ['Variance Expliquée'])
dfpcaBase.index.name = 'Composantes'
dfpcaBase.reset_index(inplace=True)
dfpcaBase['Composantes'] +=1
Screeplot : pourcentage de variance expliquée pour les données de base
#Graphique screeplot données de base.
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.barplot(x='Composantes', y= 'Variance Expliquée', data=dfpcaBase )
#fig.suptitle("La première composante comprend déja " + "{0:.2f}%".format(pca.explained_variance_ratio_[0]*100) + "de l'information", fontsize=10, fontweight='bold')
ax.set(xlabel='Composantes', ylabel='% Variance Expliquée',
title="La première composante comprend " + "{0:.2f}%".format(pcaBase.explained_variance_ratio_[0]*100) + "de l'information")
fig.text(.9,-.05,"Screeplot du % de variance des composantes de l'ACP Normalisée \n Corrélation de Pearson pour les canaux - pages de base", fontsize=9, ha="right")
#plt.show()
fig.savefig("Base-PCA-StandardScaler-Pearson-screeplot-channel.png", bbox_inches="tight", dpi=600)
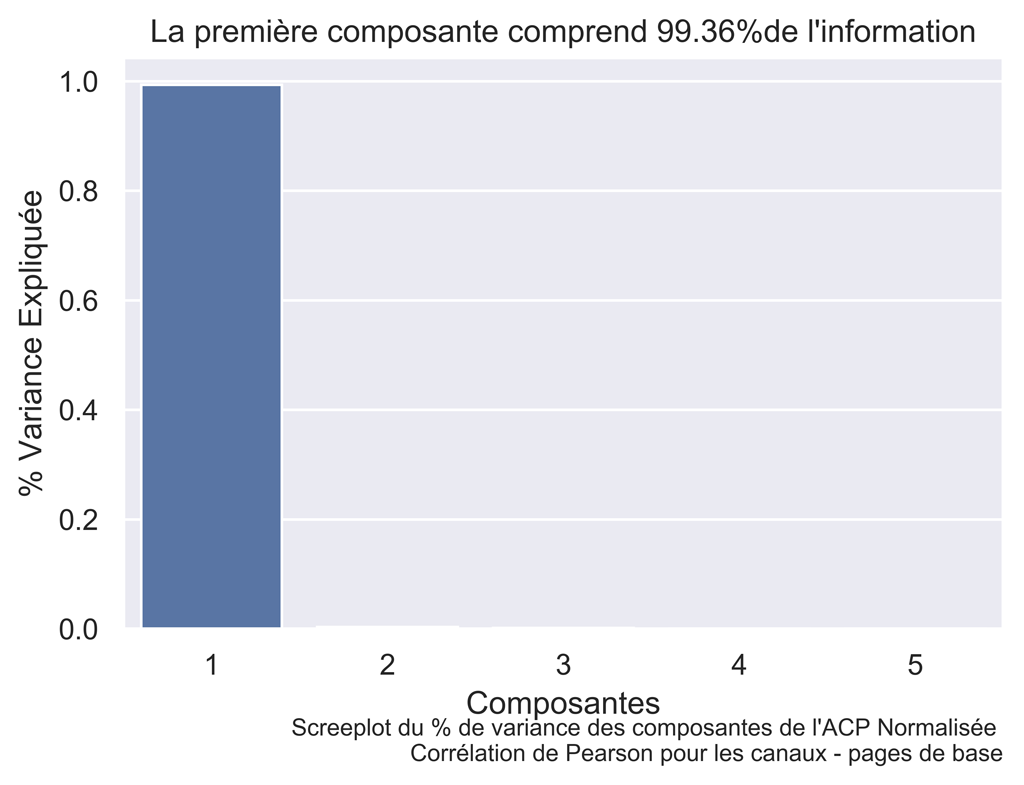
Pratiquement toute l’information : 99,36 % est contenue dans la composante 1.
Diagramme DES INDIVIDUS ET des variables pour les pages de base :
##############
##nuage des individus et axes des variables pages de base
#Labels
labels=BasePVDataForACP.columns.values
score= X_scaled[:,0:2]
coeff=np.transpose(pcaBase.components_[0:2, :])
n = coeff.shape[0]
xs = score[:,0]
ys = score[:,1]
#
scalex = 1.0/(xs.max() - xs.min())
scaley = 1.0/(ys.max() - ys.min())
#Graphique du nuage des pages et des axes des variables.
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.scatterplot(xs * scalex,ys * scaley, alpha=0.4) #
for i in range(n):
ax.arrow(0, 0, coeff[i,0]*1, coeff[i,1]*1,color = 'r',alpha = 0.5, head_width=.03)
ax.text(coeff[i,0]*1.15, coeff[i,1]*1.15 , labels[i], color = 'r', ha = 'center', va = 'center')
ax.set(xlabel='Composante 1', ylabel='Composante 2',
title="Les variables sont toutes du même bord de l'axe principal 1 \n ")
ax.set_ylim((-0.7, 1.1))
fig.text(.9,-.05,"Nuage des pages et axes des variables Normalisées via StandardScaler \n Corrélation de Pearson pour les canaux - pages de bases", fontsize=9, ha="right")
#plt.show()
fig.savefig("Base-PCA-StandardScaler-Pearson-cloud-channel.png", bbox_inches="tight", dpi=600)
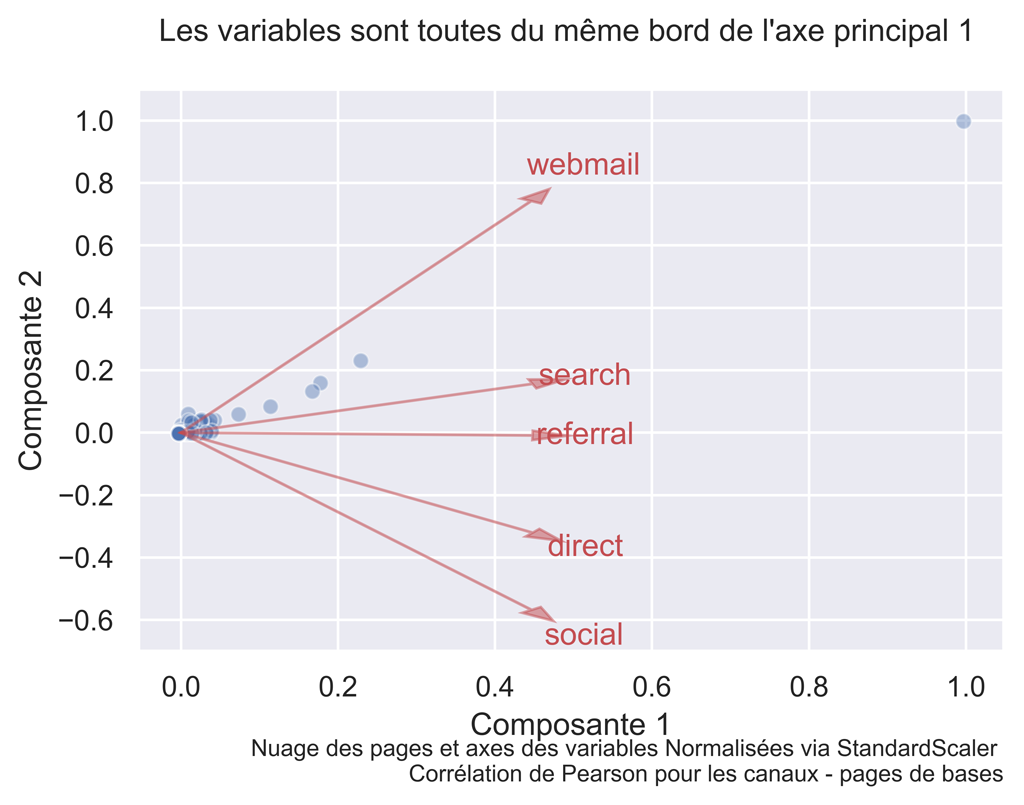
Pages « Direct Marketing » :
Rappel : il s’agit d’articles « marketing » dont la page d’entrée est aussi une page « marketing »
Récupération des données DES PAGES Direct Marketing et preparation pour l’ACP
##########################################################################
#regardons pour le trafic Direct Marketing uniquement i.e le traffic
#Article Maekting avec une page d'entrée Article Marketing
##########################################################################
#Relecture ############
myDateToParse = ['date'] #pour parser la variable date en datetime sinon object
dfDMPageViews = pd.read_csv("dfDMPageViews.csv", sep=";", dtype={'Année':object}, parse_dates=myDateToParse)
#verifs
dfDMPageViews.dtypes
dfDMPageViews.count() #28553
dfDMPageViews.head(20)
#On vire les blancs pour faire le merge on
dfDMPageViews['source'] = dfDMPageViews['source'].str.strip()
mySourcesChannel['source'] = mySourcesChannel['source'].str.strip()
#recuperation de la variable channel dans la dataframe principale par un left join.
dfDMPVChannel = pd.merge(dfDMPageViews, mySourcesChannel, on='source', how='left')
dfDMPVChannel.info()
#voyons ce que l'on a comme valeurs.
dfDMPVChannel['channel'].value_counts()
sorted(dfDMPVChannel['channel'].unique())
#Préparation des données pour l'ACP - Chaque observation est une page
#creation de la dataframe DMPVDataForACP
DMPVDataForACP = dfDMPVChannel[['pagePath', 'channel', 'pageviews']].copy() #nouveau dataframe avec que la date et les canaux
DMPVDataForACP.info()
DMPVDataForACP = DMPVDataForACP.groupby(['pagePath','channel']).count()
#
DMPVDataForACP.reset_index(inplace=True)
DMPVDataForACP.info()
#création d'une colonne par type de channel
DMPVDataForACP = DMPVDataForACP.pivot(index='pagePath',columns='channel',values='pageviews')
#Mettre des 0 à la place de NaN
DMPVDataForACP .fillna(0,inplace=True)
DMPVDataForACP.to_csv("DMPVDataForACP.csv", sep=";", index=False) #on sauvegarde si besoin
DMPVDataForACP.info() #description des données
DMPVDataForACP.describe() #résumé des données
Calcul de l’ACP pour les PAGES DIRECT MARKETING
##########################################################################
# ACP - Analyse en Composantes Principales pour le
# trafic Direct Marketing - Chaque observation est une page
##########################################################################
from sklearn.decomposition import PCA
X=DMPVDataForACP.values #uniquement les valeurs dans une matrice.
from sklearn.preprocessing import StandardScaler #import du module
scaler = StandardScaler() #instancie un objet StandardScaler
scaler.fit(X) #appliqué aux données
X_scaled = scaler.transform(X) #données transformées
pcaDM = PCA(n_components=5) #instancie un objet PCA
pcaDM.fit(X_scaled) #appliqué aux données scaled
pcaDM.components_.T
pcaDM.explained_variance_
pcaDM.explained_variance_ratio_ #en pourcentage
pcaDM.explained_variance_ratio_[0]
#Préparation des données pour affichage
dfpcaDM = pd.DataFrame(data = pcaDM.explained_variance_ratio_
, columns = ['Variance Expliquée'])
dfpcaDM.index.name = 'Composantes'
dfpcaDM.reset_index(inplace=True)
dfpcaDM['Composantes'] +=1
Screeplot : pourcentage de variance expliquée pour les PAGES DIRECT MARKETING
#Graphique screeplot pages direct marketing
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.barplot(x='Composantes', y= 'Variance Expliquée', data=dfpcaDM )
#fig.suptitle("La première composante comprend déja " + "{0:.2f}%".format(pca.explained_variance_ratio_[0]*100) + "de l'information", fontsize=10, fontweight='bold')
ax.set(xlabel='Composantes', ylabel='% Variance Expliquée',
title="La première composante comprend " + "{0:.2f}%".format(pcaDM.explained_variance_ratio_[0]*100) + "de l'information")
fig.text(.9,-.05,"Screeplot du % de variance des composantes de l'ACP Normalisée \n Corrélation de Pearson pour les canaux Direct Marketing", fontsize=9, ha="right")
#plt.show()
fig.savefig("DM-PCA-StandardScaler-Pearson-screeplot-channel.png", bbox_inches="tight", dpi=600)
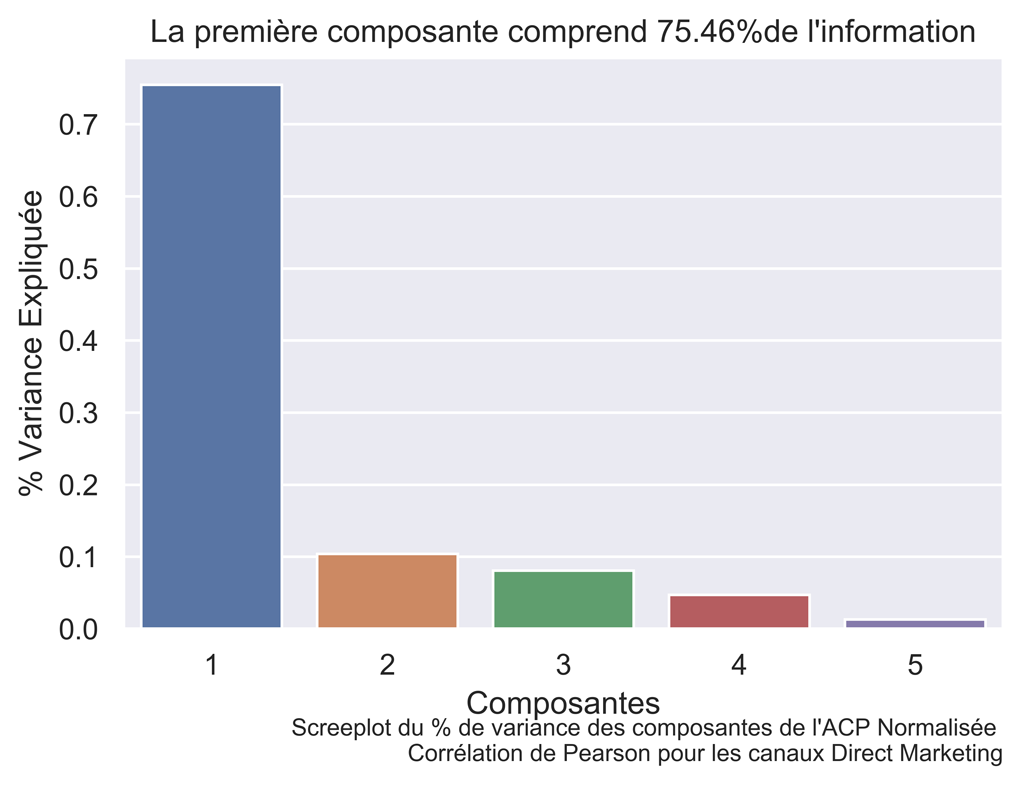
Diagramme DES INDIVIDUS ET des variables pour les pages DIRECT MARKETING :
##############
##nuage des individus et axes des variables pages direct marketing
#Labels
labels=DMPVDataForACP.columns.values
score= X_scaled[:,0:2]
coeff=np.transpose(pcaDM.components_[0:2, :])
n = coeff.shape[0]
xs = score[:,0]
ys = score[:,1]
#
scalex = 1.0/(xs.max() - xs.min())
scaley = 1.0/(ys.max() - ys.min())
#Graphique du nuage des pages et des axes des variables.
sns.set() #paramètres esthétiques ressemble à ggplot par défaut.
fig, ax = plt.subplots() #un seul plot
sns.scatterplot(xs * scalex,ys * scaley, alpha=0.4) #
for i in range(n):
ax.arrow(0, 0, coeff[i,0]*1, coeff[i,1]*1,color = 'r',alpha = 0.5, head_width=.03)
ax.text(coeff[i,0]*1.15, coeff[i,1]*1.15 , labels[i], color = 'r', ha = 'center', va = 'center')
ax.set(xlabel='Composante 1', ylabel='Composante 2',
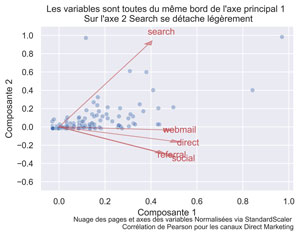
title="Les variables sont toutes du même bord de l'axe principal 1 \n Sur l'axe 2 Search se détache légèrement")
ax.set_ylim((-0.7, 1.1))
fig.text(.9,-.05,"Nuage des pages et axes des variables Normalisées via StandardScaler \n Corrélation de Pearson pour les canaux Direct Marketing", fontsize=9, ha="right")
#plt.show()
fig.savefig("DM-PCA-StandardScaler-Pearson-cloud-channel.png", bbox_inches="tight", dpi=600)
##########################################################################
# MERCI pour votre attention !
##########################################################################
#on reste dans l'IDE
#if __name__ == '__main__':
# main()
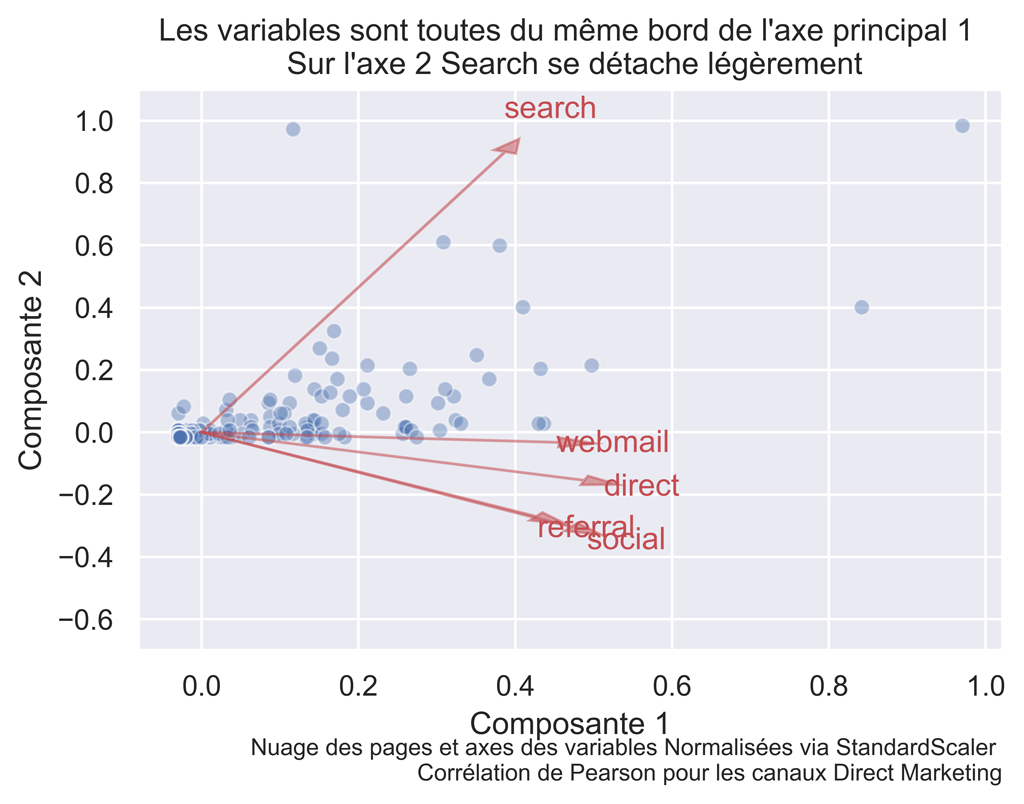
Search se détache légèrement sur l’axe 2 mais comme celui-ci ne comporte que 10% de l’information, ce n’est pas non plus trop significatif.
Au final on a montré que dans tous les cas, tous les canaux sont corrélés entre eux.
Ce que l’on attendait intuitivement, mais c’est mieux en le démontrant :-).
Et vous qu’avez-vous constaté avec vos données ?
A bientôt,
Pierre
Djouamaa Hocine
13 décembre 2019 at 10 h 00 mincan i use this to analysis other data like stocks.
Pierre • Post Author •
16 décembre 2019 at 17 h 24 minWhy not, I don’t know what your want to do. Please let me know more.
Pierre